
【SPARK】Spark Streaming簡介
Spark Streaming可以整合多種輸入資料來源,如Kafka、Flume、HDFS甚至是普通的TCP套接字。經處理後的資料可儲存至檔案系統、資料庫、或顯示在儀表盤。
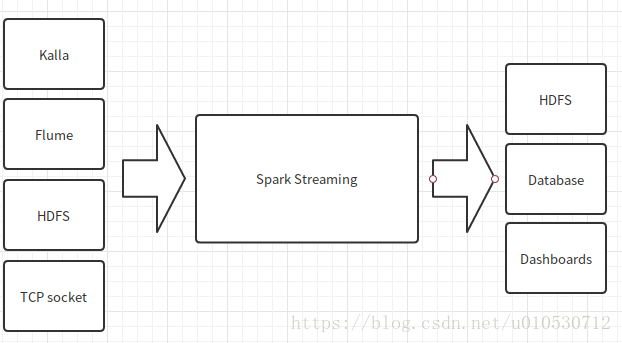
Spark Streaming執行流程
Spark Streaming的基本原理是將實時輸入資料流以時間片(秒級)為單位進行拆分,然後經Spark引擎以類擬批處理的方式處理每個時間片資料

DStream操作示意圖
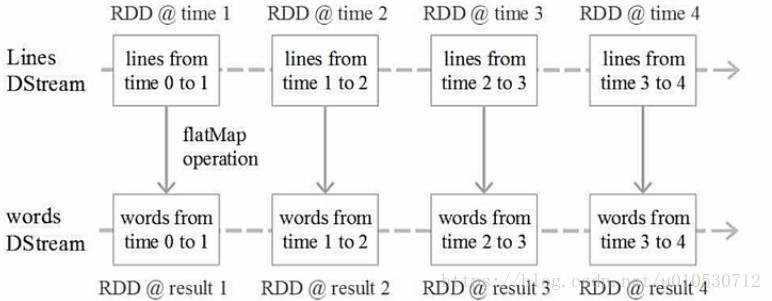
Spark Streaming最主要的抽象是DStream(Discretized Stream,離散化資料流),表示連續不斷的資料流。在內部實現上,Spark Streaming的輸入資料按照時間片(如1秒)
Spark輸入源
相關推薦
【SPARK】Spark Streaming簡介
Spark Streaming可以整合多種輸入資料來源,如Kafka、Flume、HDFS甚至是普通的TCP套接字。經處理後的資料可儲存至檔案系統、資料庫、或顯示在儀表盤。 Spark Streaming執行流程 Spark Streaming的基本原理是將實時輸
【轉】Spark Streaming和Kafka整合開發指南
thread ada 關系 方法 拷貝 理解 1.2 reduce arr 基於Receivers的方法 這個方法使用了Receivers來接收數據。Receivers的實現使用到Kafka高層次的消費者API。對於所有的Receivers,接收到的數據將會保存在Spark
【八】Spark Streaming 用foreachRDD把結果寫入Mysql中Local模式(使用Scala語言)
DStream 的foreachRDD是允許把資料傳送到外部檔案系統中。然而使用不當會導致各種問題。 錯誤示範1:在driver建立連線,在woker使用。會報錯connection object not serializable。 錯誤示範2:rdd每個記錄都建立連
【六】Spark Streaming接入HDFS的資料Local模式(使用Scala語言)
Spark Streaming接入HDFS的資料模擬一個wordcount的功能,結果列印到控制檯,使用Local模式,使用Scala語言。 專案目錄 pom.xml <project xmlns="http://maven.apache.org/POM/4.
【轉載】 Spark性能優化指南——基礎篇
否則 內存占用 是否 進行 優先 邏輯 我們 流式 字節數組 前言 開發調優 調優概述 原則一:避免創建重復的RDD 原則二:盡可能復用同一個RDD 原則三:對多次使用的RDD進行持久化 原則四:盡量避免使用shuffle類算子 原則五:使用map-side預聚
【總結】spark按文本格式和Lzo格式處理Lzo壓縮文件的比較
spark lzotextinputformat1、描述spark中怎麽加載lzo壓縮格式的文件2、比較lzo格式文件以textFile方式和LzoTextInputFormat方式計算數據,Running Tasks個數的影響 a.確保lzo文件所在文件夾中生成lzo.index索引文件 b.以
【轉載】Spark學習——spark中的幾個概念的理解及參數配置
program submit man 聯眾 tail 進行 orb 數據源 work 首先是一張Spark的部署圖: 節點類型有: 1. master 節點: 常駐master進程,負責管理全部worker節點。2. worker 節點: 常駐worker進程,負責管理
【python】spark+kafka使用
設置 消費 /usr tegra 情況下 分布式文件系統 默認 usr mina 網上用python寫spark+kafka的資料好少啊 自己記錄一點踩到的坑~ spark+kafka介紹的官方網址:http://spark.apache.org/docs/latest
【Spark】Spark執行報錯Task not serializable
文章目錄 異常資訊 出現場景 解決方案 分析 異常資訊 org.apache.spark.SparkException: Task not serializable Caused by: java.io.NotSerial
【Spark】Spark是什麼
簡短介紹下Spark 幾個關鍵詞:快速,通用,叢集計算平臺 Spark擴充套件了MapReduce計算模型,且支援更多計算模式,包含: 互動式查詢 流處理 這裡的互動式,不是簡單的我們生活中理解的與裝置的互動。它的深意是:對於大規模資料集的處理,速度夠
【Spark】Spark Quick Start(快速入門翻譯)
本文主要是翻譯Spark官網Quick Start。只能保證大概意思,儘量保證細節。英文水平有限,如果有錯誤的地方請指正,輕噴 快速入門(Quick Start) 使用 Spark Shell 互動式程式設計 基本操作 更多關於 Dataset 的操作 快取 獨立
【Spark】Spark SQL, DataFrames and Datasets Guide(翻譯文,持續更新)
本文主要是翻譯Spark官網Spark SQL programming guide 。只能保證大概意思,儘量保證細節。英文水平有限,如果有錯誤的地方請指正,輕噴。目錄導航在右上角 概述 Spark SQL 是一個結構化資料處理的 Spark 模組 。 與基礎的 Spark RDD API 不同的是
【Spark】--Spark中RDD的理解
1.什麼是RDD?RDD:RDD是Spark的計算模型 RDD(Resilient Distributed Dataset)叫做彈性的分散式資料集合,是Spark中最基本的資料抽象,它代表一個不可變、只讀的,被分割槽的資料集。操作RDD就像操作本地集合一樣,資料會被分散到多臺
【轉】【Spark】Spark 資料傾斜優化方法
大資料梅峰谷 2017-05-19 --------本節內容-------- 1.前言 2.Spark資料傾斜 2.1 資料傾斜現象 2.1.1 OOM錯誤 2.1.2 Spark執行緩慢 2.2 資料傾斜原理 2.3 資
【Spark】Spark 訊息通訊架構
本篇結構: 前言 幾個重要概念 Spark RpcEnv Spark RpcEndpoint Spark RpcEndpointRef RpcEnv 和 RpcEndpoint 關係類圖 Dispatcher 和 Inbox Outbox 時序圖 一、前言
【七】Spark SQL命令和Spark shell命令操作hive中的表
1.把hive的配置檔案hive-site.xml複製到spark/conf下。 2.啟動的時候帶上MySQL的連線驅動 Spark-shell命令使用 spark-shell是通過得到sparksession然後呼叫sql方法執行hive的sql。 cd /app/
蝸龍徒行-Spark學習筆記【四】Spark叢集中使用spark-submit提交jar任務包實戰經驗
一、所遇問題 由於在IDEA下可以方便快捷地執行scala程式,所以先前並沒有在終端下使用spark-submit提交打包好的jar任務包的習慣,但是其只能在local模式下執行,在網上搜了好多帖子設定VM引數都不能啟動spark叢集,由於實驗任務緊急只能暫時
Cloudera之旅 ☞ 【二】Spark-sql部署
參考 概述 由於cloudera自帶的spark-yarn不支援沒有spark-sql(也許是cloudera推廣自己的impala吧),但是如果我們線上要用spark直接寫原生的必然效率低很多 這裡簡單描述下自己遇到的兩個超級大坑
【Spark】Spark的Standalone模式安裝部署
Spark執行模式 Spark 有很多種模式,最簡單就是單機本地模式,還有單機偽分散式模式,複雜的則執行在叢集中,目前能很好的執行在 Yarn和 Mesos 中,當然 Spark 還有自帶的 Standalone 模式,對於大多數情況 Standalone 模
【轉載】Spark效能優化指南——高階篇
前言 繼基礎篇講解了每個Spark開發人員都必須熟知的開發調優與資源調優之後,本文作為《Spark效能優化指南》的高階篇,將深入分析資料傾斜調優與shuffle調優,以解決更加棘手的效能問題。 資料傾斜調優 調優概述 有的時候,我們可能會遇到大資料計算中一個最棘手的問題——資料傾斜,此時Spark作業