
hadoop 完全分散式安裝
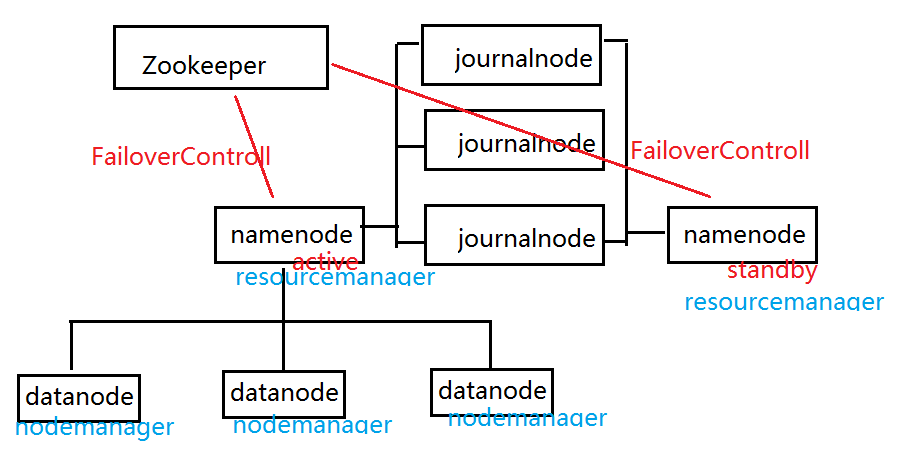
一個完全的hadoop分散式安裝至少需要3個zookeeper,3個journalnode,3個datanode,2個namenode組成。
也就是說需要11個節點,但是我雲主機有限,只有3個,所以把很多節點搭在了同一個伺服器上。

步驟:
1.關閉防火牆
service iptables stop
2.修改主機名
vim /etc/sysconfig/network
三臺主機都需要修改
HOSTNAME=hadoop01 # 第一臺
HOSTNAME=hadoop02 # 第二臺
HOSTNAME=hadoop03 # 第三臺
例如:

3.修改hosts檔案進行對映
vim /etc/hosts
三臺主機都要修改
10.42.127.183 hadoop01 10.42.8.245 hadoop02 10.42.62.96 hadoop03
例如:

4.免密登入
產生祕鑰:ssh-keygen
進行復制:ssh-copy-id 使用者名稱@主機
第一臺主機操作示例:
ssh-keygen
回車
回車
ssh-copy-id [email protected]10.42.127.183
ssh-copy-id [email protected]10.42.8.245
ssh-copy-id [email protected]10.42.62.96
其餘兩臺進行相同操作。
5.重啟三臺伺服器
reboot
6.安裝jdk
7.安裝zookeeper
8.啟動zookeeper
9.安裝hadoop
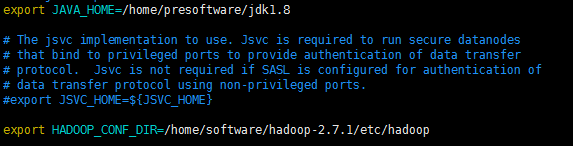
(1) 編輯 hadoop-env.sh,並且重新生效
vim hadoop-env.sh
export JAVA_HOME=/home/presoftware/jdk1.8 export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
(2)編輯 core-site.xml
vim core-site.xml
<!--指定hdfs的nameservice,為整個叢集起一個別名--> <property> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <!--指定Hadoop資料臨時存放目錄--> <property> <name>hadoop.tmp.dir</name> <value>/home/software/hadoop-2.7.1/tmp</value> </property> <!--指定zookeeper的存放地址--> <property> <name>ha.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property>
(3)編輯 hdfs-site.xml
vim hdfs-site.xml
<!--執行hdfs的nameservice為ns,注意要和core-site.xml中的名稱保持一致--> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <!--ns叢集下有兩個namenode,分別為nn1, nn2--> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <!--nn1的RPC通訊--> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>hadoop01:9000</value> </property> <!--nn1的http通訊--> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>hadoop01:50070</value> </property> <!-- nn2的RPC通訊地址 --> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>hadoop02:9000</value> </property> <!-- nn2的http通訊地址 --> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>hadoop02:50070</value> </property> <!--指定namenode的元資料在JournalNode上存放的位置,這樣,namenode2可以從journalnode集 群裡的指定位置上獲取資訊,達到熱備效果--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns</value> </property> <!-- 指定JournalNode在本地磁碟存放資料的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/software/hadoop-2.7.1/tmp/journal</value> </property> <!-- 開啟NameNode故障時自動切換 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失敗自動切換實現方式 --> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔離機制 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔離機制時需要ssh免登陸 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!--配置namenode存放元資料的目錄,可以不配置,如果不配置則預設放到hadoop.tmp.dir下--> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/software/hadoop-2.7.1/tmp/hdfs/name</value> </property> <!--配置datanode存放元資料的目錄,可以不配置,如果不配置則預設放到hadoop.tmp.dir下--> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/software/hadoop-2.7.1/tmp/hdfs/data</value> </property> <!--配置複本數量--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--設定使用者的操作許可權,false表示關閉許可權驗證,任何使用者都可以操作--> <property> <name>dfs.permissions</name> <value>false</value> </property>
(4)編輯 mapred-site.xml
vim mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
(5) 編輯 yarn-site.xml
vim yarn-site.xml
<!--配置yarn的高可用--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--指定兩個resourcemaneger的名稱--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!--配置rm1的主機--> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop01</value> </property> <!--配置rm2的主機--> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop03</value> </property> <!--開啟yarn恢復機制--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--執行rm恢復機制實現類--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <!--配置zookeeper的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> <!--執行yarn叢集的別名--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>ns-yarn</value> </property> <!-- 指定nodemanager啟動時載入server的方式為shuffle server --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定resourcemanager地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop03</value> </property>
(6)編輯 slaves
vim slaves
hadoop01
hadoop02
hadoop03
(7)配置環境變數
vim /etc/profile
export HADOOP_HOME=/home/software/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(8)將hadoop拷貝到另外兩個主機
scp -r hadoop-2.7.1 hadoop02:/home/software/
scp -r hadoop-2.7.1 hadoop03:/home/software/
(9)配置另外兩個主機的環境變數
export HADOOP_HOME=/home/software/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
10.在任意一個節點上進行Zookeeper格式化註冊
hdfs zkfc -formatZK
11.建立指定的目錄
cd hadoop-2.7.1/
mkdir tmp
cd tmp
mkdir journal
mkdir hdfs
cd hdfs/
mkdir data
mkdir name
12.在三臺節點上分別啟動journalnode
hadoop-daemon.sh start journalnode
13.格式化第一個節點
hadoop namenode -format
14.啟動第一個節點的namenode
hadoop-daemon.sh start namenode
15.格式化第二個節點上的namenode
hdfs namenode -bootstrapStandby
16.啟動第二個點的namenode
hadoop-daemon.sh start namenode
17.在三個節點上分別啟動datanode
hadoop-daemon.sh start datanode
18.在第一個節點和第二個節點上啟動zkfc實現狀態的切換
hadoop-daemon.sh start zkfc
19.在第一個節點上啟動yarn
start-yarn.sh
20.在第三個節點上啟動resourcemanager
yarn-daemon.sh start resourcemanager
21.瀏覽器訪問
第一個伺服器:http://10.42.127.183:50070

第二個伺服器:http://10.42.8.245:50070

出現上圖所示即為成功。