
Tensorflow函式 tf.nn.atrous_conv2d如何實現空洞卷積?
實驗環境:tensorflow版本1.2.0,python2.7
介紹
關於空洞卷積的理論可以檢視以下連結,這裡我們不詳細講理論:
其實用一句話概括就是,在不用pooling的情況下擴大感受野(pooling層會導致資訊損失)
為了閱讀方便再貼一些相關連結:
慣例先展示函式:
tf.nn.atrous_conv2d(value,filters,rate,padding,name=None)除去name引數用以指定該操作的name,與方法有關的一共四個引數:
-
value: 指需要做卷積的輸入影象,要求是一個4維Tensor,具有
[batch, height, width, channels]這樣的shape,具體含義是[訓練時一個batch的圖片數量, 圖片高度, 圖片寬度, 影象通道數] -
filters: 相當於CNN中的卷積核,要求是一個4維Tensor,具有
[filter_height, filter_width, channels, out_channels]這樣的shape,具體含義是[卷積核的高度,卷積核的寬度,影象通道數,卷積核個數],同理這裡第三維channels,就是引數value的第四維 -
rate: 要求是一個
int型的正數,正常的卷積操作應該會有stride(即卷積核的滑動步長),但是空洞卷積是沒有stride引數的,這一點尤其要注意。取而代之,它使用了新的rate引數,那麼rate引數有什麼用呢?它定義為我們在輸入影象上卷積時的取樣間隔,你可以理解為卷積核當中穿插了(rate-1)數量的“0”,把原來的卷積核插出了很多“洞洞”,這樣做卷積時就相當於對原影象的取樣間隔變大了。具體怎麼插得,可以看後面更加詳細的描述。此時我們很容易得出rate=1時,就沒有0插入,此時這個函式就變成了普通卷積。 -
padding: string型別的量,只能是”SAME”,”VALID”其中之一,這個值決定了不同邊緣填充方式。
ok,完了,到這就沒有引數了,或許有的小夥伴會問那“stride”引數呢。其實這個函式已經默認了stride=1,也就是滑動步長無法改變,固定為1。
結果返回一個Tensor,填充方式為“VALID”時,返回[batch,height-2*(filter_width-1),width-2*(filter_height-1),out_channels]的Tensor,填充方式為“SAME”時,返回[batch, height, width, out_channels]的Tensor,這個結果怎麼得出來的?先不急,我們通過一段程式形象的演示一下空洞卷積。
實驗
首先建立一張2通道圖
img = tf.constant(value=[[[[1],[2],[3],[4]],[[1],[2],[3],[4]],[[1],[2],[3],[4]],[[1],[2],[3],[4]]]],dtype=tf.float32)
img = tf.concat(values=[img,img],axis=3)然後用一個3*3卷積核去做卷積
filter = tf.constant(value=1, shape=[3,3,2,5], dtype=tf.float32)
out_img = tf.nn.atrous_conv2d(value=img, filters=filter, rate=1)建立好了img和filter,就可以做卷積了
out_img = tf.nn.conv2d(input=img, filter=filter, strides=[1,1,1,1], padding='VALID')輸出5個channel,我們設定rate=1,此時空洞卷積可以看做普通的卷積,分別在SAME和VALID模式下輸出如下:
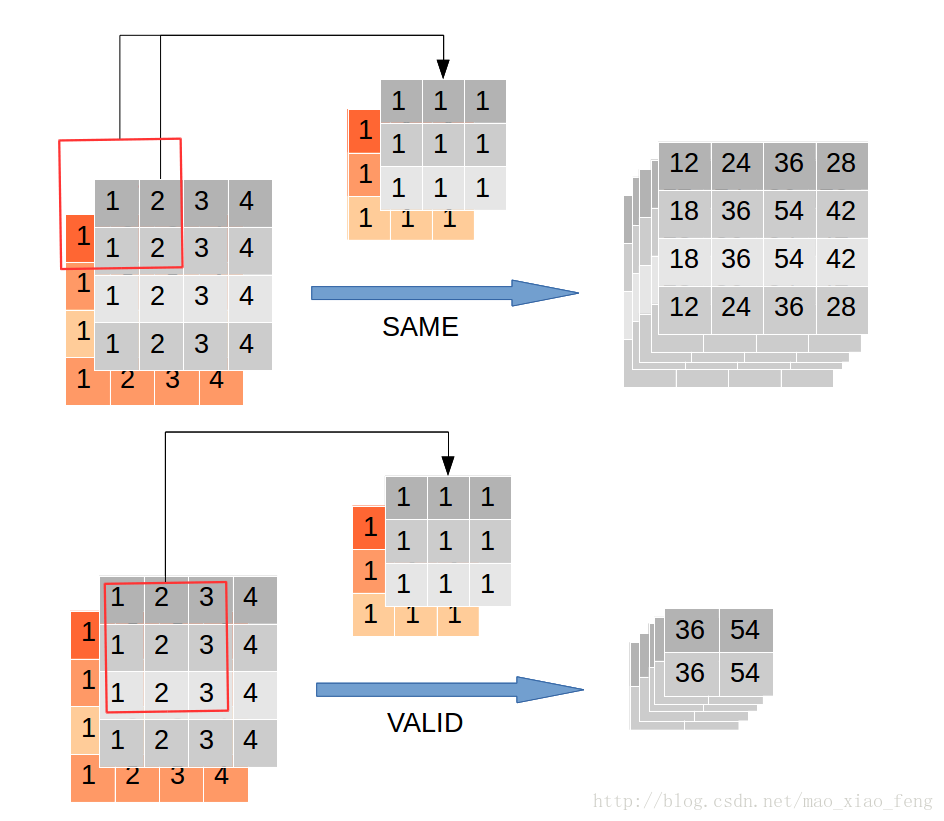
ok,調整rate=2,繼續執行程式
out_img = tf.nn.atrous_conv2d(value=img, filters=filter, rate=2, padding='SAME')檢視輸出結果
[[[[ 16. 16. 16. 16. 16.]
[ 24. 24. 24. 24. 24.]
[ 16. 16. 16. 16. 16.]
[ 24. 24. 24. 24. 24.]]
[[ 16. 16. 16. 16. 16.]
[ 24. 24. 24. 24. 24.]
[ 16. 16. 16. 16. 16.]
[ 24. 24. 24. 24. 24.]]
[[ 16. 16. 16. 16. 16.]
[ 24. 24. 24. 24. 24.]
[ 16. 16. 16. 16. 16.]
[ 24. 24. 24. 24. 24.]]
[[ 16. 16. 16. 16. 16.]
[ 24. 24. 24. 24. 24.]
[ 16. 16. 16. 16. 16.]
[ 24. 24. 24. 24. 24.]]]]這個結果怎麼出來的呢?再用一張圖
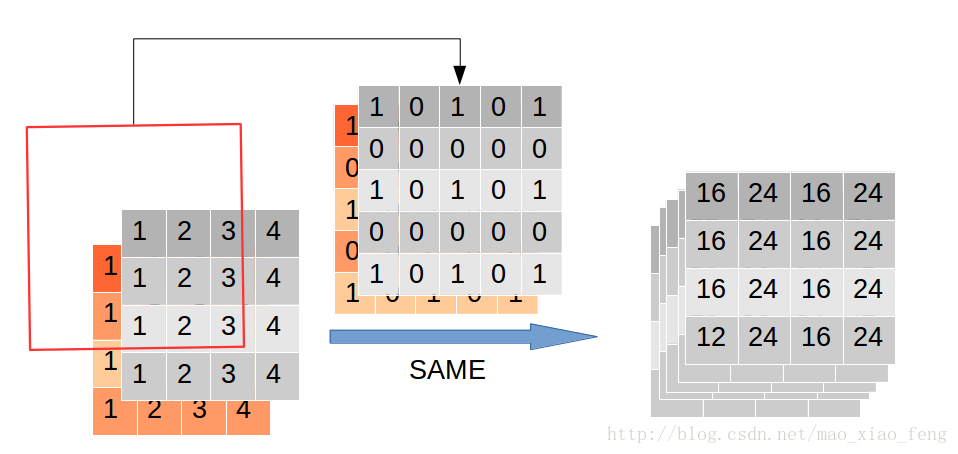
這裡我們看到rate=2時,通過穿插“0”,卷積核由3*3膨脹到了5*5。再看看“VALID”模式下,會發生什麼?
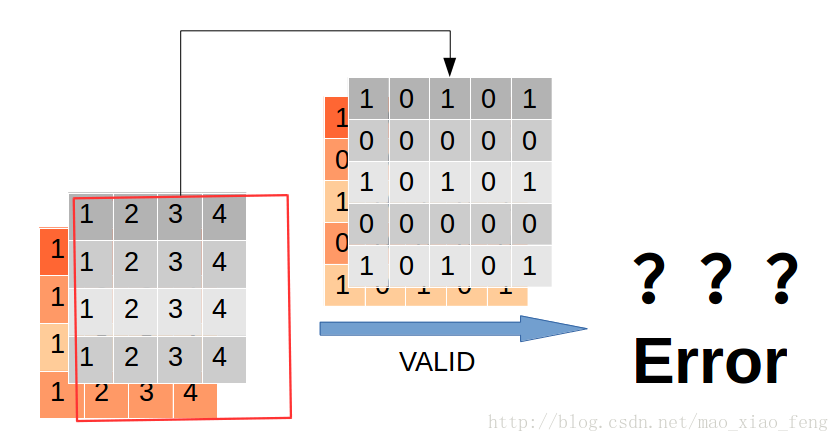
直接報錯了。因為卷積核的大小已經超過了原圖大小
好了,看到這裡相信大家對於空洞卷積有了基本的瞭解了。那麼,填充方式為“VALID”時,返回[batch,height-2*(filter_width-1),width-2*(filter_height-1),out_channels]的Tensor,這個結果,相信大家就可以證明了。
程式碼清單
import tensorflow as tf
img = tf.constant(value=[[[[1],[2],[3],[4]],[[1],[2],[3],[4]],[[1],[2],[3],[4]],[[1],[2],[3],[4]]]],dtype=tf.float32)
img = tf.concat(values=[img,img],axis=3)
filter = tf.constant(value=1, shape=[3,3,2,5], dtype=tf.float32)
out_img1 = tf.nn.atrous_conv2d(value=img, filters=filter, rate=1, padding='SAME')
out_img2 = tf.nn.atrous_conv2d(value=img, filters=filter, rate=1, padding='VALID')
out_img3 = tf.nn.atrous_conv2d(value=img, filters=filter, rate=2, padding='SAME')
#error
#out_img4 = tf.nn.atrous_conv2d(value=img, filters=filter, rate=2, padding='VALID')
with tf.Session() as sess:
print 'rate=1, SAME mode result:'
print(sess.run(out_img1))
print 'rate=1, VALID mode result:'
print(sess.run(out_img2))
print 'rate=2, SAME mode result:'
print(sess.run(out_img3))
# error
#print 'rate=2, VALID mode result:'
#print(sess.run(out_img4))--------------------- 本文來自 xf__mao 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/mao_xiao_feng/article/details/78003730?utm_source=copy