
MySQL聯合索引原理解析
阿新 • • 發佈:2018-12-13
什麼是MySQL聯合索引
聯合索引又叫複合索引,是MySQL的InnoDB引擎中的一個索引方式,如果一個系統頻繁地使用相同的幾個欄位查詢結果,就可以考慮建立這幾個欄位的聯合索引來提高查詢效率。
如何建立索引
舉個例子:
create table `table_name`( `id` bigint(20) NOT NULL PRIMARY KEY, `a` int(11), `b` int(11), `c` varchar(22), KEY `key_a_b_c` (`a`,`b`,`c`) )ENGINE=InnoDB DEFAULT CHARSET=utf8;
如上面的程式碼其中
KEY `key_a_b_c` (`a`,`b`,`c`)
語句就是建立了a,b,c欄位聯合索引的語句。
最左字首原則
在使用聯合索引時要注意有個最左字首原則,最左字首原則就是要考慮查詢的欄位的順序,只有遵守這個原則才能最大地提高查詢的效率,下面我們舉個例子說明最左字首原則。
建立 (a,b,c)的聯合索引
#完全按建立的順序,能走到a,b,c3個欄位的索引,評級:優化最高
SELECT * FROM tz_prod.table_name where a = 1 and b=2 and c = '3';
#換了b和c的順序,MySQL會進行優化,效率和上面的一樣,評級:優化最高 SELECT * FROM tz_prod.table_name where a = 1 and c = '3' and b=2;
#能走到a和b的索引,評級:優化最高
SELECT * FROM tz_prod.table_name where a = 1 and b=2 ;
#能走到a和b的索引,b的範圍查詢不影響優化,評級:優化最高
SELECT * FROM tz_prod.table_name where a = 1 and b<2 ;
#能走到a的索引,評級:優化最高
SELECT * FROM tz_prod.table_name where a = 1;
#能走到a的索引,評級:優化最高 SELECT * FROM tz_prod.table_name order by a ;
#只能走到a的索引走不到c的索引,如果c的離散度高則查詢效率很低,評級:優化差
SELECT * FROM tz_prod.table_name where a = 1 and c = '3';
#能走到a和b的索引走不到c的索引,b的範圍查詢使後面欄位無法走索引,評級:優化差
SELECT * FROM tz_prod.table_name where a = 1 and b<2 and c = '3';
#能走到a的索引,評級:優化最高
SELECT * FROM tz_prod.table_name where a > 1 order by a;
#能走到a的索引,走不到b索引 評級:優化差
SELECT * FROM tz_prod.table_name where a > 1 order by b;
#同上,評級:優化差
SELECT * FROM tz_prod.table_name where a > 1 order by c;
#走不到b和c的索引,最左字首原則必須以建立索引的第一個欄位作為第一個條件,評級:最差
SELECT * FROM tz_prod.table_name where b=2 and c = '3';
聯合索引提高查詢效率的原理
MySQL會為InnoDB的每個表建立聚簇索引,如果表有索引會建立二級索引。聚簇索引以主鍵建立索引,如果沒有主鍵以表中的唯一鍵建立,唯一鍵也沒會以隱式的建立一個自增的列來建立。聚簇索引和二級索引都是一個b+樹,b+樹的特點是資料按一定順序存在葉子節點且每頁資料相連。一般情況下使用索引查詢時,先查詢二級索引的b+樹,查到資料並拿資料中儲存的主鍵回查聚簇索引查到所有資料。下面我們舉個例子來重現這個過程。
以下面表舉例,假設表中已經存了部分資料:
create table `user_info`(
`id` bigint(20) NOT NULL PRIMARY KEY,
`name` varchar(11),
`age` int(11),
`phone` varchar(20),
KEY `key_name_age` (`name`,`age`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
InnoDB建立的聚簇索引和二級索引如下圖
聚簇索引
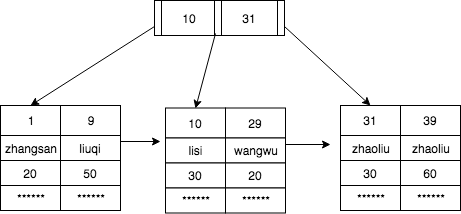
二級索引

假如我們想要查詢名字為zhaoliu,年齡為30的人的資訊。即name='zhaoliu',age=30
- (1)先查二級索引,先用二分法查詢發現在wangwu名字的右邊
- (2)讀取右邊的這頁的資料到記憶體,二分法查到資料2個name為zhaoliu人。
- (3)繼續二分法比較age查到資料id=31
- (4)id=31回查聚簇索引先用二分法查詢發現在31右邊
- (5)讀取31左邊這頁資料到記憶體,二分法查到資料並返回資料
如果你僅僅查詢id,name和age資料那麼這樣就用到了覆蓋索引,這樣就不用回查聚簇索引,在第(3)步直接返回資料即可。