
Spark(一): 基本架構及原理
阿新 • • 發佈:2018-12-13
- 通常當需要處理的資料量超過了單機尺度(比如我們的計算機有4GB的記憶體,而我們需要處理100GB以上的資料)這時我們可以選擇spark叢集進行計算,有時我們可能需要處理的資料量並不大,但是計算很複雜,需要大量的時間,這時我們也可以選擇利用spark叢集強大的計算資源,並行化地計算,其架構示意圖如下:

- Spark Core:包含Spark的基本功能;尤其是定義RDD的API、操作以及這兩者上的動作。其他Spark的庫都是構建在RDD和Spark Core之上的
- Spark SQL:提供通過Apache Hive的SQL變體Hive查詢語言(HiveQL)與Spark進行互動的API。每個資料庫表被當做一個RDD,Spark SQL查詢被轉換為Spark操作。
- Spark Streaming:對實時資料流進行處理和控制。Spark Streaming允許程式能夠像普通RDD一樣處理實時資料
- MLlib:一個常用機器學習演算法庫,演算法被實現為對RDD的Spark操作。這個庫包含可擴充套件的學習演算法,比如分類、迴歸等需要對大量資料集進行迭代的操作。
- GraphX:控制圖、並行圖操作和計算的一組演算法和工具的集合。GraphX擴充套件了RDD API,包含控制圖、建立子圖、訪問路徑上所有頂點的操作
- Spark架構的組成圖如下:
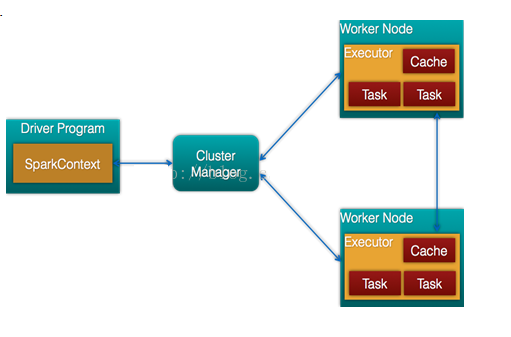
- Cluster Manager:在standalone模式中即為Master主節點,控制整個叢集,監控worker。在YARN模式中為資源管理器
- Worker節點:從節點,負責控制計算節點,啟動Executor或者Driver。
- Driver: 執行Application 的main()函式
- Executor:執行器,是為某個Application執行在worker node上的一個程序