
VoxelNet:基於點雲的三維物體檢測的端到端學習
https://arxiv.org/pdf/1711.06396.pdf https://github.com/jeasinema/VoxelNet-tensorflow
摘要
3D點雲中物體的精確檢測是許多應用中的一個核心問題,如自主導航、室內機器人和增強/虛擬現實。為了將高度稀疏的鐳射雷達點雲與區域建議網路(RPN)進行介面,大多數現有的努力都集中在手工製作的特徵表示上,例如,鳥瞰投影。在這項工作中,我們不需要人工特徵工程的3D點雲,並提出VoxelNet,一個通用的3D檢測網路,統一特徵提取和包圍盒預測到一個階段,端到端可訓練的深網路。具體而言,VoxelNet將點雲劃分為等間距的三維體素,並通過新引入的體素特徵編碼(VFE)層將每個體素中的一組點變換為統一的特徵表示。以這種方式,點雲被編碼為描述性的體積表示,然後將其連線到RPN以產生檢測。KITTI車輛檢測基準的實驗表明,VoxelNe比現有的基於LIDAR的3D檢測方法大幅度地優於現有的基於LIDAR的3D檢測方法。此外,我們的網路學習一個有效的歧視性表示的物件具有不同的幾何形狀,導致令人鼓舞的結果,在3D檢測行人和騎自行車者,僅基於鐳射雷達。
介紹
基於點雲的3D物體檢測是各種真實世界應用的一個重要組成部分,如自主導航(11, 14)、管家機器人(26)和增強/虛擬現實(27)。與基於影象的檢測相比,鐳射雷達提供可靠的深度資訊,可以用於精確定位物體並表徵它們的形狀[21, 5 ]。然而,與影象不同的是,鐳射雷達點雲稀疏且具有高度可變的點密度,這是由於3D空間的非均勻取樣、感測器的有效範圍、遮擋和相對姿態等因素造成的。為了應對這些挑戰,許多方法手工製作用於三維物體檢測的點雲的特徵表示。幾種方法將點雲投影到透檢視中,並應用基於影象的特徵提取技術[28, 15, 22 ]。其他方法將點雲光柵化為3D體素網格,並用手工製作的特徵編碼每個體素〔41, 9, 37,38, 21, 5〕。然而,這些手動設計選擇引入了一個資訊瓶頸,阻止這些方法有效地利用3D形狀資訊和檢測任務所需的不變性。在影象識別(20)和檢測(13)任務上的重大突破是由於從手工製作的特徵到機器學習的特徵。
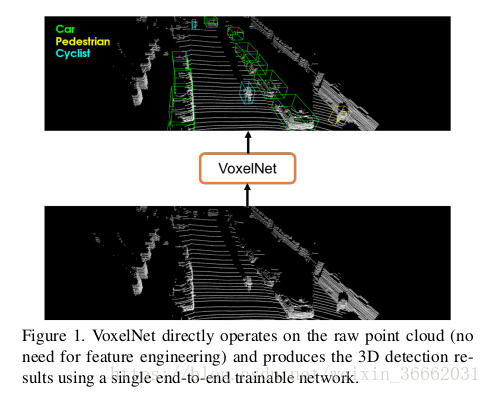
區域建議網路(RPN)[32 ]是一種高度有效的目標檢測演算法[17, 5,31,24]。然而,這種方法需要資料密集和組織在張量結構(例如,影象,視訊),這不是典型的鐳射雷達點雲的情況。在本文中,我們關閉了點集特徵學習和RPN之間的差距3D檢測任務。
我們提出了一個通用的3D檢測框架VoxelNETE,它同時學習點雲的判別特徵表示,並以端到端的方式預測精確的3D包圍盒,如圖2所示。我們設計了一種新的體素特徵編碼(VFE)層,它能夠在體素中實現點間互動,通過將點特徵與區域性聚集特徵相結合。 堆疊多個VFE層允許學習複雜特徵以表徵區域性3D形狀資訊。具體而言,VoxelNet將點雲劃分為等間距的三維體素,通過堆疊的VFE層編碼每個體素,然後3D卷積進一步聚集區域性體素特徵,將點雲轉換為高維體積表示。最後,RPN消耗體積表示併產生檢測結果。這種有效的演算法既有利於稀疏點結構,又有利於體素網格的有效並行處理。
我們評估VoelLeNET在鳥瞰檢視檢測和完整的3D檢測任務,由KITTI基準(11)提供。實驗結果表明,VoxelNET:大大優於現有的基於鐳射雷達的3D檢測方法。我們還證明,VoxelNETs在鐳射雷達點雲檢測行人和騎自行車者方面取得了非常令人鼓舞的結果。

1.1. Related Work
3D感測器技術的快速發展促使研究者開發有效的表示來檢測和定位點雲中的物體。用於特徵表示的早期方法中有一些是[39, 8, 7,19, 40,33,6,25, 1, 34,2 ]。當豐富和詳細的3D形狀資訊可用時,這些手工製作的特徵會產生令人滿意的結果。然而,它們無法適應更復雜的形狀和場景,並且從資料中學習所需的不變性,從而導致不受控制的場景(例如自主導航)的有限成功。
考慮到影象提供了詳細的紋理資訊,許多演算法從2D影象推斷出3D包圍盒〔4, 3, 42,43, 44, 36〕。然而,基於影象的3D檢測方法的精度受到深度估計精度的限制。
一些基於鐳射雷達的3D物體檢測技術利用體素網格表示。〔41, 9〕用從體素中包含的所有點匯出的6個統計量來編碼每個非空體素。〔37〕融合多個區域性統計資料來表示每個體素。〔38〕計算體素網格上的截斷符號距離。〔21〕使用三維體素網格的二進位制編碼。〔5〕通過在鳥瞰圖中計算多通道特徵圖和在正面檢視中的圓柱座標,介紹了一種鐳射雷達點雲的多視圖表示方法。其他一些研究將點雲投影到透檢視上,然後使用基於影象的特徵編碼方案〔28, 15, 22〕。
還存在多種結合影象和鐳射雷達的多模態融合方法以提高檢測精度[10, 16, 5 ]。這些方法與僅鐳射雷達的3D檢測相比,提供了改進的效能,特別是對於小物體(行人、騎自行車者)或物體遠時,因為攝像機提供比鐳射雷達更大數量級的測量。然而,需要與鐳射雷達進行時間同步和校準的附加攝像機限制了它們的使用,並且使得該解決方案對感測器故障模式更加敏感。在這項工作中,我們專注於鐳射雷達僅檢測。
1.2. Contributions
我們提出了一種新的端到端可訓練的深架構,基於點雲的3D檢測,VoxelNet,直接操作在稀疏的3D點,並避免資訊瓶頸由手動特徵工程引入。
我們提出了一種有效的實現VoxelNETs的方法,它既有利於稀疏點結構,又有利於體素網格上的高效並行處理。
我們在KITTI基準上進行實驗,並表明VoxelNETs在基於鐳射雷達的汽車、行人和騎自行車檢測基準中產生了最先進的結果。
2. VoxelNet
在這一節中,我們解釋了VoxelNETs的架構,用於訓練的損失函式,以及實現網路的有效演算法。
2.1. VoxelNet Architecture
所提出的VoxelNetwork由三個功能塊組成:(1)特徵學習網路,(2)卷積中間層,和(3)區域建議網路[32 ],如圖2所示。我們在下面的章節中詳細介紹了VoxelNET.
2.1.1 Feature Learning Network
體素劃分給定點雲,我們將3D空間細分成等距的體素,如圖2所示。假設點雲包含沿z、y、x軸分別具有d、h、w的三維空間。我們定義每個體素的大小V D,V H,和V W相應。得到的三維體素網格大小為D=D/V D,H=H/V H,W=W/V W。這裡,為了簡單起見,我們假設D、H、W是V D、V H、V W的倍數。
分組我們根據它們駐留的體素來分組點。由於距離、遮擋、物體相對姿態和非均勻取樣等因素,鐳射雷達點雲稀疏,在整個空間中具有高度可變的點密度。因此,在分組之後,體素將包含可變數量的點。圖2顯示了一個例子,其中Voxel-1比Voxel-2和Voxel-4具有更多的點,而Voxel-3不包含任何點。
隨機抽樣典型地,高解析度鐳射雷達點雲由100K點組成。直接處理所有的點不僅增加了計算平臺上的記憶體/效率負擔,而且在整個空間中高度可變的點密度可能會偏置檢測。為此,我們隨機地從包含多於T點的體素隨機取樣固定點T。該取樣策略有兩個目的,(1)計算節省(參見細節2.3節);和2)減少體素之間的點的不平衡,減少採樣偏倚,並且增加訓練的變化。
堆疊體素特徵編碼關鍵的創新是VFE層的鏈。為了簡單起見,圖2示出了一個體素的分層特徵編碼過程。在不損失一般性的情況下,我們使用VFE層-1來描述下面段落中的細節。圖3顯示了VFE層-1的體系結構。
表示V={P i=[x i,y i,z i,r i] t r r 4 } i=1…t作為含有t個t鐳射雷達點的非空體素,其中p i包含第i個點的XYZ座標,R i是接收的反射率。我們首先計算區域性均值作為V中的所有點的質心,表示為(v x,v y,v z)。然後用相對偏移W.R.T.質心得到每個點P i,得到輸入特徵集V={πi=[x i,y i,z i,r i,x i i,v x,y i i v y,z i v z z ] t r r 7 } i=1…t。接著,i通過全連通網路將每個P(FCN)變換為特徵空間,在這裡我們可以從點特徵f i r m集合資訊來編碼包含在體素中的表面的形狀。FCN由線性層、批量歸一化(BN)層和整流線性單元(Relu)層組成。在獲得逐點特徵表示之後,我們使用元素相關的最大池遍歷所有與V相關的f i以獲得區域性聚合特徵f fm m。最後,我們用f來增加每個f i以形成點i級聯特徵,如f i out=[f i t,f ft] tr r2m。 . 因此,我們得到輸出特徵集V out={F I out } I…t。所有非空體素以相同的方式編碼,並且它們在FCN中共享相同的引數集。
我們使用VFE-I(C in,C out)來表示將維度C的輸入特徵轉換為維度C out的輸出特徵的第i個VFE層。線性層在C(C out/2)中學習大小C的矩陣,逐點級聯產生尺寸C out的輸出。
由於輸出特徵結合了點特徵和區域性聚集特徵,堆疊VFE層編碼體素內的點相互作用,並且使得最終特徵表示能夠學習描述性形狀資訊。體素明智的特徵是通過將VFE-N的輸出通過FCN轉換成R C,並應用元素Max池,其中C是體素特徵的維度,如圖2所示。
稀疏張量表示通過只處理非空體素,我們得到體素特徵的列表,每個體素與特定的非空體素的空間座標唯一相關。獲得的體素特徵列表可以表示為一個稀疏的4D張量,大小為C×D××H×W,如圖2所示。雖然點雲包含100K點,但超過90%的體素通常是空的。表示非空體素特徵作為稀疏張量極大地減少了在反向傳播期間的記憶體使用和計算成本,並且它是我們高效實現的關鍵步驟。

2.1.2 Convolutional Middle Layers
2.1.3 Region Proposal Network
2.2. Loss Function
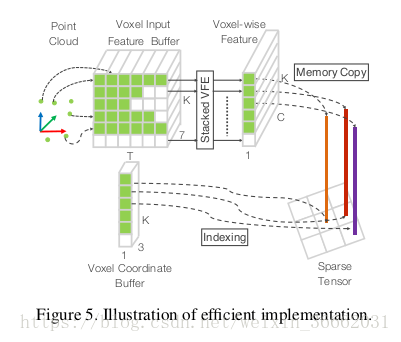
2.3. Efficient Implementation
3. Training Details
3.1. Network Details
Car Detection
Pedestrian and Cyclist Detection
3.2. Data Augmentation
4. Experiments
在KITTI 3D目標檢測基準(11)中,我們對VoxelNETs進行了評估,其中包含7481個訓練影象/點雲和7518個測試影象/點雲,覆蓋了三類:汽車、行人和騎自行車的人。對於每一類,檢測結果基於三個難度級別:容易、適度和硬來評估,這是根據物件大小、遮擋狀態和截斷級別確定的。由於測試集的真實性是不可用的,並且對測試伺服器的訪問是有限的,所以我們使用[4, 3, 5 ]中描述的協議進行綜合評估,並將訓練資料細分為訓練集和驗證集,從而產生TRAI的3712個數據樣本。寧和3769個數據樣本進行驗證。分裂避免了來自相同序列的樣本被包含在訓練和驗證集(3)中。最後,我們還提出了使用KITTI伺服器的測試結果。
對於CARS類別,我們將所提出的方法與幾種最先進的演算法進行比較,包括基於影象的方法:MUN3D(3)和3DOP(4);基於LIDAR的方法:VeloFCN(22)和3D-FCN(21);以及多模態方法MV[5 ]。MUN3D(3)、3DOP(4)和MV(5)使用預先訓練的模型進行初始化,而我們只使用KITTI中提供的鐳射雷達資料從頭開始訓練VoxelNET.
為了分析端到端學習的重要性,我們實現了來自VoxelNETS架構的強基線,但是使用手工製作的特徵而不是所提出的特徵學習網路。我們稱這個模型為手工製作的基線(HC基線)。HC基線使用在[1]中描述的鳥瞰圖特徵,其特徵是以0.1m解析度計算。與〔5〕不同,我們將高度通道的數目從4增加到16,以捕獲更詳細的形狀資訊-進一步增加高度通道的數量並不能導致效能改善。我們用類似大小的2D卷積層代替卷積中間層的VoxelNETs,這是VAR2D(16, 32, 3,1, 1),VAR2D(32, 64, 3,2, 1),VAR2D(64, 128, 3,1, 1)。最後,RPN在VoxelNet和HC基線上是相同的。HC基線和VoxelNet中的引數的總數非常相似。我們使用相同的訓練程式和第3節中描述的資料增強訓練HC基線。

4.1. Evaluation on KITTI Validation Set
Metrics
我們遵循官方KITTI評估協議,其中IOU閾值為0.7級車,是0.5級的行人和騎自行車。IOU閾值對於鳥瞰圖和全3D評價是相同的。我們使用平均精度(AP)度量的方法進行比較。
Evaluation in Bird’s Eye View
表1所示。VoxelNET始終優於所有競爭的方法在所有三個難度級。HC-BASIC也取得了令人滿意的效能相比,國家的最先進的[ 5 ],這表明我們的基礎區域建議網路(RPN)是有效的。對於行人和騎自行車的檢測任務,在鳥瞰圖中,我們比較建議的VoxelNET與HC基線。對於這些更具挑戰性的類別,VoxelNE比HC基線產生更高的AP,這表明端到端學習對於基於點雲的檢測是必不可少的。
我們要注意的是,[21 ]分別報告了88.9%、77.3%和72.7%的容易、中等和硬水平,但是這些結果是基於6000個訓練幀和1500個驗證幀的不同分割得到的,並且它們與表1中的演算法沒有直接的可比性。因此,我們不將這些結果包含在表中。
與僅需要精確定位2D平面中的物體的鳥瞰檢測相比,3D檢測是一個更具挑戰性的任務,因為它需要在3D空間中更精細地定位形狀。表2總結了比較。對於類車來說,VoxelNETs在所有難度級別上都顯著優於AP中的所有其他方法。特別地,僅使用鐳射雷達,VoxelNETs顯著地優於基於LIDAR +RGB的最新的方法MV(BV+FV+RGB)[5 ],分別在容易、中等和硬水平分別為10.68%、2.78%和6.29%。HC基線達到MV〔5〕方法的相似精度。
在鳥瞰評價中,我們還比較了3D行人和騎自行車檢測中的Vox和HC基線。由於3D姿態和形狀的高變化,這兩個類別的成功檢測需要更好的3D形狀表示。如表2所示,VoxelNETs的改進效能強調了更具挑戰性的3D檢測任務(從鳥瞰圖的8%改進到3D檢測的12%改進),這表明VoxelNet比手工製作的特徵更有效地捕獲3D形狀資訊。物件。

4.2. Evaluation on KITTI Test Set
我們通過向官方伺服器提交檢測結果來評估KoTI測試集上的VoxelNET.結果彙總在表3中。VoxelNet,在所有的任務(鳥瞰圖和3D檢測)和所有的困難中,顯著優於先前公佈的最先進的[ 5 ]。我們要注意的是,在KITTI基準中列出的許多其他主要方法都使用RGB影象和鐳射雷達點雲,而VoxelNETs僅使用鐳射雷達。
我們在圖6中給出了幾個3D檢測例項,為了更好的視覺化,使用鐳射雷達探測到的3D盒子被投影到RGB影象上。如圖所示,VoxelNETE在所有類別中提供高度精確的3D包圍盒。
Voxelnet的推理時間為225ms,體素輸入特徵計算為5ms,特徵學習網為20ms,卷積中間層為170ms,區域建議網在Tyxx GPU和1.7GHz CPU上採用30ms。

5. Conclusion
大多數現有的基於鐳射雷達的3D檢測方法依賴於手工製作的特徵表示,例如,鳥瞰投影。在本文中,我們去除了人工特徵工程的瓶頸,並提出了一種基於點雲的3D檢測的端到端可訓練的深層結構VoxelNet。我們的方法可以直接操作在稀疏的3D點,並有效地捕獲3D形狀資訊。我們還提出了一個有效的實現VoxelNET-受益於點雲稀疏和並行處理的體素網格。我們的KITTI車檢測任務的實驗表明,VoxelNETs遠遠優於現有的最先進的基於鐳射雷達的3D檢測方法。在更具挑戰性的任務,如行人和騎自行車者的3D檢測,VoxelNet也展示了令人鼓舞的結果表明,它提供了更好的3D表示。未來的工作包括擴充套件用於聯合鐳射雷達和基於影象的端到端3D檢測的VoxelNETE,以進一步提高檢測和定位精度。
Acknowledgement: We are grateful to our colleagues Russ Webb, Barry Theobald, and Jerremy Holland for their
valuable input.
References
[1] P. Bariya and K. Nishino. Scale-hierarchical 3d object recog-
nition in cluttered scenes. In 2010 IEEE Computer Soci-
ety Conference on Computer Vision and Pattern Recognition,
pages 1657–1664, 2010. 2
[2] L. Bo, X. Ren, and D. Fox. Depth Kernel Descriptors for
Object Recognition. In IROS, September 2011. 2
[3] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urta-
sun. Monocular 3d object detection for autonomous driving.
In IEEE CVPR, 2016. 2, 5, 6, 7
[4] X. Chen, K. Kundu, Y. Zhu, A. Berneshawi, H. Ma, S. Fidler,
and R. Urtasun. 3d object proposals for accurate object class
detection. In NIPS, 2015. 2, 5, 6, 7
[5] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d
object detection network for autonomous driving. In IEEE
CVPR, 2017. 1, 2, 3, 4, 5, 6, 7, 8
[6] C. Choi, Y. Taguchi, O. Tuzel, M. Y. Liu, and S. Rama-
lingam. Voting-based pose estimation for robotic assembly
using a 3d sensor. In 2012 IEEE International Conference
on Robotics and Automation, pages 1724–1731, 2012. 2
[7] C. S. Chua and R. Jarvis. Point signatures: A new repre-
sentation for 3d object recognition. International Journal of
Computer Vision, 25(1):63–85, Oct 1997. 2
[8] C. Dorai and A. K. Jain. Cosmos-a representation scheme for
3d free-form objects. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 19(10):1115–1130, 1997. 2
[9] M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner.
Vote3deep: Fast object detection in 3d point clouds using
efficient convolutional neural networks. In 2017 IEEE In-
ternational Conference on Robotics and Automation (ICRA),
pages 1355–1361, May 2017. 1, 2
[10] M. Enzweiler and D. M. Gavrila. A multilevel mixture-of-
experts framework for pedestrian classification. IEEE Trans-
actions on Image Processing, 20(10):2967–2979, Oct 2011.
3
[11] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for au-
tonomous driving? the kitti vision benchmark suite. In
Conference on Computer Vision and Pattern Recognition
(CVPR), 2012. 1, 2, 5, 6
[12] R. Girshick. Fast r-cnn. In Proceedings of the 2015 IEEE
International Conference on Computer Vision (ICCV), ICCV
’15, 2015. 5, 6
[13] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich fea-
ture hierarchies for accurate object detection and semantic
segmentation. In Proceedings of the IEEE conference on
computer vision and pattern recognition, pages 580–587,
2014. 1
[14] R. Gomez-Ojeda, J. Briales, and J. Gonzalez-Jimenez. Pl-
svo: Semi-direct monocular visual odometry by combining
points and line segments. In 2016 IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS), pages
4211–4216, Oct 2016. 1
[15] A. Gonzalez, G. Villalonga, J. Xu, D. Vazquez, J. Amores,
and A. Lopez. Multiview random forest of local experts com-
bining rgb and lidar data for pedestrian detection. In IEEE
Intelligent Vehicles Symposium (IV), 2015. 1, 2
[16] A. Gonzlez, D. Vzquez, A. M. Lpez, and J. Amores. On-
board object detection: Multicue, multimodal, and multiview
random forest of local experts. IEEE Transactions on Cyber-
netics, 47(11):3980–3990, Nov 2017. 3
[17] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning
for image recognition. In 2016 IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages 770–
778, June 2016. 2, 6
[18] A. G. Howard. Some improvements on deep convolu-
tional neural network based image classification. CoRR,
abs/1312.5402, 2013. 6
[19] A. E. Johnson and M. Hebert. Using spin images for efficient
object recognition in cluttered 3d scenes. IEEE Transactions
on Pattern Analysis and Machine Intelligence, 21(5):433–
449, 1999. 2
[20] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet
classification with deep convolutional neural networks. In
F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger,
editors, Advances in Neural Information Processing Systems
25, pages 1097–1105. Curran Associates, Inc., 2012. 1, 6
[21] B. Li. 3d fully convolutional network for vehicle detection
in point cloud. In IROS, 2017. 1, 2, 5, 7
[22] B. Li, T. Zhang, and T. Xia. Vehicle detection from 3d lidar
using fully convolutional network. In Robotics: Science and
Systems, 2016. 1, 2, 5, 7
[23] T. Lin, P. Goyal, R. B. Girshick, K. He, and P. Doll ́ar. Focal
loss for dense object detection. IEEE ICCV, 2017. 4
[24] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y.
Fu, and A. C. Berg. Ssd: Single shot multibox detector. In
ECCV, pages 21–37, 2016. 2
[25] A. Mian, M. Bennamoun, and R. Owens. On the repeata-
bility and quality of keypoints for local feature-based 3d ob-
ject retrieval from cluttered scenes. International Journal of
Computer Vision, 89(2):348–361, Sep 2010. 2
[26] Y.-J. Oh and Y. Watanabe. Development of small robot for
home floor cleaning. In Proceedings of the 41st SICE Annual
Conference. SICE 2002., volume 5, pages 3222–3223 vol.5,
Aug 2002. 1
[27] Y. Park, V. Lepetit, and W. Woo. Multiple 3d object tracking
for augmented reality. In 2008 7th IEEE/ACM International
Symposium on Mixed and Augmented Reality, pages 117–
120, Sept 2008. 1
[28] C. Premebida, J. Carreira, J. Batista, and U. Nunes. Pedes-
trian detection combining RGB and dense LIDAR data. In
IROS, pages 0–1. IEEE, Sep 2014. 1, 2
[29] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep
learning on point sets for 3d classification and segmentation.
Proc. Computer Vision and Pattern Recognition (CVPR),
IEEE, 2017. 1
[30] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep
hierarchical feature learning on point sets in a metric space.
arXiv preprint arXiv:1706.02413, 2017. 1
[31] J. Redmon and A. Farhadi. YOLO9000: better, faster,
stronger. In IEEE Conference on Computer Vision and Pat-
tern Recognition (CVPR), 2017. 2
[32] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: To-
wards real-time object detection with region proposal net-
works. In Advances in Neural Information Processing Sys-
tems 28, pages 91–99. 2015. 2, 3, 4, 5
[33] R. B. Rusu, N. Blodow, and M. Beetz. Fast point feature
histograms (fpfh) for 3d registration. In 2009 IEEE Interna-
tional Conference on Robotics and Automation, pages 3212–
3217, 2009. 2
[34] J. Shotton, A. Fitzgibbon, M. Cook, T. Sharp, M. Finoc-
chio, R. Moore, A. Kipman, and A. Blake. Real-time human
pose recognition in parts from single depth images. In CVPR
2011, pages 1297–1304, 2011. 2
[35] K. Simonyan and A. Zisserman. Very deep convolu-
tional networks for large-scale image recognition. CoRR,
abs/1409.1556, 2014. 6
[36] S. Song and M. Chandraker. Joint sfm and detection cues for
monocular 3d localization in road scenes. In IEEE Confer-
ence on Computer Vision and Pattern Recognition (CVPR),
pages 3734–3742, June 2015. 2
[37] S. Song and J. Xiao. Sliding shapes for 3d object detection in
depth images. In European Conference on Computer Vision,
Proceedings, pages 634–651, Cham, 2014. Springer Interna-
tional Publishing. 1, 2
[38] S. Song and J. Xiao. Deep Sliding Shapes for amodal 3D
object detection in RGB-D images. In CVPR, 2016. 1, 2, 4,
5
[39] F. Stein and G. Medioni. Structural indexing: efficient 3-d
object recognition. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 14(2):125–145, 1992. 2
[40] O. Tuzel, M.-Y. Liu, Y. Taguchi, and A. Raghunathan. Learn-
ing to rank 3d features. In 13th European Conference on
Computer Vision, Proceedings, Part I, pages 520–535, 2014.
2
[41] D. Z. Wang and I. Posner. Voting for voting in online point
cloud object detection. In Proceedings of Robotics: Science
and Systems, Rome, Italy, July 2015. 1, 2
[42] Y. Xiang, W. Choi, Y. Lin, and S. Savarese. Data-driven
3d voxel patterns for object category recognition. In Pro-
ceedings of the IEEE International Conference on Computer
Vision and Pattern Recognition, 2015. 2
[43] M. Z. Zia, M. Stark, B. Schiele, and K. Schindler. De-
tailed 3d representations for object recognition and model-
ing. IEEE Transactions on Pattern Analysis and Machine
Intelligence, 35(11):2608–2623, 2013. 2
[44] M. Z. Zia, M. Stark, and K. Schindler. Are cars just 3d
boxes? jointly estimating the 3d shape of multiple objects.
In 2014 IEEE Conference on Computer Vision and Pattern
Recognition, pages 3678–3685, June 2014. 2