
大資料平臺常見開源工具集錦(強烈推薦收藏)
引言
大資料平臺是對海量結構化、非結構化、半機構化資料進行採集、儲存、計算、統計、分析處理的一系列技術平臺。大資料平臺處理的資料量通常是TB級,甚至是PB或EB級的資料,這是傳統資料倉庫工具無法處理完成的,其涉及的技術有分散式計算、高併發處理、高可用處理、叢集、實時性計算等,彙集了當前IT領域熱門流行的各類技術。
此片文章整理出了大資料平臺常見的一些開源工具,並且依據其主要功能進行分類,以便大資料學習者及應用者快速查詢和參考。
在這裡我還是要推薦下我自己建的大資料學習交流qq裙: 957205962, 裙 裡都是學大資料開發的,如果你正在學習大資料 ,小編歡迎你加入,大家都是軟體開發黨,不定期分享乾貨(只有大資料開發相關的),包括我自己整理的一份2018最新的大資料進階資料和高階開發教程,歡迎進階中和進想深入大資料的小夥伴
大資料平臺常見的一些工具彙集
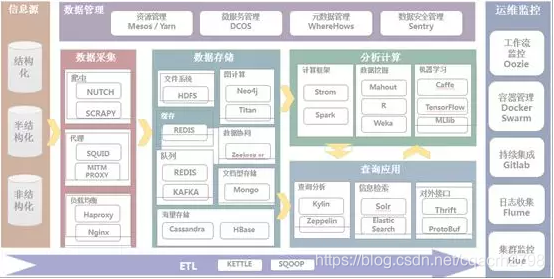
主要包含:語言工具類、資料採集工具、ETL工具、資料儲存工具、分析計算、查詢應用及運維監控工具等。以下對各工具作為簡要的說明。
一語言工具類
1
Java程式設計技術
Java程式設計技術是目前使用最為廣泛的網路程式語言之一,是大資料學習的基礎。Java具有簡單性、面向物件、分散式、健壯性、安全性、平臺獨立與可移植性、多執行緒、動態性等特點,擁有極高的跨平臺能力,是一種強型別語言,可以編寫桌面應用程式、Web應用程式、分散式系統和嵌入式系統應用程式等,是大資料工程師最喜歡的程式設計工具,最重要的是,Hadoop以及其他大資料處理技術很多都是用Java,因此,想學好大資料,掌握Java基礎是必不可少的。
2
Linux命令
對於大資料開發通常是在Linux環境下進行的,相比Linux作業系統,Windows作業系統是封閉的作業系統,開源的大資料軟體很受限制,因此,想從事大資料開發相關工作,還需掌握Linux基礎操作命令。
3
Scala
Scala是一門多正規化的程式語言,一方面吸收繼承了多種語言中的優秀特性,一方面又沒有拋棄 Java 這個強大的平臺,大資料開發重要框架Spark是採用Scala語言設計的,想要學好Spark框架,擁有Scala基礎是必不可少的,因此,大資料開發需掌握Scala程式設計基礎知識!
4
Python與資料分析
Python是面向物件的程式語言,擁有豐富的庫,使用簡單,應用廣泛,在大資料領域也有所應用,主要可用於資料採集、資料分析以及資料視覺化等,因此,大資料開發需學習一定的Python知識。
二資料採集類工具
1)Nutch是一個開源Java 實現的搜尋引擎。它提供了我們執行自己的搜尋引擎所需的全部工具,包括全文搜尋和Web爬蟲。
2)Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架,可以應用在資料探勘,資訊處理或儲存歷史資料等一系列的程式中。大資料的採集需要掌握Nutch與Scrapy爬蟲技術。
三ETL工具
1
Sqoop
Sqoop是一個用於在Hadoop和關係資料庫伺服器之間傳輸資料的工具。它用於從關係資料庫(如MySQL,Oracle)匯入資料到Hadoop HDFS,並從Hadoop檔案系統匯出到關係資料庫,學習使用Sqoop對關係型資料庫資料和Hadoop之間的匯入有很大的幫助。
2
Kettle
Kettle是一個ETL工具集,它允許你管理來自不同資料庫的資料,通過提供一個圖形化的使用者環境來描述你想做什麼,而不是你想怎麼做。作為Pentaho的一個重要組成部分,現在在國內專案應用上逐漸增多。其資料抽取高效穩定。
四資料儲存類工具
1
Hadoop分散式儲存與計算
Hadoop實現了一個分散式檔案系統(Hadoop Distributed File System),簡稱HDFS。Hadoop的框架最核心的設計就是:HDFS和MapReduce。HDFS為海量的資料提供了儲存,MapReduce則為海量的資料提供了計算,因此,需要重點掌握,除此之外,還需要掌握Hadoop叢集、Hadoop叢集管理、YARN以及Hadoop高階管理等相關技術與操作!
2
Hive
Hive是基於Hadoop的一個數據倉庫工具,可以將結構化的資料檔案對映為一張資料庫表,並提供簡單的SQL查詢功能,可以將SQL語句轉換為MapReduce任務進行執行。相對於用Java程式碼編寫MapReduce來說,Hive的優勢明顯:快速開發,人員成本低,可擴充套件性(自由擴充套件叢集規模),延展性(支援自定義函式)。十分適合資料倉庫的統計分析。對於Hive需掌握其安裝、應用及高階操作等。
3
ZooKeeper
ZooKeeper 是一個開源的分散式協調服務,是Hadoop和HBase的重要元件,是一個為分散式應用提供一致性服務的軟體,提供的功能包括:配置維護、域名服務、分散式同步、元件服務等,在大資料開發中要掌握ZooKeeper的常用命令及功能的實現方法。
4
HBase
HBase是一個分散式的、面向列的開源資料庫,它不同於一般的關係資料庫,更適合於非結構化資料儲存的資料庫,是一個高可靠性、高效能、面向列、可伸縮的分散式儲存系統,大資料開發需掌握HBase基礎知識、應用、架構以及高階用法等。
5
Redis
Redis是一個Key-Value儲存系統,其出現很大程度補償了Memcached這類Key/Value儲存的不足,在部分場合可以對關係資料庫起到很好的補充作用,它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客戶端,使用很方便,大資料開發需掌握Redis的安裝、配置及相關使用方法。
6
Kafka
Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,其在大資料開發應用上的目的是通過Hadoop的並行載入機制來統一線上和離線的訊息處理,也是為了通過叢集來提供實時的訊息。大資料開發需掌握Kafka架構原理及各元件的作用和使用方法及相關功能的實現。
7
Neo4j
Neo4j是一個高效能的,NoSQL圖形資料庫,具有處理百萬和T級節點和邊的大尺度處理網路分析能力。它是一個嵌入式的、基於磁碟的、具備完全的事務特性的Java持久化引擎,但是它將結構化資料儲存在網路(從數學角度叫做圖)上而不是表中。Neo4j因其嵌入式、高效能、輕量級等優勢,越來越受到關注。
8
Cassandra
在這裡我還是要推薦下我自己建的大資料學習交流qq裙: 957205962, 裙 裡都是學大資料開發的,如果你正在學習大資料 ,小編歡迎你加入,大家都是軟體開發黨,不定期分享乾貨(只有大資料開發相關的),包括我自己整理的一份2018最新的大資料進階資料和高階開發教程,歡迎進階中和進想深入大資料的小夥伴
Cassandra是一個混合型的非關係的資料庫,類似於Google的BigTable,其主要功能比Dynamo(分散式的Key-Value儲存系統)更豐富。這種NoSQL資料庫最初由Facebook開發,現已被1500多家企業組織使用,包括蘋果、歐洲原子核研究組織(CERN)、康卡斯特、電子港灣、GitHub、GoDaddy、Hulu、Instagram、Intuit、Netflix、Reddit等。是一種流行的分散式結構化資料儲存方案。
9
SSM
SSM框架是由Spring、Spring MVC、MyBatis三個開源框架整合而成,常作為資料來源較簡單的Web專案的框架。大資料開發需分別掌握Spring、Spring MVC、MyBatis三種框架的同時,再使用SSM進行整合操作。
五分析計算類工具
1
Spark
Spark是專為大規模資料處理而設計的快速通用的計算引擎,其提供了一個全面、統一的框架用於管理各種不同性質的資料集和資料來源的大資料處理的需求,大資料開發需掌握Spark基礎、SparkJob、Spark RDD部署與資源分配、Spark Shuffle、Spark記憶體管理、Spark廣播變數、Spark SQL、Spark Streaming以及Spark ML等相關知識。
2
Storm
Storm 是自由的開源軟體,一個分散式的、容錯的實時計算系統,可以非常可靠的處理龐大的資料流,用於處理Hadoop的批量資料。Storm支援許多種程式語言,並且有許多應用領域:實時分析、線上機器學習、不停頓的計算、分散式RPC(遠過程呼叫協議,一種通過網路從遠端計算機程式上請求服務)、ETL等等。Storm的處理速度驚人:經測試,每個節點每秒鐘可以處理100萬個資料元組。
3
Mahout
Mahout目的是“為快速建立可擴充套件、高效能的機器學習應用程式而打造一個環境”,主要特點是為可伸縮的演算法提供可擴充套件環境、面向Scala/Spark/H2O/Flink的新穎演算法、Samsara(類似R的向量數學環境),它還包括了用於在MapReduce上進行資料探勘的眾多演算法。
4
Pentaho
Pentaho是世界上最流行的開源商務智慧軟體,以工作流為核心的、強調面向解決方案而非工具元件的、基於Java平臺的BI套件。包括一個Web Server平臺和幾個工具軟體:報表、分析、圖表、資料整合、資料探勘等,可以說包括了商務智慧的方方面面。Pentaho的工具可以連線到NoSQL資料庫。大資料開發需瞭解其使用方法。
六查詢應用類工具
1
Avro與Protobuf
Avro與Protobuf均是資料序列化系統,可以提供豐富的資料結構型別,十分適合做資料儲存,還可進行不同語言之間相互通訊的資料交換格式,學習大資料,需掌握其具體用法。
2
Phoenix
Phoenix是用Java編寫的基於JDBC API操作HBase的開源SQL引擎,其具有動態列、雜湊載入、查詢伺服器、追蹤、事務、使用者自定義函式、二級索引、名稱空間對映、資料收集、時間戳列、分頁查詢、跳躍查詢、檢視以及多租戶的特性,大資料開發需掌握其原理和使用方法。
3
Kylin
Kylin是一個開源的分散式分析引擎,提供了基於Hadoop的超大型資料集(TB/PB級別)的SQL介面以及多維度的OLAP分散式聯機分析。最初由eBay開發並貢獻至開源社群。它能在亞秒內查詢巨大的Hive表。
4
Zeppelin
Zeppelin是一個提供互動資料分析且基於Web的筆記本。方便你做出可資料驅動的、可互動且可協作的精美文件,並且支援多種語言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。
5
ElasticSearch
ElasticSearch是一個基於Lucene的搜尋伺服器。它提供了一個分散式、支援多使用者的全文搜尋引擎,基於RESTful Web介面。ElasticSearch是用Java開發的,並作為Apache許可條款下的開放原始碼釋出,是當前流行的企業級搜尋引擎。設計用於雲端計算中,能夠達到實時搜尋、穩定、可靠、快速、安裝使用方便。
6
Solr
Solr基於Apache Lucene,是一種高度可靠、高度擴充套件的企業搜尋平臺, 是一款非常優秀的全文搜尋引擎。知名使用者包括eHarmony、西爾斯、StubHub、Zappos、百思買、AT&T、Instagram、Netflix、彭博社和Travelocity。大資料開發需瞭解其基本原理和使用方法。
七資料管理類工具
1
Azkaban
Azkaban是由linked開源的一個批量工作流任務排程器,它是由三個部分組成:Azkaban Web Server(管理伺服器)、Azkaban Executor Server(執行管理器)和MySQL(關係資料庫),可用於在一個工作流內以一個特定的順序執行一組工作和流程,可以利用Azkaban來完成大資料的任務排程,大資料開發需掌握Azkaban的相關配置及語法規則。
2
Mesos
Mesos 是由加州大學伯克利分校的AMPLab首先開發的一款開源叢集管理軟體,支援Hadoop、ElasticSearch、Spark、Storm 和Kafka等架構。對資料中心而言它就像一個單一的資源池,從物理或虛擬機器器中抽離了CPU、記憶體、儲存以及其它計算資源,很容易建立和有效執行具備容錯性和彈性的分散式系統。
3
Sentry
Sentry 是一個開源的實時錯誤報告工具,支援 Web 前後端、移動應用以及遊戲,支援 Python、OC、Java、Go、Node、Django、RoR 等主流程式語言和框架 ,還提供了 GitHub、Slack、Trello 等常見開發工具的整合。使用Sentry對資料安全管理很有幫助。
八運維監控類工具
Flume是一款高可用、高可靠、分散式的海量日誌採集、聚合和傳輸的系統,Flume支援在日誌系統中定製各類資料傳送方,用於收集資料;同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方(可定製)的能力。大資料開發需掌握其安裝、配置以及相關使用方法。
關注微信公眾號:程式設計師交流互動平臺!獲取資料學習!