
統計學習方法(5)整合學習(提升方法)
統計學習方法(4)整合學習(提升方法)
1、Bagging:
基於並行策略:基學習器之間不存在依賴關係,可同時生成。
基本思路:
- 利用
自助取樣法對訓練集隨機取樣,重複進行 T 次; - 基於每個取樣集訓練一個基學習器,並得到 T 個基學習器;
- 預測時,集體投票決策。
自助取樣法:對 m 個樣本的訓練集,有放回的取樣 m 次; 此時,樣本在 m 次取樣中始終沒被取樣的概率約為 0.368,即每次自助取樣只能取樣到全部樣本的 63% 左右。
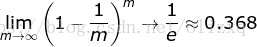
取樣和訓練過程:

特點:
- 訓練每個基學習器時只使用一部分樣本;
- 偏好不穩定的學習器作為基學習器;
- 每一個單獨的分類器在原始訓練集上都是高偏差,但是聚合降低了偏差和方差。
所謂不穩定的學習器,指的是對樣本分佈較為敏感的學習器。
為什麼不穩定的學習器更適合作為基學習器?
- 不穩定的學習器容易受到樣本分佈的影響(方差大),很好的引入了隨機性;這有助於在整合學習(特別是採用 Bagging 策略)中提升模型的泛化能力。
- 為了更好的引入隨機性,有時會隨機選擇一個屬性子集中的最優分裂屬性,而不是全域性最優(隨機森林)。
2、隨機森林:
隨機森林是bagging方法的典型應用,隨機森林演算法是以決策樹演算法為基礎,通過bagging演算法取樣訓練樣本,再抽樣特徵,3者組合成的演算法。對應scikit-learn中為RandomForestClassifier (RandomForestRegression),它有著決策樹(DecisionTreeClassifier)的所有引數,以及bagging(BaggingClassifier)的所有引數。
當處理高維(多特徵)資料(例如: 影象)時,這種方法比較有用。同時對訓練資料和特徵進行抽樣稱為Random Patches,只針對特徵抽樣而不針對訓練資料抽樣是Random Subspaces。
隨機的意義? 不管是對樣本的隨機取樣,還是對特徵的抽樣,甚至對切分點的隨機劃分,都是為了引入偏差,使基分類器之間具有明顯的差異,相互獨立,提升模型的多樣性,使模型不會受到區域性樣本的影響,從而減少方差,提升模型的泛化能力。
3、Boosting:
基於序列策略:基學習器之間存在依賴關係,新的學習器需要根據上一個學習器生成。
基本思路:
- 先從初始訓練集訓練一個基學習器,初始訓練集中各樣本的權重是相同的;
- 根據上一個基學習器的表現,調整樣本權重,使分類錯誤的樣本得到更多的關注;
- 基於調整後的樣本分佈,訓練下一個基學習器;
- 測試時,對各基學習器加權得到最終結果
特點:
- 每次學習都會使用全部訓練樣本
代表演算法:
- AdaBoost 演算法
- GBDT 演算法
4、AdaBoost演算法:


AdaBoost 演算法還有另一個解釋,即可以認為AdaBoost演算法是模型為加法模型、損失函式為指數函式、學習演算法為前向分步演算法時的二類分類學習方法。
- AdaBoost 演算法是前向分步演算法的特例。
- 此時,基函式為基分類器,損失函式為指數函式L(y,f(x)) = exp(-y*f(x))
5、Boosting/Bagging 與 偏差/方差 的關係
-
簡單來說,Boosting 能提升弱分類器效能的原因是
降低了偏差;Bagging 則是降低了方差; -
Boosting 方法:
- Boosting 的基本思路就是在不斷減小模型的
訓練誤差(擬合殘差或者加大錯類的權重),加強模型的學習能力,從而減小偏差; - 但 Boosting 不會顯著降低方差,因為其訓練過程中各基學習器是強相關的,缺少獨立性。
- Boosting 的基本思路就是在不斷減小模型的
-
Bagging 方法:
- 對 n 個獨立不相關的模型預測結果取平均,方差是原來的 1/n;
- 假設所有基分類器出錯的概率是獨立的,超過半數基分類器出錯的概率會隨著基分類器的數量增加而下降。
-
泛化誤差、偏差、方差、過擬合、欠擬合、模型複雜度(模型容量)的關係圖:

參考: 《統計學習方法》 李航