
基於檢視聚合的聯合三維生成與目標檢測
摘要
我們提出AVOD,一個用於自主駕駛場景的聚合檢視物件檢測網路。提出的神經網路結構使用LIDAR點雲和RGB影象生成由兩個子網路共享的特徵:區域建議網路(RPN)和第二級檢測器網路。提出的RPN使用能夠在高解析度特徵地圖上執行多模態特徵融合的新體系結構來為道路場景中的多個物件類生成可靠的3D物件建議。
利用這些建議,第二階段檢測網路執行精確的面向3D邊界盒迴歸和類別分類,以預測三維空間中物體的範圍、方向和分類。我們提出的體系結構在KITTI 3D目標檢測基準[1]上產生最新結果,同時以低記憶體佔用實時執行,使得它適合在自主車輛上部署。程式碼是:https://github.com/kujason/avod

一、引言
近年來,深層神經網路在二維目標檢測任務上取得的顯著進展並沒有很好地轉移到三維目標檢測上。達到了90%以上的平均精度(AP),而最高得分的3D汽車檢測器在同一場景只達到70%的AP。造成這種差距的原因是由於在估計問題中新增三維而引起的困難、3D輸入資料的低解析度、以及作為距離的函式的其質量的惡化。此外,與2D物件檢測不同,3D物件檢測任務需要估計定向邊界框(圖1)。
與2D物件檢測器類似,大多數用於3D物件檢測的最新深度模型依賴於用於3D搜尋空間縮減的3D區域建議生成步驟。使用區域建議允許在稍後的檢測階段通過更復雜和計算上更昂貴的處理產生高質量的檢測。但是,提案生成階段的任何遺漏例項在下列階段無法恢復。因此,在區域建議生成階段實現高召回對於良好的效能至關重要。
區域建議網路(RPN)是在Faster-RCNN[2]中提出的,並且已經成為二維目標檢測器中主要的建議生成器。RPN可以被認為是弱模態檢測器,提供高召回率和低精度的建議。這些深層結構很有吸引力,因為它們能夠與其他檢測階段共享計算上昂貴的卷積特徵提取器。
然而,將這些RPNS擴充套件到3D是一項非平凡的任務。更快的R-CNN RPN架構是為密集、高解析度的影象輸入量身定製的,其中物件通常佔據特徵對映中的多個畫素。當考慮稀疏且低解析度的輸入時,例如前檢視[3]或鳥瞰圖(BEV)[4]點雲投影,該方法不能保證有足夠的資訊來生成區域建議,特別是對於小物件類。
本文旨在通過提出AVOD(用於自主駕駛的聚合檢視物件檢測體系結構)來解決這些困難。所提出的架構提供以下貢獻:
●受用於2D目標檢測的特徵金字塔網路(FPN)[5]的啟發,我們提出了一種新的特徵提取器,該特徵提取器從LIDAR點雲和RGB影象生成高解析度特徵圖,允許場景中的小類定位。
●我們提出一個特徵融合區域建議網路(RPN),它利用多種模式為小類產生高召回區域建議。
●我們提出了一種符合盒幾何約束的新的3D邊界盒編碼,允許更高的3D定位精度。
●所提出的神經網路結構利用RPN階段的1×1卷積,以及3D錨點投影的固定查詢表,允許高計算速度和低記憶體佔用,同時保持檢測效能。
上述貢獻導致一種以低計算成本和記憶體佔用提供最新檢測效能的體系結構。最後,我們將網路整合到我們的自主駕駛堆疊中,並在更極端的天氣和光照條件下對新場景和檢測進行概括,使之成為在自主車輛上部署的適當候選。
二。相關工作
用於提案生成的手工製作特徵:在3D區域提案網路(RPN)[2]出現之前,3D提案生成演算法通常使用手工製作的特徵來生成小組候選框,以檢索3D空間中的大多數物件。3DOP[6]和Mono3D[7]使用來自立體點雲和單眼影象的各種手工製作的幾何特徵來在能量最小化框架中對3D滑動視窗進行評分。最上面的K個評分視窗被選擇為區域建議,然後被修改的快速RCNN[?生成最終的3D檢測。我們使用區域建議網路,從BEV和影象空間學習特徵,以高效方式生成更高質量的建議。
建議的自由單鏡頭檢測器:單鏡頭物件檢測器也被提出作為RPN自由體系結構的3D物件檢測任務。VeloFCN[3]將LIDAR點雲投影到前檢視,該點雲用作全卷積神經網路的輸入,以直接生成密集的3D邊界框。3D-FCN[8]通過在由LIDAR點雲構建的3D體素網格上應用3D卷積來擴充套件這個概念,以產生更好的3D邊界框。我們的兩階段架構使用RPN來檢索道路場景中的大多數物件例項,與這兩個單鏡頭方法相比,提供了更好的結果。VoxelNet[9]通過編碼具有逐點特徵而不是佔用值的體素來進一步擴充套件3D-FCN。然而,即使使用稀疏的3D卷積運算,VoxelNet的計算速度仍比我們提出的體系結構慢3×,這在汽車和行人類別上提供了更好的結果。
基於單眼的建議生成:最新技術的另一個方向是使用成熟的2D物件檢測器來生成2D中的建議,然後通過模態程度迴歸將其擠壓到3D。這種趨勢始於[10]的室內物體檢測,它激發了.stumbased PointNets(F-PointNet)[11]使用點網[12]的點狀特徵代替點直方圖進行範圍迴歸。雖然這些方法在室內場景和亮光照明的室外場景中工作良好,但是在更極端的室外場景中它們預期表現不佳。任何未命中的2D檢測都將導致未命中的3D檢測,因此,在這種極端條件下這些方法的泛化能力尚未得到證明。
LIDAR資料比影象資料變化小得多,在第四節中,我們顯示AVOD對噪聲LIDAR資料和光照變化是魯棒的,因為它是在雪景和低光條件下測試的。
基於單眼的3D物體檢測器:另一種利用成熟的2D物體檢測器的方法是使用先驗知識僅從單眼影象執行3D物體檢測。Deep MANTA[13]提出一種基於單目影象的多工車輛分析方法,該方法同時優化區域建議、檢測、2D盒迴歸、零件定位、零件可見性和3D模板預測。該體系結構需要與幾種型別的車輛相對應的3D模型的資料庫,使得所提出的方法很難推廣到不存在此類模型的類。Deep3DBox[14]建議通過利用3D邊界框的透視投影應該緊密地適合其2D檢測視窗這一事實,將2D物件檢測器擴充套件到3D。然而,在第四節中,與使用點雲資料的方法相比,這些方法在3D檢測任務上執行得很差。
3D區域建議網路:3DRPN之前已經在[15]中提出用於從RGBD影象中檢測3D物件。然而,據我們所知,MV3D[4]是唯一針對自主駕駛場景提出3DRPN的體系結構。MV3D通過將BEV特徵對映中的每個畫素對應到多個先前的3D錨點,將更快的R-CNN[2]的基於影象的RPN擴充套件到3D。
然後,這些錨點被饋送到RPN,以生成用於從BEV、[3]的前檢視和影象檢視特徵對映建立特定於檢視的特徵作物的3D建議。利用深度融合方案結合來自這些特徵作物的資訊,產生最終的檢測輸出。然而,這種RPN架構對於BEV中的小物件例項並不適用。當由卷積特徵提取器進行下采樣時,小例項將佔據最終特徵圖中畫素的一小部分,導致沒有足夠的資料來提取資訊特徵。我們的RPN體系結構旨在將影象和BEV特徵對映中的全解析度特徵作物作為輸入融合到RPN,從而允許為較小的類生成高召回建議。此外,我們的特徵提取器提供全解析度的特徵圖,這顯示出在檢測框架的第二階段對小目標的定位精度有很大幫助。
三、AVOD體系結構
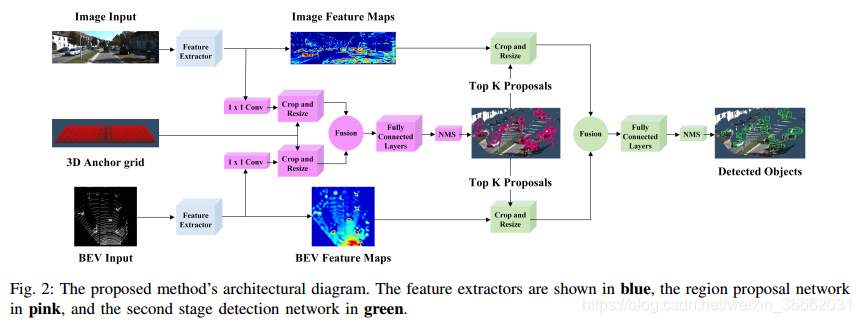
如圖2所示,提出的方法使用特徵提取器從BEV圖和RGB影象中生成特徵圖。然後,RPN使用兩個特徵對映來生成非定向區域建議,這些建議被傳遞到檢測網路以進行維度細化、方向估計和類別分類。
A.從點雲和影象生成特徵地圖
我們遵循[4]中描述的過程,以0:1米解析度從點雲的體素網格表示生成六通道BEV圖。點雲在[40;40]×[0;70]米處裁剪,以包含攝像機視場內的點。BEV圖的前5個通道用每個網格單元中點的最大高度編碼,這些點由沿Z軸[0;2:5]米之間的5個等切片生成。第六個BEV通道包含每個單元計算的點密度資訊為min(1:0;log(log 16 N+1)),其中N是單元中的點數。。
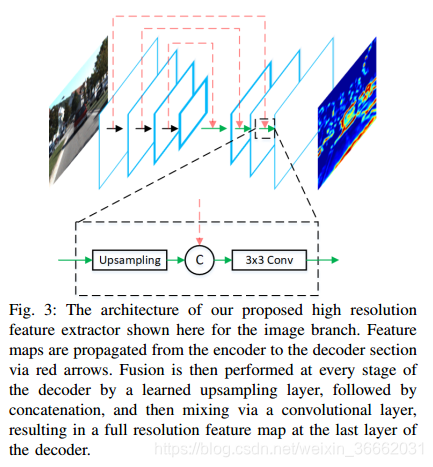
B.特徵提取器
所提出的體系結構使用兩個相同的特徵提取器體系結構,每個輸入檢視一個。全解析度特徵提取器如圖3所示,由兩個部分組成:編碼器和解碼器。編碼器在VGG-16[16]之後進行建模,經過一些修改,主要是將通道數量減少一半,並在conv-4層切斷網路。因此,編碼器以M×N×D影象或BE圖作為輸入,產生M8×N8×D_特徵圖F。KeTI資料集中的平均行人在BEV中佔據0:8×0:6米。這轉化為一個8×6畫素區域的BEV地圖與0:1米解析度。下采樣8×的結果是這些小類在輸出特徵圖中佔據不到一個畫素,即沒有考慮卷積引起的接收場的增加。受特徵金字塔網路(FPN)[5]的啟發,我們建立了一個自底向上解碼器,該解碼器學習將特徵對映上取樣回原始輸入大小,同時保持執行時間速度。譯碼器將編碼器的輸出F作為輸入,產生一個新的M×N×D~特徵圖。圖3顯示瞭解碼器執行的操作,包括通過conv-transpose操作對輸入進行上取樣,從編碼器連線相應的特徵圖,最後通過3×3卷積操作將兩者融合。最終的特徵圖具有高解析度和表示能力,並且由RPN和第二級檢測網路共享。
C 多模式融合區域建議網路
類似於2D兩級檢測器,提出的RPN迴歸一組先驗3D盒與地面真值之間的差異。這些先前的框被稱為錨,並且使用圖4所示的軸對齊的邊框編碼進行編碼。錨箱由質心(tx;ty;tz)和軸對齊尺寸(dx;dy;dz)引數化。為了生成3D錨定網格,在BEV中以0:5米的間隔取樣(tx;ty)對,而tz是基於感測器在地面以上的高度確定的。通過聚類每個類的訓練樣本來確定錨的維度。在BEV中沒有3D點的錨通過積分影象被有效去除,導致每幀80_100K非空錨。
通過多檢視作物和大小調整操作提取特徵作物:為了從檢視特定的特徵對映中提取每個錨的特徵作物,我們使用作物和大小調整操作[17]。給定3D中的錨點,通過將錨點投影到BEV和影象特徵圖上來獲得兩個感興趣區域。然後使用相應的區域從每個檢視中提取特徵地圖作物,然後將特徵地圖作物的雙線性調整到3×3以獲得等長的特徵向量。這種提取方法得到的特徵量在兩種檢視中都遵循投影錨點的縱橫比,與Faster-RCNN最初使用的3×3卷積相比,提供了更可靠的特徵量。
通過1×1卷積層進行降維:在某些情況下,區域建議網路需要為GPU儲存器中的100K錨儲存特徵作物。試圖直接從高維特徵對映中提取特徵作物會給每個輸入檢視帶來很大的記憶體開銷。例如,假設32位浮點表示,從256維特徵對映中提取100K錨的7×7個特徵作物需要大約5GB的記憶體。此外,用RPN處理這種高維特徵作物極大地增加了其計算需求。受[18]中所用方法的啟發,我們提出在每個檢視的輸出特徵對映上應用1×1卷積核,作為一種有效的降維機制,它學習選擇對區域建議生成的效能有很大貢獻的特徵。這減少了D~×計算錨特定特徵作物的記憶體開銷,允許RPN僅使用幾兆位元組的額外記憶體處理數萬錨的融合特徵。
3D建議生成:裁剪和大小調整操作的輸出是兩個檢視中大小相等的特徵裁剪,它們通過逐個元素的平均操作進行融合。大小為256的完全連線的兩個任務特定分支[2]使用融合的特徵作物來回歸軸對齊的物件建議框並輸出物件/背景“客觀性”得分。通過計算(tx;ty;tz;dx;dy;dz)、錨杆與地面之間的質心差和尺寸差進行三維盒迴歸。
真邊界框。平滑L1損失用於3D盒迴歸,交叉熵損失用於“客觀性”。與[2]類似,在計算迴歸損失時忽略背景錨點。通過計算錨和地面真值邊界框之間的BEV中的2DIoU來確定背景錨。對於汽車類,IoU小於0:3的錨被認為是背景錨,而IoU大於0:5的錨被認為是物件錨。對於行人和騎自行車的人類,物件錨IoU閾值降低到0:45。為了去除冗餘建議,在BEV中採用2D非最大值抑制(NMS)在IoU閾值0:8時保持訓練期間最多1024個建議。在推理時,300個建議用於汽車類,而1024個建議用於行人和騎自行車者。
D.第二階段檢測網路
3D包圍盒編碼:in [ 4 ],陳等人。聲稱8角盒編碼比先前在[15]中提出的傳統軸對齊編碼提供更好的結果。然而,8角編碼沒有考慮3D邊界框的物理約束,因為邊界框的頂角被迫與底部的那些角對齊。為了減少冗餘度並保持這些物理約束,我們提出用四個角和兩個高度值對包圍盒進行編碼,這兩個高度值代表了從感測器高度確定的來自地面的頂角和底角偏移。因此,我們的迴歸目標是(x1::x4;y1::y4;h1;h2),建議和地面真值框之間的角和高度偏離地面。為了確定角點偏移,我們將提案的最近角點與BEV中地面真值框的最近角點對應。所提出的編碼將盒表示從過引數化的24維向量減少到10維向量。
顯式方向向量迴歸:為了從3D邊界框中確定方向,MV3D[4]依賴於估計邊界框的範圍,其中方向向量假設在框的長邊方向。這種方法存在兩個問題。首先,對於檢測出的不總是遵守上述規則的物件,如行人,此方法會失敗。其次,所得到的取向只知道±π弧度的加性常數。由於角點順序沒有保留在角點到角點最近的匹配中,因此丟失了方向資訊。
圖1給出了一個例子,說明同一個矩形邊界框如何可以包含兩個具有相反方向向量的物件例項。我們的體系結構通過計算(xθ;yθ)=(cos(θ);sin(θ))來解決這個問題。這個方向向量表示隱式地處理角度包裝,因為每個θ2[π;π]都可以由BEV空間中的唯一單位向量表示。我們使用迴歸的方向向量來解決邊界框方向估計中的模糊性,從採用的四角表示,因為這個實驗發現比直接使用迴歸的方向更準確。具體地說,我們提取邊界框的四個可能方向,然後選擇最接近顯式迴歸方向向量的方向。
生成最終檢測:與RPN類似,多檢視檢測網路的輸入是通過將建議投影到兩個輸入檢視中而產生的特徵作物。由於建議的數量比錨的數量低一個數量級,所以使用深度為D~=32的原始特徵圖來生成這些特徵作物。來自兩個輸入檢視的裁剪被調整到7×7,然後與逐個元素的平均操作融合。
單組大小為2048的三層完全連線的層處理融合的特徵作物,以便為每個建議輸出箱迴歸、方向估計和類別分類。與RPN類似,對於邊界盒和方向向量迴歸任務,我們採用結合兩個平滑L1損失的多工損失和分類任務的交叉熵損失。只有當建議在BEV中至少具有0:65或0:552DIoU,並且分別具有用於汽車和行人/騎自行車者的地面真值盒時,才在評估迴歸損失時考慮這些建議。為了消除重疊檢測,在0:01的閾值處使用NMS。

E.培訓
我們訓練兩個網路,一個用於汽車班,一個用於行人和自行車班。RPN和檢測網路採用端到端方式聯合訓練,使用分別包含512和1024ROI的一個影象的小批量。使用ADAM優化器對網路進行120K迭代訓練,初始學習速率為0:0001,每30K迭代,衰減係數為0:8,衰減係數為指數衰減。
四、實驗和結果
我們在KITTI物件檢測基準[1]的三個類上測試了AVOD在提案生成和物件檢測任務上的效能。我們遵循[4]將所提供的7481個訓練幀分割成大約1∶1的訓練和驗證集。對於評估,我們遵循KITTI提出的簡單、中等、困難的分類。我們評估和比較了我們實現的兩個版本,使用類似於[4]的VGG類特徵提取器的Ours,以及使用在第III-B節中描述的建議的高解析度特徵提取器的Ours(Feature Pyramid)。
3D建議召回:使用0:53DIoU閾值的3D邊界框召回評估3D建議生成。我們將RPN的三個變體與建議生成演算法3DOP[6]和Mono3D[7]進行比較。圖5顯示了我們的RPN變體(3DOP和Mono3D)的召回率與建議數量的關係曲線。可以看出,我們的RPN變體在所有三個類上都遠遠超過3DOP和Mono3D。例如,我們的基於特徵金字塔的融合RPN在汽車類上實現了86%的3D召回,每幀只有10個建議。3DOP和Mono3D在汽車類上的最大召回率分別為73:87%和65:74%。這個差距也出現在步行和騎自行車的階層,我們的RPN實現了超過百分之二十的回憶增加在1024個建議。這種效能上的巨大差距表明基於學習的方法優於基於手工製作的特徵的方法。對於汽車類,我們的RPN變體僅50個建議實現了91%的召回,而MV3D[4]報告需要300個建議來實現相同的召回。應當指出,MV3D沒有公開提供汽車的建議結果,也沒有對行人或騎自行車的人進行測試。
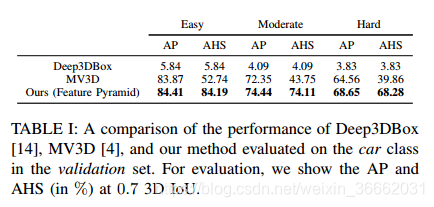
三維物體檢測:使用3D和BEV AP和平均航向相似度(AHS)評估3D檢測結果,對於汽車等級為0:7IoU閾值,對於行人和自行車等級為0:5IoU閾值。AHS是平均方向相似度(AOS)[1],但是使用3DIOU和全域性方向角而不是二維IOU和觀察角來評估,消除了度量對定位精度的依賴。我們將其與驗證集中公開提供的MV3D[4]和Deep3DBox[14]的檢測進行比較。必須注意的是,目前沒有公開發布的方法為3D物件檢測任務提供關於步行者和騎自行車者的類的結果,因此只對汽車類進行比較。在驗證集(表I)中,我們的架構在中等設定時比MV3D效能高2:09%,在硬設定時比MV3D效能高4:09%。然而,在中等和硬設定下,AVOD與MV3D相比,AHS分別增加了30:36%和28:42%。這可以歸因於III-D節中討論的方向向量方向的丟失,導致方向估計高達±π弧度的加性誤差。為了驗證這個斷言,圖7顯示了AVOD和MV3D的結果與KITTI的地面事實相比的視覺化。可以看到,MV3D為幾乎一半的汽車分配了錯誤的方向。另一方面,我們提出的體系結構是正確的。

面向所有汽車的場景。正如所預期的,Deep3DBox與我們提出的體系結構在3D定位效能方面差距很大。從圖7中可以看出,Deep3DBox無法在3D中精確定位大部分車輛,這進一步加強了基於融合的方法優於基於單眼的方法。我們還將架構在KITTI測試集上的效能與MV3D、VoxelNet[9]和F-PointNet[11]進行了比較。測試集結果由評估伺服器直接提供,而評估伺服器不計算AHS度量。表II示出了KoTI測試集上AVOD的結果。可以看到,即使只使用用於特徵提取的編碼器,我們的架構在所有三個類上都表現得很好,同時比下一個最快的方法,F-PointNet.然而,一旦我們添加了我們的高解析度特徵提取器(Feature Pyramid),我們的架構在3D物件檢測方面就優於汽車類中的所有其他方法,在硬(高度遮擋或遠)例項中,與效能第二好的方法F-Po相比,具有顯著的4:19%的差距。國際網際網路。在步行類中,我們的特徵金字塔架構在BEV AP中排名第一,而在使用3DAP的硬例項中得分略高於F-PointNet。在自行車課上,我們的方法不適用於F點網。我們認為,這是由於KITTI資料集中騎行者例項數量較少,這導致對以下內容的偏向
行人在行人/自行車網路中的行人檢測。執行時和記憶體需求:我們使用FLOP計數和引數的數量來評估所提議網路的計算效率和記憶體需求。我們最終的特徵金字塔融合架構使用了大約38:073萬個引數,大約是MV3D的16%。我們提出的體系結構引數的數量。此外,我們的特徵金字塔融合架構要求每幀231:263億FLOP,允許它在TITAN Xp GPU上在0:1秒內處理幀,預處理需要20ms,推理需要80ms。這使得它比F-PointNet快1:7×同時保持了最先進的結果。最後,我們提出的體系結構在推理時只需要2GB的GPU記憶體,使得它適合於在自主車輛上部署。

消融研究:
表三顯示了改變不同的超引數對AP和AAHS測量的效能、模型引數的數量以及建議的體系結構的FLOP計數的影響。基本網路使用全文所描述的超引數值,以及MV3D的特徵提取器。nly特徵和其他使用大小為1×1的特徵作物作為RPN階段的輸入。我們還研究了圖4中所示的不同邊界盒編碼方案的效果,以及根據AP和AHS,新增方向迴歸輸出層對最終檢測效能的影響。最後,我們對比了MV3D提出的高解析度特徵提取器的效果。
RPN輸入變化:圖5顯示了原始RPN和BEV僅RPN在驗證集上的三個類上沒有特徵金字塔提取器的情況下的召回與建議數量的關係曲線。對於行人和騎自行車的階層,在RPN階段融合來自兩個檢視的特徵顯示提供10:1%和8:6%的回憶比BEV的唯一版本增加1024個建議。新增我們的高解析度特徵提取器將此差異增加到相應類的10:5%和10:8%。對於car類,新增影象特徵作為RPN的輸入,或者使用高解析度特徵提取器似乎不會
提供比BEV版本更高的召回價值。
我們將此歸因於這樣一個事實,即來自car類的例項通常在輸入BEV對映中佔據較大的空間,在相應的輸出低解析度特徵對映中提供足夠的特徵以可靠地生成物件建議。建議召回的增加對最終檢測效能的影響可以在表III中觀察到。在RPN階段使用影象和BEV特徵導致AP分別比僅用於步行和騎自行車的BEV版本增加6:9%和9:4%。
包圍盒編碼:我們通過訓練另外兩個網路來研究圖4中所示的不同包圍盒編碼的效果。第一網路使用迴歸的方向向量作為最終的方框方向,估計軸對齊的邊框。第二和第三網路使用我們的4角和MV3D的8角編碼,沒有像III-D節中所描述的額外的方向估計。NCOSTEN提供了比所有三個類的基礎網路低得多的AHS。這種現象可歸因於III-D節中所描述的取向資訊的丟失。


特徵提取器:將特徵提取器的檢測結果與基於VGG的MV3D特徵提取器的檢測結果進行比較。對於汽車類,我們的金字塔特徵提取器在AP和AHS中僅獲得0:3%的增益。然而,在較小的類上的效能增益要大得多。特別地,我們在行人和騎自行車的課程上分別獲得了19:3%和8:1%的AP增益。這表明,我們的高解析度特徵提取器是必不可少的,以實現對這兩個類的最新結果,在計算要求略有增加。
定性結果:圖6顯示了RPN的輸出以及3D和影象空間中的最終檢測。在https://youtu.be/mDaqKICiHyA上提供了更多定性結果,包括雪地和夜景中執行的AVOD的結果。
五、結論
在這項工作中,我們提出了AVOD,一個針對自主駕駛場景的3D物體檢測器。通過使用與多模態融合RPN架構耦合的高解析度特徵提取器,所提出的架構與現有技術不同,因此能夠為道路場景中的小類生成精確的區域建議。此外,所提出的結構使用顯式方向向量迴歸來解決從邊界框推斷出的模糊方向估計。在KITTI資料集上的實驗表明,我們提出的體系結構在3D定位、方向估計和分類任務方面優於現有技術。最後,給出了該體系結構的實時執行和低記憶體開銷。
REFERENCES
[1] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012, pp. 3354–3361.
[2] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards realtime object detection with region proposal networks,” in Advances in Neural Information Processing Systems 28, 2015, pp. 91–99.
[3] B. Li, T. Zhang, and T. Xia, “Vehicle detection from 3d lidar using fully convolutional network,” in Proceedings of Robotics: Science and Systems, AnnArbor, Michigan, June 2016.
[4] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3d object detection network for autonomous driving,” in Computer Vision and Pattern Recognition, 2017. CVPR 2017. IEEE Conference on,.
[5] T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie, ´ “Feature pyramid networks for object detection,” in Computer Vision and Pattern Recognition, vol. 1, no. 2, 2017, p. 4.
[6] X. Chen, K. Kundu, Y. Zhu, A. Berneshawi, H. Ma, S. Fidler, and R. Urtasun, “3d object proposals for accurate object class detection,” in NIPS, 2015.
[7] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun, “Monocular 3d object detection for autonomous driving,” in Computer Vision and Pattern Recognition, 2016.
[8] B. Li, “3d fully convolutional network for vehicle detection in point cloud,” in IROS, 2017.
[9] Y. Zhou and O. Tuzel, “Voxelnet: End-to-end learning for point cloud based 3d object detection,” arXiv preprint arXiv:1711.06396, 2017.
[10] J. Lahoud and B. Ghanem, “2d-driven 3d object detection in rgb-d images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4622–4630.
[11] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum pointnets for 3d object detection from rgb-d data,” arXiv preprint
arXiv:1711.08488, 2017.
[12] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” arXiv preprint arXiv:1612.00593, 2016.
[13] F. Chabot, M. Chaouch, J. Rabarisoa, C. Teuliere, and T. Chateau, ` “Deep manta: A coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[14] A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka, “3d bounding box estimation using deep learning and geometry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[15] S. Song and J. Xiao, “Deep sliding shapes for amodal 3d object detection in rgb-d images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 808–816.
[16] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[17] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, and K. Murphy, “Speed/accuracy trade-offs for modern convolutional object detectors,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
[18] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size,” arXiv preprint arXiv:1602.07360, 2016.
[19] “Kitti 3d object detection benchmark,” http://www.cvlibs.net/datasets/ kitti/eval object.php?obj benchmark=3d, accessed: 2018-02-28.