
Spark基本架構及執行原理
Spark軟體棧

- Spark Core:
包含Spark的基本功能,包含任務排程,記憶體管理,容錯機制等,內部定義了RDDs(彈性分散式資料集),提供了很多APIs來建立和操作這些RDDs。為其他元件提供底層的服務。
- Spark SQL:
Spark處理結構化資料的庫,就像Hive SQL,Mysql一樣,企業中用來做報表統計。
- Spark Streaming:
實時資料流處理元件,類似Storm。Spark Streaming提供了API來操作實時流資料。企業中用來從Kafka接收資料做實時統計。
- MLlib:
一個包含通用機器學習功能的包,Machine learning lib包含分類,聚類,迴歸等,還包括模型評估和資料匯入。MLlib提供的上面這些方法,都支援叢集上的橫向擴充套件。
- Graphx:
處理圖的庫(例如,社交網路圖),並進行圖的平行計算。像Spark Streaming,Spark SQL一樣,它也繼承了RDD API。它提供了各種圖的操作,和常用的圖演算法,例如PangeRank演算法。
Spark提供了全方位的軟體棧,只要掌握Spark一門程式語言就可以編寫不同應用場景的應用程式(批處理,流計算,圖計算等)。Spark主要用來代替Hadoop的MapReduce部分。
Hadoop MapReduce缺點:
- 表達能力有限
- 磁碟IO開銷大,任務之間的銜接涉及IO開銷
- 延遲高,Map任務要全部結束,reduce任務才能開始。
Spark借鑑Hadoop MapReduce優點的同時,解決了MapReuce所面臨的問題,有如下優點:
- Spark的計算模式也屬於MapReduce,但不侷限於Map和Reduce操作,還提供多種資料集操作型別,程式設計模型比Hadoop MapReduce更靈活。
- Spark提供了記憶體計算,可將中間結果放到記憶體中,對於迭代運算效率更高
- Spark基於DAG的任務排程執行機制,要優於Hadoop MapReduce的迭代執行機制。
Spark執行架構及流程

基本概念:
- Application:使用者編寫的Spark應用程式。
- Driver:Spark中的Driver即執行上述Application的main函式並建立SparkContext,建立SparkContext的目的是為了準備Spark應用程式的執行環境,在Spark中有SparkContext負責與ClusterManager通訊,進行資源申請、任務的分配和監控等,當Executor部分執行完畢後,Driver同時負責將SparkContext關閉。
- Executor:是執行在工作節點(WorkerNode)的一個程序,負責執行Task。
- RDD:彈性分散式資料集,是分散式記憶體的一個抽象概念,提供了一種高度受限的共享記憶體模型。
- DAG:有向無環圖,反映RDD之間的依賴關係。
- Task:執行在Executor上的工作單元。
- Job:一個Job包含多個RDD及作用於相應RDD上的各種操作。
- Stage:是Job的基本排程單位,一個Job會分為多組Task,每組Task被稱為Stage,或者也被稱為TaskSet,代表一組關聯的,相互之間沒有Shuffle依賴關係的任務組成的任務集。
- Cluter Manager:指的是在叢集上獲取資源的外部服務。目前有三種類型
1) Standalon : spark原生的資源管理,由Master負責資源的分配
2) Apache Mesos:與hadoop MR相容性良好的一種資源排程框架
3) Hadoop Yarn: 主要是指Yarn中的ResourceManager
一個Application由一個Driver和若干個Job構成,一個Job由多個Stage構成,一個Stage由多個沒有Shuffle關係的Task組成。
當執行一個Application時,Driver會向叢集管理器申請資源,啟動Executor,並向Executor傳送應用程式程式碼和檔案,然後在Executor上執行Task,執行結束後,執行結果會返回給Driver,或者寫到HDFS或者其它資料庫中。
與Hadoop MapReduce計算框架相比,Spark所採用的Executor有兩個優點:
- 利用多執行緒來執行具體的任務減少任務的啟動開銷;
- Executor中有一個BlockManager儲存模組,會將記憶體和磁碟共同作為儲存裝置,有效減少IO開銷;
Spark執行基本流程:
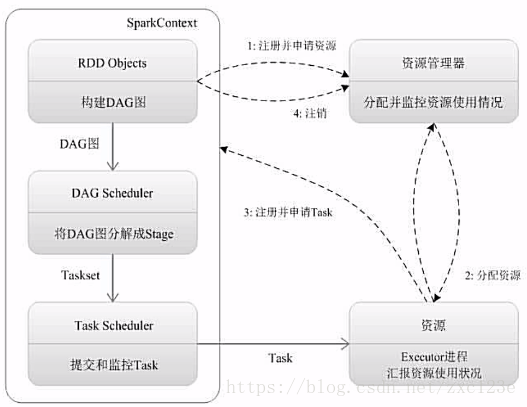
- 為應用構建起基本的執行環境,即由Driver建立一個SparkContext進行資源的申請、任務的分配和監控
- 資源管理器為Executor分配資源,並啟動Executor程序
- SparkContext根據RDD的依賴關係構建DAG圖,DAG圖提交給DAGScheduler解析成Stage,然後把一個個TaskSet提交給底層排程器TaskScheduler處理。
Executor向SparkContext申請Task,TaskScheduler將Task發放給Executor執行並提供應用程式程式碼。 - Task在Executor上執行把執行結果反饋給TaskScheduler,然後反饋給DAGScheduler,執行完畢後寫入資料並釋放所有資源。
Spark執行架構特點:
- 每個Application都有自己專屬的Executor程序,並且該程序在Application執行期間一直駐留。Executor程序以多執行緒的方式執行Task。
- Spark執行過程與資源管理器無關,只要能夠獲取Executor程序並儲存通訊即可。
- Task採用資料本地性和推測執行等優化機制。
RDD
一個RDD就是一個分散式物件集合,本質上是一個只讀的分割槽記錄集合,每個RDD可分成多個分割槽,每個分割槽就是一個數據集片段,並且一個RDD的不同分割槽可以被儲存到叢集中不同的節點上,從而可以在叢集的不同節點上進行平行計算。
RDD提供了一種高階受限的共享記憶體模型,即RDD是隻讀的記錄分割槽的集合,不能直接修改,只能基於穩定的物理儲存中的資料集建立RDD,或者通過在其他RDD上執行確定的轉換操作(如map,join和group by)而建立得到新的RDD。
RDD執行過程:
- RDD讀入外部資料來源進行建立
- RDD經過一系列的轉換(Transformation)操作,沒一次都會產生不同的RDD供下一個轉換操作使用
- 最後一個RDD經過“動作”操作進行轉換並輸出到外部資料來源
優點:惰性呼叫、管道化、避免同步等待,不需要儲存中間結果。這和Java8中Stream的概念極其類似。

RDD特性
- 高效的容錯性,根據DAG圖恢復分割槽,資料複製或者記錄日誌
RDD血緣關係、重新計算丟失分割槽、無需回滾系統、重算過程在不同節點之間並行、只記錄粗粒度的操作 - 中間結果持久化到記憶體,資料在記憶體中的多個RDD操作之間進行傳遞,避免了不必要的讀寫磁碟開銷
- 存放的資料可以是Java物件,避免了不必要的物件序列化和反序列化
窄依賴和寬依賴
- 窄依賴:表現為一個父RDD的分割槽對應於一個子RDD的分割槽或者多個父RDD的分割槽對應於一個子RDD的分割槽。
- 寬依賴:表現為存在一個父RDD的一個分割槽對應一個子RDD的多個分割槽。

Stage的劃分
Spark通過分析各個RDD的依賴關係生成了DAG,在通過分析各個RDD中的分割槽之間的依賴關係來決定如何劃分Stage。具體劃分方法如下:
- 在DAG中進行反向解析,遇到寬依賴就斷開,遇到窄依賴就把當前的RDD加入到Stage中;
- 將窄依賴儘量劃分在同一個Stage中,可以實現流水線計算

此文主要參考廈門大學Spark基礎教程