
Python爬蟲(urllib.request和BeautifulSoup)
學習urllib.request和beautifulsoup,並從dribbble和behance上爬取了一些圖片,記錄一下。
一、urllib.request
1. url的構造
構造請求的url遇到的主要問題是如何翻頁的問題,dribbble網站是下拉到底自動載入下一頁,位址列的url沒有變化,如下:

但是通過檢查,我們可以發現request url裡關於page的欄位,如下:
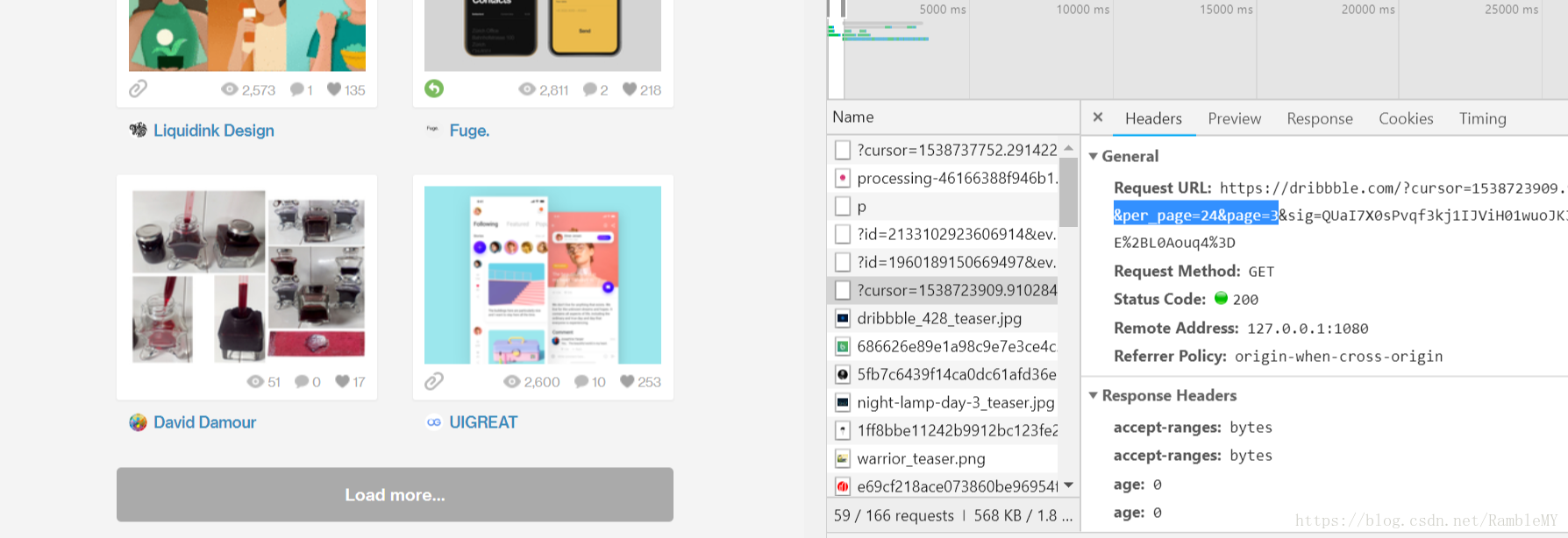
因此,我們構造如下的url:
for i in range(25): # 最多25頁 url = 'https://dribbble.com/shots?page=' + str(i + 1) + '&per_page=24'
2. header的構造
不同網頁需要的header的內容不一樣,參照檢查裡request header來構造。例如dribbble需要Referer,即從哪一個頁面跳轉到這個當前頁面的,一般填寫網站相關頁面網址就可以。
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;", "Referer": "https://dribbble.com/", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36"}
3. urllib.request獲取頁面內容
用url和header例項化一個urllib.request.Request(url, headers),然後url.request.urlopen()訪問網頁獲取資料,使用read()函式即可讀取頁面內容。
def open_url(url): # 將Request類例項化並傳入url為初始值,然後賦值給req headers = {"Accept": "text/html,application/xhtml+xml,application/xml;", "Referer": "https://dribbble.com/", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36"} req = urllib.request.Request(url, headers=headers) # 訪問url,並將頁面的二進位制資料賦值給page res = urllib.request.urlopen(req) # 將page中的內容轉換為utf-8編碼 html = res.read().decode('utf-8') return html
這裡需要注意的是,有的頁面返回的資料是“text/html; charset=utf-8”格式,直接decode('utf-8')編碼即可,而有的頁面返回的是“application/json; charset=utf-8”格式資料,例如behance:

此時就需要json.loads()來獲取資料,得到的是列表,用操作列表的方式拿到html資料:
html = json.loads(res.read())
return html['html']二、BeautifulSoup
BeautifulSoup將複雜的html文件轉換為樹形結構,每一個節點都是一個物件。
1.建立物件
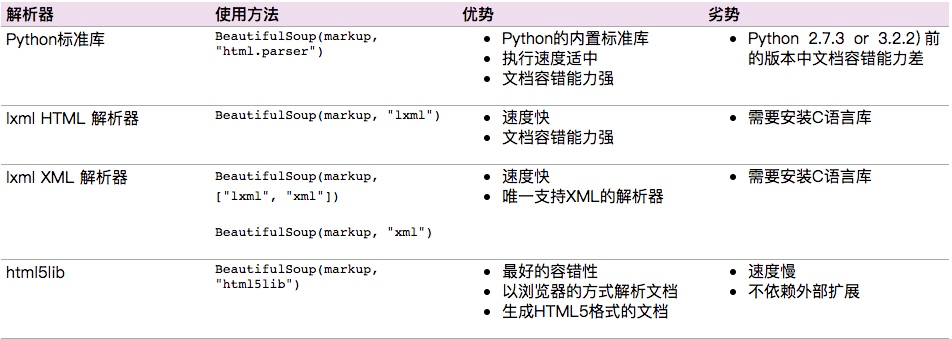
soup = BeautifulSoup(open_url(url), 'html.parser')‘html.parser’是解析器,BeautifulSoup支援Python標準庫中的HTML解析器,還支援一些第三方的解析器,如果我們不安裝它,則 Python 會使用 Python預設的解析器,lxml 解析器更加強大,速度更快,推薦安裝,常見解析器:
2. 標籤選擇器
標籤選擇篩選功能弱但是速度快,通過這種“soup.標籤名” 我們就可以獲得這個標籤的內容,但通過這種方式獲取標籤,如果文件中有多個這樣的標籤,返回的結果是第一個標籤的內容
# 獲取p標籤
soup.p
# 獲取p標籤的屬性的兩種方法
soup.p.attrs['name']
soup.p['name']
# 獲取第一個p標籤的內容
soup.p.string
# 獲取p標籤下所有子標籤,返回一個列表
soup.p.contents
# 獲取p標籤下所有子標籤,返回一個迭代器
for i,child in enumerate(soup.p.children):
print(i,child)
# 獲取父節點的資訊
soup.a.parent
# 獲取祖先節點
list(enumerate(soup.a.parents))
# 獲取後面的兄弟節點
soup.a.next_siblings
# 獲取前面的兄弟節點
soup.a.previous_siblings
# 獲取下一個兄弟標籤
soup.a.next_sibling
# 獲取上一個兄弟標籤
souo.a.previous_sinbling3. 標準選擇器
find_all(name,attrs,recursive,text,**kwargs)可以根據標籤名,屬性,內容查詢文件,返回一個迭代器,例如:
# 獲取所有class為js-project-module--picture的所有img標籤,並選擇每個標籤的src構成一個列表
image.src = [item['src'] for item in soup.find_all('img', {"class": "js-project-module--picture"})]
# .string獲取div的內容,strip()去除前後空格
desc = soup.find_all('div', {"class": "js-basic-info-description"})
if desc:
image.desc = [item.string.strip() for item in desc]find(name,attrs,recursive,text,**kwargs),返回匹配的第一個元素
其他一些類似的用法: find_parents()返回所有祖先節點,find_parent()返回直接父節點 find_next_siblings()返回後面所有兄弟節點,find_next_sibling()返回後面第一個兄弟節點 find_previous_siblings()返回前面所有兄弟節點,find_previous_sibling()返回前面第一個兄弟節點 find_all_next()返回節點後所有符合條件的節點, find_next()返回第一個符合條件的節點 find_all_previous()返回節點後所有符合條件的節點, find_previous()返回第一個符合條件的節點
三、完整程式碼
# -*- coding: utf-8 -*-
"""
批量獲取圖片頁面連結
儲存到 dribbble_list.txt 檔案中
根地址: https://dribbble.com/
"""
import random
import urllib.request
from bs4 import BeautifulSoup
import os
import time
def open_url(url):
# 將Request類例項化並傳入url為初始值,然後賦值給req
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;",
"Referer": "https://dribbble.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36"}
req = urllib.request.Request(url, headers=headers)
# 訪問url,並將頁面的二進位制資料賦值給page
res = urllib.request.urlopen(req)
# 將page中的內容轉換為utf-8編碼
html = res.read().decode('utf-8')
return html
# 開啟/建立“dribbble_list.txt”檔案,O_CREAT:不存在即建立、O_WRONLY:只寫、O_APPEND:追加
fd = os.open('dribbble_list.txt', os.O_CREAT | os.O_WRONLY | os.O_APPEND)
for i in range(25): # 最多25頁
url = 'https://dribbble.com/shots?page=' + str(i + 1) + '&per_page=24'
soup = BeautifulSoup(open_url(url), 'html.parser')
srcs = soup.find_all('a', {"class": "dribbble-link"})
src_list = [src['href'] for src in srcs]
for src in src_list:
os.write(fd, bytes(src, 'UTF-8'))
os.write(fd, bytes('\n', 'UTF-8'))
time.sleep(random.random()*5)