
大規模分層多檢視RGB-D物件資料集
原文名稱:A Large-Scale Hierarchical Multi-View RGB-D Object Dataset
摘要-在過去的十年中,公共影象庫和識別基準的可用性使得在視覺物件類別和例項檢測方面取得了快速的進展。今天,我們正在見證新一代感測技術的誕生,該技術能夠提供高質量的同步視訊的顏色和深度,RGB-D(Kinect.)相機。憑藉其先進的感測能力和大規模採用的潛力,這項技術代表了顯著提高機器人物件識別、操縱、導航和互動能力的機會。在本文中,我們介紹了一個大規模的,多層次的多檢視物件資料集使用RGB-D相機收集。該資料集包含300個被組織成51個類別的物件,並且已經向研究社群公開,以便基於這一有希望的技術實現快速進展。本文描述了資料集的採集過程,並介紹了基於RGB-D的物件識別和檢測技術,表明結合顏色和深度資訊可以顯著提高結果的質量。
一、引言
公共影象庫在Web上的可用性,如谷歌影象和Flickr,以及視覺識別基準,如加州理工學院101(9)、LabelMe(24)和IMANETET(7),使得視覺物件類別和例項檢測在過去的十年中取得了快速的進展。類似地,機器人資料集儲存庫RADISH[16]極大地提高了機器人研究人員開發和比較其SLAM技術的能力。今天,我們正在見證新一代感測技術的誕生,該技術能夠提供高質量的同步視訊的顏色和深度,RGB-D(Kinect-.)相機[23],[19]。
憑藉其先進的感測能力,以及最初由Microsoft Kinect[19]驅動的消費者大規模採用的潛力,這項技術代表了顯著提高機器人物件識別、操縱、導航和互動能力的機會。在本文中,我們介紹了一個大規模的,多層次的多檢視物件資料集使用RGB-D相機收集。資料集及其伴隨的分割和視訊註釋軟體已經向研究界公開提供,以使得基於這種有前途的技術的快速進展成為可能。資料集在http://www.cs.washington.edu/rgbd-dataset。

不同於許多使用網際網路照片構建的現有識別基準,其中不可能跟蹤不同影象中的物件是否是物理上相同的物件,我們的資料集由一組物件的多個檢視組成。這類似於由SavaReSe等人提出的3D物件類別資料集。(25)包含8個物件類別,每個類別中有10個物件,每個物件有24個不同的檢視。這裡給出的RGB-D物件資料集的規模要大得多,其中RGB和深度視訊序列來自多個視角的300個常見日常物件,總共有250000RGB-D影象。利用WordNet Hynym/HyyNym關係將物件組織成層次的類別結構。
除了引入一個大的物件資料集之外,我們還介紹了基於RGB-D的物件識別和檢測技術,並證明結合顏色和深度資訊可以顯著地改善我們在資料集上獲得的結果。我們評估我們的技術在兩個層面上。類別級別的識別和檢測包括將先前未看到的物件分類為屬於與先前已看到的物件(例如,咖啡杯)相同的類別。例項級別的識別和檢測是識別一個物件是否在物理上是以前見過的相同物件。如果我們想在服務機器人等任務的上下文中使用這種識別系統,那麼在這兩個層次上識別和檢測物件的能力是很重要的。例如,根據任務的上下文,將物件標識為一般咖啡杯或Amelias咖啡杯可能具有不同的含義。在本文中,我們使用Word例項來引用單個物件。


二、RGB-D物件資料集的收集
RGB-D物件資料集包含從多個檢視拍攝的300個物理上不同的物件的視覺和深度影象。所選擇的物件通常在家庭和辦公環境中發現,其中個人機器人預期操作。物件被組織成從WordNet超名/下義關係獲取的層次結構,並且是ImageNet[7]中類別的子集。圖2顯示了物件類別層次結構中的幾個子樹。水果和蔬菜都是層級中的頂級子樹。裝置和容器都是儀器範疇內的子樹,它們覆蓋了非常廣泛的人造物體。資料集中的300個物件中的每一個都屬於這個層次結構中的51個葉子節點中的一個,每個類別中有3-14個例項。葉節點在圖2中為陰影藍色,每個類別中的物件例項的數目用括號給出。圖3顯示了來自資料集的一些示例物件。每個顯示的物件來自51個物件類別中的一個。雖然背景在這些影象中是可見的,但資料集也提供分段掩碼(參見圖4)。使用組合視覺和深度線索的分割過程在第III部分中描述。
使用由PrimeSense[23]製造的原型RGB-D相機和Point Grey Research的火焰相機組成的感測裝置收集資料集。
RGB-D相機同時記錄彩色影象和深度影象,解析度為640×480解析度。換句話說,RGB-D幀中的每個畫素包含四個通道:紅色、綠色、藍色和深度。物理空間中的每個畫素的3D位置可以使用已知的感測器引數計算。
RGB-D相機通過連續投影不可見的紅外結構光圖案和執行立體三角測量來建立深度影象。與被動多攝像機立體技術相比,這種主動投影方法導致更可靠的深度讀數,特別是在無紋理區域。圖1(頂部)示出由RGB影象和深度影象組成的單個RGB-D幀。與RGB-D相機一起提供的驅動軟體確保RGB和深度影象對齊和時間同步。除了RGB-D相機,我們還使用安裝在RGB-D相機上方的點灰研究蚱蜢相機記錄資料,提供更高解析度(1600×1200)的RGB影象。使用Matlab的攝像機校準工具箱校準這兩個攝像機〔2〕。為了同步來自兩個相機的影象,我們使用影象時間戳將每個草蜢影象與RGB-D幀相關聯,RGB-D幀在時間上最接近。RGBD相機收集資料在20赫茲,而蚱蜢具有更低的幀率AROND 12赫茲。圖1(底部)顯示了碗的放大部分,顯示了RGB-D相機和點灰蚱蜢的影象解析度之間的差異。
使用這種攝像機設定,我們記錄每個物件的視訊序列,因為它在轉盤上以恆定速度旋轉。攝像機放在離轉檯大約1米的地方。這是RGB-D相機返回可靠深度讀數所需的最小距離。用安裝在相對於轉檯三個不同高度、地平線以上大約30、45_和60_處的相機記錄資料。在每個高度記錄每一個物體的一次旋轉。每個視訊序列以20Hz記錄並且包含大約250幀,在RGB-D物件資料集中給出總共250000RGB+深度幀。通過跟蹤轉檯上的紅色標記,視訊序列都以[0;2π]之間的地面真實物體姿態角進行註釋。為每個類別選擇參考姿態,使得姿態角在類別中的物件的視訊序列中是一致的。例如,所有咖啡杯的視訊都被標記為手柄右邊的影象為0μm。
三、分割
在沒有任何後處理的情況下,RGB-D視訊幀的大部分被背景佔據。我們使用視覺線索、深度線索,以及轉檯和攝像機之間的配置的粗略知識,從視訊序列中產生完全分割的物件。
分割的第一步是根據轉檯和照相機之間的已知距離,通過只取3D邊界框內的點來去除大部分的背景。這個修剪修剪大部分在背景中很遠的畫素,只留下轉盤和物體。利用物體位於轉檯表面之上的事實,我們可以執行RANSAC平面擬合[11]來找到轉檯平面,並將位於轉檯表面之上的點作為物體。
這個過程為資料集中的許多物件提供了非常好的分割,但是對於小的、暗的、透明的和反射的物件仍然存在問題。由於深度影象中的噪聲,在RANSAC平面擬合過程中,像橡皮擦和標記之類的細小物體的部分可能被合併到表中。暗色、透明和反射物件導致深度估計失敗,導致畫素只包含RGB但不包含深度資料。如果我們只使用深度線索,這些畫素將被排除在分割之外。因此,我們也應用基於視覺的背景減法來生成另一個分割。圖4的頂行示出了基於深度的分割的幾個例子。幾個物體被正確分割,但是缺少深度讀數導致水瓶、罐子和標記蓋的大部分被排除。
為了進行基於視覺的背景減除,我們採用了KaewTraKulPong等人的自適應高斯混合模型[18],並在OpenCV庫中使用了該實現。場景中的每個畫素用k高斯混合建模,當視訊序列逐幀播放時更新。該模型是自適應的,並且只依賴於最近幀的視窗W。如果當前幀中的畫素的值與混合物中的所有高斯值超過標準偏差,則將其分類為前景。對於我們的物件分割,我們使用k=2,w=200,和Sig==5。圖4的中間行顯示了視覺背景減法的幾個例子。該方法很好地分割出物體的邊緣,並且可以分割出深度沒有達到的物體的部分。然而,它往往會遺漏顏色一致的物體的中心,例如圖4中的桃子,並拾取轉盤上的移動陰影和標記。
由於基於深度和基於視覺的分割都在不同條件下分割物件,所以我們結合這兩個來生成最終的物件分割。我們以深度分割為出發點。然後,我們通過檢查它們的深度值,從不在背景中的視覺分割中也在轉檯上新增畫素。最後,在該分割掩模上執行濾波器以去除孤立畫素。圖4的底部行示出使用組合深度和視覺分割的分割結果。組合過程為所有物件提供高質量分割。
四、視訊場景註釋
除了使用轉盤記錄的物件的檢視之外,RGB-D物件資料集還包括8個自然場景的視訊序列。這些場景覆蓋了常見的室內環境,包括辦公室工作區、會議室和廚房區域。在每一個場景中漫步時,通過將RGB-D相機保持在近似人眼高度來記錄視訊序列。每個視訊序列包含來自RGB-D物件資料集的多個物件。物件是從不同的視點和距離可見的,並且可以在部分幀中部分或完全閉塞。圖7總結了每個視訊序列中的幀數目和物件數目。在第六節中,我們演示了RGB-D物件資料集可以用作在這些自然場景中執行物件檢測的訓練資料。這裡,我們將首先描述如何用RGB-D物件資料集中的物件的地面真值邊界框來註釋這些自然場景。傳統上,計算機視覺社群一次一幀地註釋視訊序列。人類必須使用註釋軟體(比如LabelMe註釋工具[24],以及最近的vatic[26])來冗長地分割每個影象中的物件。
跨視訊幀的時間插值可以稍微緩解這種情況,但只有在相機軌跡複雜的情況下,對小幀序列的時間插值才有效。眾包(例如,.calTurk)也可以縮短註釋時間,但是僅僅通過將工作分發給更多的人來縮短註釋時間。我們提出了另一種方法。代替標記每個視訊幀,我們首先將視訊序列拼接在一起,以建立整個場景的3D重建,同時跟蹤每個視訊幀的相機姿態。我們用手標註這個3D重建中的物體。
圖5示出了一個廚房場景的重建,一個藍色的帽子和一個用紅色標記的蘇打罐頭。最後,在每個視訊幀中,標記的3D點被投影回已知的攝像機姿態,並且這個分割可以用於計算物件邊界框。圖6示出了通過將圖5中的標記的3D點投影到多個視訊幀而獲得的一些邊界框。



我們的標籤工具使用亨利等人提出的技術。〔15〕從RGBD視訊幀中構建三維場景模型。RGB-D對映技術包括兩個關鍵部分:1)連續視訊幀的空間對齊,2)完整視訊序列的全域性一致對齊。通過對外觀和形狀匹配進行聯合優化來排列連續幀。
基於外觀的對準是用RANSAC在SIFT特徵上用3D位置(3D SIFT)標註的。使用基於點對平面誤差度量(5)的迭代最近點(ICP)來執行基於形狀的對準。從3D SIFT匹配的初始對準用於初始化基於ICP的對準。Henry等人[15]表明,這允許系統處理僅憑視覺或形狀無法產生良好對準的情況。通過使用3D SIFT將視訊幀與先前收集的幀的子集匹配來執行環路閉包。全球一致的對齊產生與TROO,PosiGrand優化工具開發的機器人SLAM〔13〕。
整個場景是使用小彩色表面補丁稱為Surfel[22 ],而不是保持所有的原始3D點。這種表示能夠為環境的每個部分進行關於遮擋和顏色的有效推理,並提供結果模型的良好視覺化。標記工具在這個Surfel-Posits中顯示場景。
當用戶選擇要標記為物件的一組surfel時,使用在場景重建過程中計算的變換將它們投影回每個視訊幀。Surfels允許有效的遮擋推理來確定標記物件在幀中是否可見,如果是,則生成邊界框。
五、利用RGB-D物件資料集進行物體識別
此任務的目標是測試當分割良好或裁剪好的物件影象可用時,結合RGB和深度是否有幫助。據我們所知,這裡給出的RGBD物件資料集是最大的物件多檢視資料集,其中為每個檢視提供RGB和深度影象。為了演示同時具有RGB和深度資訊的實用性,在本節中,我們使用幾個不同的分類器對RGB-D物件資料集呈現物件識別結果,這些分類器僅具有形狀特徵、僅具有視覺特徵,並且具有形狀和視覺特徵。
在物件識別中,任務是給每個查詢影象分配標籤(或類)。可能被指派的可能標籤是提前知道的。處理這一問題的最先進的方法通常是監督學習系統。一組影象用它們的基本真值標籤進行註釋,並交給分類器,分類器學習用於區分不同類的模型。我們評估物件識別效能在兩個級別:類別識別和例項識別。在類別級識別中,系統被訓練在一組物件上。在測試時,系統被呈現為RGB和深度影象對,其中包含訓練中不存在的物件,並且任務是為影象(例如,咖啡杯或汽水罐)分配類別標籤。在例項級識別中,系統對每個物件的檢視子集進行訓練。這裡的任務是區分物件例項(例如百事可樂,山露罐,或AQUAFINA水瓶)。在測試時,系統將呈現一個RGB和深度影象對,該影象對包含一個物件的先前未看到的檢視,並且必須為影象分配例項標籤。
我們通過拍攝每第五個視訊幀對轉盤資料進行二次取樣,得到大約45000個RGB-D影象。對於類別識別,我們從每個類別中隨機地留下一個物件來測試,並針對剩餘物件的所有檢視訓練分類器。例如識別,我們考慮兩種情況:
•交替相鄰幀:將每個視訊分割成等長的3個連續序列。每個物件有3個高度(視訊),所以這為每個例項提供了9個視訊序列。我們隨機選擇其中的7個用於訓練和測試剩下的2個。
•離開序列:對安裝在地平線以上30_和60_的每個物體的視訊序列進行訓練,並對45_視訊序列進行評價
我們的平均精度跨越10個試驗類別識別和例項識別與交替相鄰幀。在資料拆分中沒有隨機性,所以我們報告單個試驗的數字。
每個影象都是一個物件的檢視,我們提取一組捕獲檢視形狀的特徵和另一組捕獲視覺外觀的特徵。我們使用最先進的特徵,包括來自形狀檢索社群的自旋影象[17]和來自計算機視覺社群的SIFT描述符[21]。從物理空間中每個深度畫素的3D位置提取形狀特徵,用攝像機座標系表示。我們首先計算隨機取樣的3D點集的自旋影象。每個自旋影象以3D點為中心,捕捉其鄰域內點的空間分佈。在二維16×16直方圖中捕獲的分佈對於點法線的旋轉是不變的。我們使用這些自旋影象來計算有效匹配核(EMK)特徵,使用隨機傅立葉集,如在[1 ]中提出的。EMK特徵與詞袋特徵(BOW)類似,因為它們都取一組區域性特徵(這裡是旋轉影象)並生成描述包的固定長度特徵向量。EMK近似於區域性特徵之間的高斯核,並給出相似性的連續度量。為了結合空間資訊,我們將每個檢視周圍的軸對齊包圍立方體劃分為3×3×3網格。我們分別在27個細胞中計算一個1000維EMK特徵。我們對每個單元中的EMK特徵進行主成分分析(PCA),並採用前100個分量。最後,我們將三維特徵包圍盒的寬度、深度和高度作為形狀特徵。這給了我們一個2703維形狀描述符。

為了捕獲檢視的視覺外觀,我們在8×8個單元的密集網格上提取SIFT。為了生成影象特徵和捕獲空間資訊,我們在兩個影象尺度上計算EMK特徵。首先,我們使用來自整個影象的SIFT描述符計算1000維EMK特徵。然後將影象分割成2×2網格,分別從單元內的SIFT特徵計算單元內的EMK特徵。我們在每個單元上執行PCA,並取前300個分量,給出1500維EMK SIFT特徵向量。此外,我們提取紋理直方圖[20]特徵,這些特徵使用定向高斯濾波器響應捕獲紋理資訊。TeXTon詞彙是由LabelMe上的一組獨立的影象構建的。最後,我們包括顏色直方圖,並且還使用每個顏色通道的平均值和標準偏差作為視覺特徵。
我們評估了三種最先進的分類器:線性支援向量機(LinSVM)、高斯核支援向量機(kSVM)[8]、[4]、隨機森林(RF)[3]、[12]。圖8顯示了這些分類器只使用形狀特徵、只使用視覺特徵以及同時使用形狀和視覺特徵的分類效能。總體視覺特徵對於形狀級別和例項級識別都比形狀特徵更有用。然而,形狀特徵在類別識別中相對更有用,而視覺特徵在例項識別中相對更有效。
這正是我們所期望的,因為特定物件例項在檢視之間具有相當恆定的視覺外觀,而相同類別中的物件可以具有不同的紋理和顏色。另一方面,形狀往往是穩定的橫跨一個類別在許多情況下。最有趣和最有意義的結論是,不管分類技術如何,組合形狀和視覺特徵都能夠提供更高的總體分類級別的效能。這些特性相互補充,顯示了可以提供形狀和視覺資訊的大規模資料集的價值。對於交替的連續幀例項識別,單獨使用視覺特徵已經給出非常高的精度,因此包括形狀特徵不會提高效能。遺漏序列外評估更具挑戰性,在這裡組合形狀和視覺特徵顯著提高了準確性。
我們還在相同的實驗設定下使用相同的特徵集執行最近鄰分類器,發現它的效能比基於學習的方法差得多。例如,當使用所有特徵時,它在休假序列外例項識別上的效能是43:2%,比圖8中報告的準確性差得多。

六.使用RGB-D物件資料集進行物件檢測
現在,我們演示瞭如何使用RGB-D物件資料集來執行真實世界場景中的物件檢測。給定影象,物件檢測任務是識別和定位所有感興趣的物件。與物件識別一樣,物件屬於固定的類標籤集合。物件檢測任務也可以在類別和例項級別上執行。我們的目標檢測系統基於標準滑動視窗方法[6]、[10]、[14],其中系統評估影象中所有位置和尺度的得分函式,並對得分進行閾值化以獲得目標邊界框。每個檢測器視窗是固定大小的,我們在影象金字塔上搜索20個尺度。為了提高效率,我們考慮線性評分函式(因此卷積可用於影象金字塔的快速評價)。我們執行非最大抑制,以消除多個重疊檢測。
設H為特徵金字塔,P為子視窗的位置。p是三維向量:前兩個維度是子視窗的左上角,第三個維度是影象的尺度。我們的得分函式是

其中w是濾波器(權重),b是偏置項,φ(H;p)是位置p處的特徵向量。我們使用線性支援向量機(SVM)訓練濾波器w:
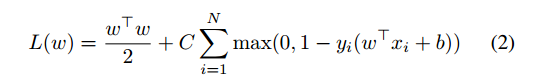
其中N是訓練集大小,Yi 2 F=1;1G標籤,XI特徵向量在裁剪影象上,C是權衡引數。
分類器的效能很大程度上取決於用於訓練它的資料。對於物體檢測,有許多潛在的負面例子。單個影象可用於生成滑動視窗分類器的105個負值示例。因此,我們遵循Bootstrap硬負挖掘過程。正例是我們感興趣的物件視窗。從背景影象和其他類別/例項的物件影象中隨機選擇初始陰性例項。訓練的分類器用於搜尋影象並選擇具有最高分數(硬底片)的假陽性。然後將這些硬底片新增到負值集,並重新分類分類器。此過程重複5次以獲得最終分類器。


作為特徵,我們使用定向梯度直方圖(HOG)[10]的變體,這已經被發現比原始HOG稍微好一些。該版本考慮了對比度敏感和不敏感特性,其中每個單元(8×8畫素網格)中的梯度方向分別使用兩個不同的量化級別編碼為18(0_360)和9個方向箱(0_180)。這產生了4×(18+9)=108維特徵向量。使用完整的108維特徵向量的31-D解析投影。前27個維度對應於不同的取向通道(18對比敏感度和9對比度不敏感)。最後4個維度捕獲了2×2個細胞的四個區塊中的總梯度能量。
除了HOG over RGB影象,我們還計算HOG over深度影象,其中每個畫素值都是實際的物體到攝像機的距離。在提取HOG特徵之前,我們需要在深度影象中填充缺失值。
由於缺少的值往往被分組在一起,我們在這裡開發一個遞迴中值濾波器。我們沒有考慮所有相鄰畫素值,而是取以當前畫素為中心的5×5網格中非缺失值的中值。我們遞迴地應用這個中值濾波器,直到所有丟失的值都被填充。在圖9中示出了示例原始深度影象和濾波深度影象。
最後,我們還計算捕獲物件的尺度(真尺寸)的特徵。我們觀察到物體到攝像機的距離d與其標度o成反比。對於特定標度s的影象,我們有c=o *s/d,其中c是常數。在滑動視窗方法中,檢測器視窗是固定的,這意味著O是固定的。因此,我們稱之為歸一化深度的D/S是常數。由於深度是嘈雜的,我們使用8×8網格的歸一化深度直方圖來獲取尺度資訊。對於給定影象中的每個畫素,d是固定的,因此歸一化深度直方圖可以從影象金字塔中選擇正確的影象尺度。
我們使用了20個桶的直方圖,每個桶的範圍為0.15m。〔14〕使用深度資訊來定義得分函式。然而,利用深度資訊的方法與我們的方法非常不同:HelMet等人。使用深度資訊作為先驗,而我們構建一個尺度直方圖特徵從歸一化深度值。
我們針對第四節描述的8個自然場景視訊序列評估了上述目標檢測方法。由於連續幀非常相似,因此我們對視訊資料進行子取樣,並在每5幀執行我們的檢測演算法。我們構建了4個類別級別檢測器(碗、帽、咖啡杯、汽水罐)和20個來自同一類別的例項級別檢測器。我們遵循PASCAL視覺物件挑戰(VOC)評價指標。如果預測邊界框和地面真值邊界框的交叉點的大小超過它們聯合的大小的一半,則認為候選檢測是正確的。對於相同的基本事實,多次成功檢測中只有一次被認為是正確的,其餘的被認為是假陽性。我們報告了精確召回曲線和平均精度,它是由精確召回曲線計算的,並且是曲線下面積的近似值。對於多個類別/例項檢測,我們將跨類別/例項和影象的所有候選檢測彙總,以生成單個精度-召回曲線。
在圖10中,我們顯示了將檢測效能與只使用影象特徵(紅色)、只使用深度特徵(綠色)和兩者(藍色)訓練的分類器進行比較的精確召回曲線。我們發現深度特徵(HOG在深度影象和歸一化深度直方圖)比RGB影象上的HOG要好得多。其主要原因是在深度影象中,強梯度主要來自真實物體邊界(參見圖9),與RGB影象上的HOG相比,這導致更少的假陽性,其中顏色變化也可能導致強梯度。通過結合影象和深度特徵來獲得最佳效能。如果沒有可比性,該組合在所有召回級別上比僅影象和深度給出更高的精度。特別是,當需要高召回時,結合影象和深度特徵提供了更高的精度。
圖11示出了三個場景中的多目標檢測結果。最左邊的場景包含從與訓練資料中明顯不同的視點觀察到的三個物件。多類別檢測器能夠正確地檢測所有三個物體,包括部分被穀物盒遮擋的碗。中間場景顯示了一個雜亂的場景中有許多分散物件的分類級別檢測。該系統能夠正確地檢測除了遠離相機的部分被遮擋的白色碗之外的所有物體。請注意,檢測器能夠識別同一類別的多個例項(瓶蓋和汽水罐)。
最右邊的場景顯示雜亂場景中的例項級檢測。在這裡,該系統能夠正確地檢測到碗和帽,即使帽部分閉塞的碗。我們當前的單執行緒實現大約需要10秒來執行四個物件檢測器來標記每個場景。在規則網格上進行特徵提取和評估滑動視窗檢測器都很容易並行化。我們相信,基於GPU的實現所描述的方法可以執行多目標實時檢測。
七。討論
在本文中,我們提出了一個大規模的,多層次的多檢視物件資料集使用RGB-D相機收集。通過三維重建、目標識別和目標檢測,證明了深度資訊對背景減除、視訊地面真值標註等都有很大的幫助。RGB-D物件資料集和一組完全整合到機器人作業系統(ROS)中的用於訪問和處理資料集的工具,可以在http://www.cs.washington.edu/rgbd-dataset.
REFERENCES
[1] L. Bo and C. Sminchisescu. Efficient Match Kernel between Sets of Features for Visual Recognition. In Advances in Neural Information Processing Systems (NIPS), December 2009.
[2] Jean-Yves Bouguet. Camera calibration toolbox for matlab. http: //www.vision.caltech.edu/bouguetj/calib_doc/.
[3] Leo Breiman. Random forests. Machine Learning, 45(1):5–32, 2001.
[4] Chih-Chung Chang and Chih-Jen Lin. LIBSVM: a library for support vector machines, 2001.
[5] Y. Chen and M. Gerard. Object modelling by registration of multiple range images. Image Vision Comput., 10(3):145–155, 1992.
[6] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2005.
[7] J. Deng, W. Dong, R. Socher, L. Li, K. Li, and L. Fei-fei. ImageNet:A Large-Scale Hierarchical Image Database. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009.
[8] R. Fan, K. Chang, C. Hsieh, X. Wang, and C. Lin. Liblinear: A library for large linear classification. Journal of Machine Learning Research (JMLR), 9:1871–1874, 2008.
[9] L. Fei-Fei, R. Fergus, and P. Perona. One-shot learning of object categories. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 28(4):594–611, 2006.
[10] P. Felzenszwalb, D. McAllester, and D. Ramanan. A discriminatively trained, multiscale, deformable part model. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2008.
[11] Martin A. Fischler and Robert C. Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM, 24(6):381–395, 1981.
[12] Yoav Freund and Robert E. Schapire. Experiments with a new boosting algorithm. In International Conference on Machine Learning (ICML), pages 148–156, 1996.
[13] G. Grisetti, S. Grzonka, C. Stachniss, P. Pfaff, and W. Burgard. Estimation of accurate maximum likelihood maps in 3d. In IEEE International Conference on Intelligent Robots and Systems (IROS), 2007.
[14] Scott Helmer and David G. Lowe. Using stereo for object recognition. In IEEE International Conference on Robotics & Automation (ICRA), pages 3121–3127, 2010.
[15] P. Henry, M. Krainin, E. Herbst, X. Ren, and D. Fox. RGB-D Mapping: Using depth cameras for dense 3D modeling of indoor environments. In the 12th International Symposium on Experimental Robotics (ISER), December 2010.
[16] A. Howard and N. Roy. The robotics data set repository (radish), 2003.
[17] A. Johnson and M. Hebert. Using spin images for efficient object recognition in cluttered 3D scenes. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 21(5), 1999.
[18] P. Kaewtrakulpong and R. Bowden. An improved adaptive background mixture model for realtime tracking with shadow detection. In European Workshop on Advanced Video Based Surveillance Systems, 2001.
[19] Microsoft Kinect. http://www.xbox.com/en-us/kinect.
[20] T. Leung and J. Malik. Representing and recognizing the visual appearance of materials using three-dimensional textons. Int. J. Comput. Vision, 43(1):29–44, June 2001.
[21] David G. Lowe. Object recognition from local scale-invariant features. In IEEE International Conference on Computer Vision (ICCV), 1999.
[22] H. Pfister, M. Zwicker, J. van Baar, and M. Gross. Surfels: Surface elements as rendering primitives. In ACM Transactions on Graphics (Proc. of SIGGRAPH), 2000.
[23] PrimeSense. http://www.primesense.com/.
[24] B. Russell, K. Torralba, A. Murphy, and W. Freeman. Labelme: a database and web-based tool for image annotation. International Journal of Computer Vision, 77(1-3), 2008.
[25] S. Savarese and Li Fei-Fei. 3d generic object categorization, localization and pose estimation. In IEEE International Conference on Computer Vision (ICCV), pages 1–8, 2007.
[26] C. Vondrick, D. Ramanan, and D. Patterson. Efficiently scaling up video annotation with crowdsourced marketplaces. In European Conference on Computer Vision (ECCV), 2010.