當代網際網路資料庫技術架構的演變
阿新 • • 發佈:2018-12-13
資料庫訪問量很小時,資料庫無需優化,直接使用即可。

但隨著資料量以及訪問量越來越高,在人們的智慧中一步步誕生了如下方案:
1、快取+垂直拆分
使用快取(Memcached、Redis)來緩解資料庫壓力【資料庫的查詢操作次數要遠遠大於增刪改,我們將經常查詢的資料放在快取中,將大大緩解資料庫的壓力】,優化資料庫結構和索引,垂直拆分(當資料量過於龐大,一個數據庫放不下,則需要根據需求,例如根據業務進行拆分,業務1、業務2、業務3...)。

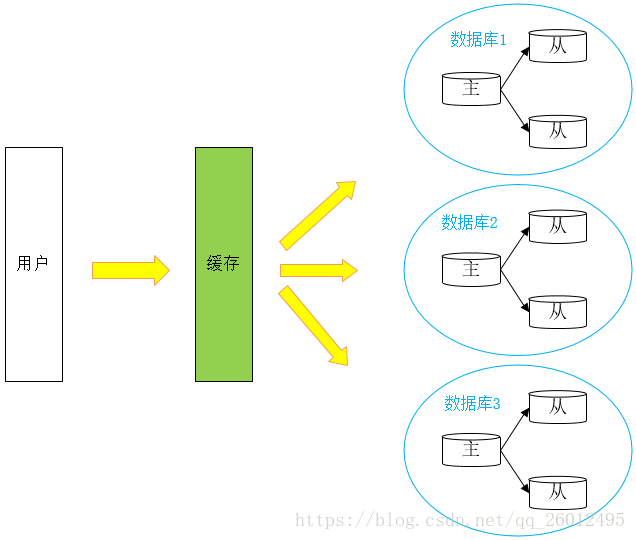
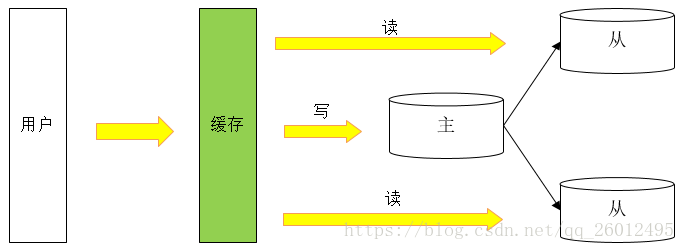
2、主從複製、讀寫分離
主資料庫做動作,從資料庫立即做相同動作與主資料庫保持一致【主從複製,目的:容災】。讀:查;增刪改:寫。
讀寫分離,寫的操作都放在主庫,然後從庫會立刻同步,讀的操作都放在從庫,減小資料庫的壓力。
3、分庫分表+水平拆分+叢集
在增加快取以及主從複製、讀寫分離基礎上,資料庫主庫寫壓力開始出現瓶頸。不論多麼高配置的資料庫,都會有自己的物理上限。
水平分割(包括庫內分表 和 分庫分表):例如一個600萬資料的表,由於資料量大會使效能下降,假設分割成三個表,每個表兩百萬條。
資料庫分多少張表取決於單張表容量,庫內分表能夠解決單張表資料很大的查詢效率問題,但是無法給資料庫的併發操作帶來效率上的提高,因為分表的實質還是在一個數據庫上進行的操作,很容易受資料庫IO效能的限制。
分庫分表是將一張表的資料經過演算法拆分後,放到不同的庫中。例如hash演算法。