
es Score Query優化查詢
通過Function Score Que
function_score查詢是處理分值計算過程的終極工具。它讓你能夠對所有匹配了主查詢的每份文件呼叫一個函式來調整甚至是完全替換原來的_score。
實際上,你可以通過設定過濾器來將查詢得到的結果分成若干個子集,然後對每個子集使用不同的函式。這樣你就能夠同時得益於:高效的分值計算以及可快取的過濾器。
它擁有幾種預先定義好了的函式:
weight
對每份文件適用一個簡單的提升,且該提升不會被歸約:當weight為2時,結果為2 * _score。
field_value_factor
使用文件中某個欄位的值來改變_score,比如將受歡迎程度或者投票數量考慮在內。
random_score
使用一致性隨機分值計算來對每個使用者採用不同的結果排序方式,對相同使用者仍然使用相同的排序方式。
衰減函式(Decay Function) - linear,exp,gauss
將像publish_date,geo_location或者price這類浮動值考慮到_score中,偏好最近釋出的文件,鄰近於某個地理位置(譯註:其中的某個欄位)的文件或者價格(譯註:其中的某個欄位)靠近某一點的文件。
script_score
使用自定義的指令碼來完全控制分值計算邏輯。如果你需要以上預定義函式之外的功能,可以根據需要通過指令碼進行實現。
沒有function_score查詢的話,我們也許就不能將全文搜尋得到分值和近因進行結合了。我們將不得不根據_score或者date進行排序;無論採用哪一種都會抹去另一種的影響。function_score查詢讓我們能夠將兩者融合在一起:仍然通過全文相關度排序,但是給新近釋出的文件,或者流行的文件,或者符合使用者價格期望的文件額外的權重。你可以想象,一個擁有所有這些功能的查詢看起來會相當複雜。我們從一個簡單的例子開始,循序漸進地對它進行介紹。
根據人氣來提升(Boosting by Popularity)
假設我們有一個部落格網站讓使用者投票選擇他們喜歡的文章。我們希望讓人氣高的文章出現在結果列表的頭部,但是主要的排序依據仍然是全文搜尋分值。我們可以通過儲存每篇文章的投票數量來實現:
PUT /blogposts/post/1
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 6
}
在搜尋期間,使用帶有field_value_factor函式的function_score查詢將投票數和全文相關度分值結合起來:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes"
}
}
}
}
function_score查詢會包含主查詢(Main Query)和希望適用的函式。先會執行主查詢,然後再為匹配的文件呼叫相應的函式。每份文件中都必須有一個votes欄位用來保證function_score能夠起作用。
在前面的例子中,每份文件的最終_score會通過下面的方式改變:
new_score = old_score * number_of_votes
它得到的結果並不好。全文搜尋的_score通常會在0到10之間。而從下圖我們可以發現,擁有10票的文章的分值大大超過了這個範圍,而沒有被投票的文章的分值會被重置為0。
modifier
為了讓votes值對最終分值的影響更緩和,我們可以使用modifier。換言之,我們需要讓頭幾票的效果更明顯,其後的票的影響逐漸減小。0票和1票的區別應該比10票和11票的區別要大的多。
一個用於此場景的典型modifier是log1p,它將公式改成這樣:
new_score = old_score * log(1 + number_of_votes)
log函式將votes欄位的效果減緩了,其效果類似下面的曲線:
使用了modifier引數的請求如下:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p"
}
}
}
}
可用的modifiers有:none(預設值),log,log1p,log2p,ln,ln1p,ln2p,square,sqrt以及reciprocal。它們的詳細功能和用法可以參考field_value_factor文件。
factor
可以通過將votes欄位的值乘以某個數值來增加該欄位的影響力,這個數值被稱為factor:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 2
}
}
}
}
添加了factor將公式修改成這樣:
new_score = old_score * log(1 + factor * number_of_votes)
當factor大於1時,會增加其影響力,而小於1的factor則相應減小了其影響力,如下圖所示:
boost_mode
將全文搜尋的相關度分值乘以field_value_factor函式的結果,對最終分值的影響可能太大了。通過boost_mode引數,我們可以控制函式的結果應該如何與_score結合在一起,該引數接受下面的值:
- multiply:_score乘以函式結果(預設情況)
- sum:_score加上函式結果
- min:_score和函式結果的較小值
- max:_score和函式結果的較大值
- replace:將_score替換成函式結果
如果我們是通過將函式結果累加來得到_score,其影響會小的多,特別是當我們使用了一個較低的factor時:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum"
}
}
}
上述請求的公式如下所示:
new_score = old_score + log(1 + 0.1 * number_of_votes)
max_boost
最後,我們能夠通過制定max_boost引數來限制函式的最大影響:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum",
"max_boost": 1.5
}
}
}
無論field_value_factor函式的結果是多少,它絕不會大於1.5。
NOTE
max_boost只是對函式的結果有所限制,並不是最終的_score。
ry優化Elasticsearch搜尋結果
在使用 Elasticsearch 進行全文搜尋時,搜尋結果預設會以文件的相關度進行排序,如果想要改變預設的排序規則,也可以通過sort指定一個或多個排序欄位。
但是使用sort排序過於絕對,它會直接忽略掉文件本身的相關度(根本不會去計算)。在很多時候這樣做的效果並不好,這時候就需要對多個欄位進行綜合評估,得出一個最終的排序。
function_score
在 Elasticsearch 中function_score是用於處理文件分值的 DSL,它會在查詢結束後對每一個匹配的文件進行一系列的重打分操作,最後以生成的最終分數進行排序。它提供了幾種預設的計算分值的函式:
weight:設定權重field_value_factor:將某個欄位的值進行計算得出分數。random_score:隨機得到 0 到 1 分數- 衰減函式:同樣以某個欄位的值為標準,距離某個值越近得分越高
-
script_score:通過自定義指令碼計算分值它還有一個屬性
boost_mode可以指定計算後的分數與原始的_score如何合併,有以下選項: -
multiply:將結果乘以_score sum:將結果加上_scoremin:取結果與_score的較小值max:取結果與_score的較大值-
replace:使結果替換掉_score接下來本文將詳細介紹這些函式的用法,以及它們的使用場景。
weight
weight 的用法最為簡單,只需要設定一個數字作為權重,文件的分數就會乘以該權重。
他最大的用途應該就是和過濾器一起使用了,因為過濾器只會篩選出符合標準的文件,而不會去詳細的計算每個文件的具體得分,所以只要滿足條件的文件的分數都是 1,而 weight 可以將其更換為你想要的數值。
field\_value\_factor
field\_value\_factor 的目的是通過文件中某個欄位的值計算出一個分數,它有以下屬性:
-
field:指定欄位名
factor:對欄位值進行預處理,乘以指定的數值(預設為 1)
-
modifier將欄位值進行加工,有以下的幾個選項:none:不處理log:計算對數log1p:先將欄位值 +1,再計算對數log2p:先將欄位值 +2,再計算對數ln:計算自然對數ln1p:先將欄位值 +1,再計算自然對數ln2p:先將欄位值 +2,再計算自然對數square:計算平方sqrt:計算平方根reciprocal:計算倒數
舉一個簡單的例子,假設有一個商品索引,搜尋時希望在相關度排序的基礎上,銷量(
sales)更高的商品能排在靠前的位置,那麼這條查詢 DSL 可以是這樣的:
|
這條查詢會將標題中帶有雨傘的商品檢索出來,然後對這些文件計算一個與庫存相關的分數,並與之前相關度的分數相加,對應的公式為:
|
random\_score
這個函式的使用相當簡單,只需要呼叫一下就可以返回一個 0 到 1 的分數。
它有一個非常有用的特性是可以通過seed屬性設定一個隨機種子,該函式保證在隨機種子相同時返回值也相同,這點使得它可以輕鬆地實現對於使用者的個性化推薦。
衰減函式
衰減函式(Decay Function)提供了一個更為複雜的公式,它描述了這樣一種情況:對於一個欄位,它有一個理想的值,而欄位實際的值越偏離這個理想值(無論是增大還是減小),就越不符合期望。這個函式可以很好的應用於數值、日期和地理位置型別,由以下屬性組成:
- 原點(
origin):該欄位最理想的值,這個值可以得到滿分(1.0) - 偏移量(
offset):與原點相差在偏移量之內的值也可以得到滿分 - 衰減規模(
scale):當值超出了原點到偏移量這段範圍,它所得的分數就開始進行衰減了,衰減規模決定了這個分數衰減速度的快慢 -
衰減值(
decay):該欄位可以被接受的值(預設為 0.5),相當於一個分界點,具體的效果與衰減的模式有關例如我們想要買一樣東西:
-
它的理想價格是 50 元,這個值為原點
- 但是我們不可能非 50 元就不買,而是會劃定一個可接受的價格範圍,例如 45-55 元,±5 就為偏移量
-
當價格超出了可接受的範圍,就會讓人覺得越來越不值。如果價格是 70 元,評價可能是不太想買,而如果價格是 200 元,評價則會是不可能會買,這就是由衰減規模和衰減值所組成的一條衰減曲線
或者如果我們想租一套房:
-
它的理想位置是公司附近
- 如果離公司在 5km 以內,是我們可以接受的範圍,在這個範圍內我們不去考慮距離,而是更偏向於其他資訊
-
當距離超過 5km 時,我們對這套房的評價就越來越低了,直到超出了某個範圍就再也不會考慮了
衰減函式還可以指定三種不同的模式:線性函式(linear)、以 e 為底的指數函式(Exp)和高斯函式(gauss),它們擁有不同的衰減曲線:
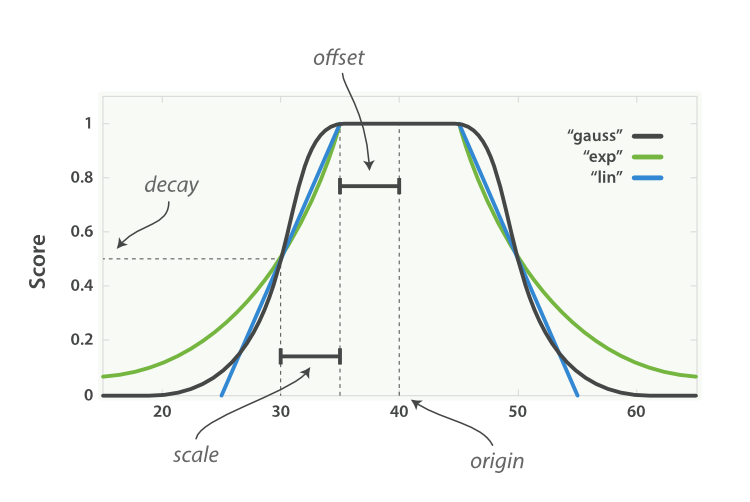
將上面提到的租房用 DSL 表示就是:
|
我們希望租房的位置在40, 116座標附近,5km以內是滿意的距離,15km以內是可以接受的距離。
script\_score
雖然強大的 field\_value\_factor 和衰減函式已經可以解決大部分問題了,但是也可以看出它們還有一定的侷限性:
- 這兩種方式都只能針對一個欄位計算分值
-
這兩種方式應用的欄位型別有限,field\_value\_factor 一般只用於數字型別,而衰減函式一般只用於數字、位置和時間型別
這時候就需要 script\_score 了,它支援我們自己編寫一個指令碼執行,在該指令碼中我們可以拿到當前文件的所有欄位資訊,並且只需要將計算的分數作為返回值傳回 Elasticsearch 即可。
注:使用指令碼需要首先在配置檔案中開啟相關功能:
|
舉一個之前做不到的例子,假如我們有一個位置索引,它有一個分類(category)屬性,該屬性是字串列舉型別,例如商場、電影院或者餐廳等。現在由於我們有一個電影相關的活動,所以需要將電影院在搜尋列表中的排位相對靠前。
之前的兩種方式都無法給字串打分,但是如果我們自己寫指令碼的話卻很簡單,使用 Groovy(Elasticsearch 的預設指令碼語言)也就是一行的事:
|
接下來只要將這個指令碼配置到查詢語句中就可以了:
|
或是將指令碼放在elasticsearch/config/scripts下,然後在查詢語句中引用它:
category-score.groovy:
|
|
在script中還可以通過params屬性向指令碼傳值,所以為了解除耦合,上面的 DSL 還能接著改寫為:
category-score.groovy:
|
|
這樣就可以在不更改大部分查詢語句和指令碼的基礎上動態修改推薦的位置類別了。
同時使用多個函式
上面的例子都只是呼叫某一個函式並與查詢得到的_score進行合併處理,而在實際應用中肯定會出現在多個點上計算分值併合並,雖然指令碼也許可以解決這個問題,但是應該沒人願意維護一個複雜的指令碼吧。這時候通過多個函式將每個分值都計算出在合併才是更好的選擇。
在 function\_score 中可以使用functions屬性指定多個函式。它是一個數組,所以原有函式不需要發生改動。同時還可以通過score_mode指定各個函式分值之間的合併處理,值跟最開始提到的boost_mode相同。下面舉兩個例子介紹一些多個函式混用的場景。
第一個例子是類似於大眾點評的餐廳應用。該應用希望向使用者推薦一些不錯的餐館,特徵是:範圍要在當前位置的 5km 以內,有停車位是最重要的,有 Wi-Fi 更好,餐廳的評分(1 分到 5 分)越高越好,並且對不同使用者最好展示不同的結果以增加隨機性。
那麼它的查詢語句應該是這樣的:
|
注:其中所有以$開頭的都是變數。
這樣一個飯館的最高得分應該是 2 分(有停車位)+ 1 分(有 wifi)+ 6 分(評分 5 分 \* 1.2)+ 1 分(隨機評分)。
另一個例子是類似於新浪微博的社交網站。現在要優化搜尋功能,使其以文字相關度排序為主,但是越新的微博會排在相對靠前的位置,點贊(忽略相同計算方式的轉發和評論)數較高的微博也會排在較前面。如果這篇微博購買了推廣並且是建立不到 24 小時(同時滿足),它的位置會非常靠前。
|
它的公式為:
|
通過Function Score Query優化Elasticsearch搜尋結果:function_score 是這種形式的DSL,單個函式模式
|
1 2 3 4 5 6 |
|
也可以同時使用多個函式, 通過filter篩選出來的文件會應用上對應的函式 多函式模式
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
score_mode 指定 如何將 函式算出的分數 和 原來分數 _score 合併起來
|
1 2 3 4 5 6 7 8 9 10 11 |
|
score_mode 表示多個函式之間的關係, boost_mode 表示單個函式 應用 weight的計算關係 weight是權重,每個函式可以有一個權重weight,預設是相乘的關係。
舉個例子, 在score_mode 是 avg 的情況下,如果兩個函式返回的分數是1和2,它們的權重分別是3和4,那麼最後的得分是 (1*3+2*4)/(3+4) 而不是(1*3+2*4)/2.
函式算出的新分數 被限定不能超過 max_boost, max_boost 的預設值是FLT_MAX
boost_mode的取值有
|
1 2 3 4 5 6 |
|
min_score 這個欄位沒有理解。
我們可以讓score不走預設的,讓他與我們某個field進行計算(加減乘除自己定義)得到一個結果作為score值
資料準備 follower_num:帖子閱讀量
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"follower_num" : 5} }
{ "update": { "_id": "2"} }
{ "doc" : {"follower_num" : 10} }
{ "update": { "_id": "3"} }
{ "doc" : {"follower_num" : 25} }
{ "update": { "_id": "4"} }
{ "doc" : {"follower_num" : 3} }
{ "update": { "_id": "5"} }
{ "doc" : {"follower_num" : 60} }
將對帖子搜尋得到的分數,跟follower_num進行運算,由follower_num在一定程度上增強帖子的分數 看帖子的人越多,那麼帖子的分數就越高
GET /forum/article/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "java spark",
"fields": ["title", "content"]
}
},
"field_value_factor": {
"field": "follower_num"
}
}
}
}
結果:
{
"took": 124,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 40.994698,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 40.994698,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny",
"follower_num": 60
}
},
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 6.8640785,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith",
"follower_num": 10
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 1.3371139,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses",
"author_first_name": "Peter",
"author_last_name": "Smith",
"new_author_last_name": "Smith",
"new_author_first_name": "Peter",
"follower_num": 5
}
},
{
"_index": "forum",
"_type": "article",
"_id": "4",
"_score": 0.46640402,
"_source": {
"articleID": "QQPX-R-3956-#aD8",
"userID": 2,
"hidden": true,
"postDate": "2017-01-02",
"tag": [
"java",
"elasticsearch"
],
"tag_cnt": 2,
"view_cnt": 80,
"title": "this is java, elasticsearch, hadoop blog",
"content": "elasticsearch and hadoop are all very good solution, i am a beginner",
"sub_title": "both of them are good",
"author_first_name": "Robbin",
"author_last_name": "Li",
"new_author_last_name": "Li",
"new_author_first_name": "Robbin",
"follower_num": 3
}
}
]
}
}
可以發現分數都特別的大,都在好幾十。是因為它與我們的follower_num進行了乘法運算。
我們想讓分數不要相差的這麼離譜怎麼辦? modifier
GET /forum/article/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "java spark",
"fields": ["title", "content"]
}
},
"field_value_factor": {
"field": "follower_num",
"modifier": "log1p"
}
}
}
}
結果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1.0189654,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 1.0189654,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny",
"follower_num": 60
}
},
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.53412914,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith",
"follower_num": 10
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.14549617,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses",
"author_first_name": "Peter",
"author_last_name": "Smith",
"new_author_last_name": "Smith",
"new_author_first_name": "Peter",
"follower_num": 5
}
},
{
"_index": "forum",
"_type": "article",
"_id": "4",
"_score": 0.06186694,
"_source": {
"articleID": "QQPX-R-3956-#aD8",
"userID": 2,
"hidden": true,
"postDate": "2017-01-02",
"tag": [
"java",
"elasticsearch"
],
"tag_cnt": 2,
"view_cnt": 80,
"title": "this is java, elasticsearch, hadoop blog",
"content": "elasticsearch and hadoop are all very good solution, i am a beginner",
"sub_title": "both of them are good",
"author_first_name": "Robbin",
"author_last_name": "Li",
"new_author_last_name": "Li",
"new_author_first_name": "Robbin",
"follower_num": 3
}
}
]
}
}
公式會變為,new_score = old_score * log(1 + number_of_votes),這樣出來的分數會比較合理
再加個factor,可以進一步影響分數,new_score = old_score * log(1 + factor * number_of_votes)
GET /forum/article/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "java spark",
"fields": ["title", "content"]
}
},
"field_value_factor": {
"field": "follower_num",
"modifier": "log1p",
"factor": 0.5
}
}
}
}
結果
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1.0189654,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 1.0189654,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny",
"follower_num": 60
}
},
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.53412914,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith",
"follower_num": 10
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.14549617,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses",
"author_first_name": "Peter",
"author_last_name": "Smith",
"new_author_last_name": "Smith",
"new_author_first_name": "Peter",
"follower_num": 5
}
},
{
"_index": "forum",
"_type": "article",
"_id": "4",
"_score": 0.06186694,
"_source": {
"articleID": "QQPX-R-3956-#aD8",
"userID": 2,
"hidden": true,
"postDate": "2017-01-02",
"tag": [
"java",
"elasticsearch"
],
"tag_cnt": 2,
"view_cnt": 80,
"title": "this is java, elasticsearch, hadoop blog",
"content": "elasticsearch and hadoop are all very good solution, i am a beginner",
"sub_title": "both of them are good",
"author_first_name": "Robbin",
"author_last_name": "Li",
"new_author_last_name": "Li",
"new_author_first_name": "Robbin",
"follower_num": 3
}
}
]
}
}
我們不想乘法,想加上follower_num
GET /forum/article/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "java spark",
"fields": ["title", "content"]
}
},
"field_value_factor": {
"field": "follower_num",
"modifier": "log1p",
"factor": 0.5
},
"boost_mode": "sum"
}
}
}
結果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 2.1746066,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 2.1746066,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny",
"follower_num": 60
}
},
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1.4645591,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith",
"follower_num": 10
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.81149083,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses",
"author_first_name": "Peter",
"author_last_name": "Smith",
"new_author_last_name": "Smith",
"new_author_first_name": "Peter",
"follower_num": 5
}
},
{
"_index": "forum",
"_type": "article",
"_id": "4",
"_score": 0.553408,
"_source": {
"articleID": "QQPX-R-3956-#aD8",
"userID": 2,
"hidden": true,
"postDate": "2017-01-02",
"tag": [
"java",
"elasticsearch"
],
"tag_cnt": 2,
"view_cnt": 80,
"title": "this is java, elasticsearch, hadoop blog",
"content": "elasticsearch and hadoop are all very good solution, i am a beginner",
"sub_title": "both of them are good",
"author_first_name": "Robbin",
"author_last_name": "Li",
"new_author_last_name": "Li",
"new_author_first_name": "Robbin",
"follower_num": 3
}
}
]
}
}
boost_mode,可以決定分數與指定欄位的值如何計算,multiply,sum,min,max,replace
max_boost,限制計算出來的分數不要超過max_boost指定的值
GET /forum/article/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "java spark",
"fields": ["title", "content"]
}
},
"field_value_factor": {
"field": "follower_num",
"modifier": "log1p",
"factor": 0.5
},
"boost_mode": "sum",
"max_boost": 2
}
}
}上次寫了關於 Elasticsearch 如何分詞索引, 接著繼續寫 Elasticsearch 怎麼計算搜尋結果的得分(_score).
Elasticsearch 預設是按照文件與查詢的相關度(匹配度)的得分倒序返回結果的. 得分 (_score) 就越大, 表示相關性越高.
所以, 相關度是啥? 分數又是怎麼計算出來的? (全文檢索和結構化的 SQL 查詢不太一樣, 雖然看起來結果比較'飄忽', 但也是可以追根問底的)
在 Elasticsearch 中, 標準的演算法是 Term Frequency/Inverse Document Frequency, 簡寫為 TF/IDF, (剛剛釋出的 5.0 版本, 改為了據說更先進的 BM25 演算法)
Term Frequency
某單個關鍵詞(term) 在某文件的某欄位中出現的頻率次數, 顯然, 出現頻率越高意味著該文件與搜尋的相關度也越高
具體計算公式是 tf(q in d) = sqrt(termFreq)
另外, 索引的時候可以做一些設定, "index_options": "docs" 的情況下, 只考慮 term 是否出現(命中), 不考慮出現的次數.
-
PUT /my_index -
{ -
"mappings": { -
"doc": { -
"properties": { -
"text": { -
"type": "string", -
"index_options": "docs" -
} -
} -
} -
} -
}
Inverse document frequency
某個關鍵詞(term) 在索引(單個分片)之中出現的頻次. 出現頻次越高, 這個詞的相關度越低. 相對的, 當某個關鍵詞(term)在一大票的文件下面都有出現, 那麼這個詞在計算得分時候所佔的比重就要比那些只在少部分文件出現的詞所佔的得分比重要低. 說的那麼長一句話, 用人話來描述就是 "物以稀為貴", 比如, '的', '得', 'the' 這些一般在一些文件中出現的頻次都是非常高的, 因此, 這些詞佔的得分比重遠位元殊一些的詞(如'Solr', 'Docker', '哈蘇')佔比要低,
具體計算公式是 idf = 1 + ln(maxDocs/(docFreq + 1))
Field-length Norm
欄位長度, 這個欄位長度越短, 那麼欄位裡的每個詞的相關度也就越大. 某個關鍵詞(term) 在一個短的句子出現, 其得分比重比在一個長句子中出現要來的高.
具體計算公式是 norm = 1/sqrt(numFieldTerms)
預設每個 analyzed 的 string 都有一個 norm 值, 用來儲存該欄位的長度,
用 "norms": { "enabled": false } 關閉以後, 評分時, 不管文件的該欄位長短如何, 得分都一樣.
-
PUT /my_index -
{ -
"mappings": { -
"doc": { -
"properties": { -
"text": { -
"type": "string", -
"norms": { "enabled": false } -
} -
} -
} -
} -
}
最後的得分是三者的乘積 tf * idf * norm
以上描述的是最原始的針對單個關鍵字(term)的搜尋. 如果是有多個搜尋關鍵詞(terms)的時候, 還要用到的 Vector Space Model
如果查詢複雜些, 或者用到一些修改了分數的查詢, 或者索引時候修改了欄位的權重, 比如 function_score 之類的,計算方式也就又更復雜一些.
看上去 TF/IDF 的演算法已經一臉懵逼嚇跑人了, 不過其實, 用 Explain 跑一跑也沒啥, 雖然各種開方, 自然對數的, Google一個科學計算器就是了.
舉個例子
-
/*先刪掉索引, 如果有的話*/ -
curl -XDELETE 'http://localhost:9200/blog' -
curl -XPUT 'http://localhost:9200/blog/' -d ' -
{ -
"mappings": { -
"post": { -
"properties": { -
"title": { -
"type": "string", -
"analyzer": "standard", -
"term_vector": "yes" -
} -
} -
} -
} -
}'
存入一些文件 (Water 隨手加進去測試的.)
-
curl -s -XPOST localhost:9200/_bulk -d ' -
{ "create": { "_index": "blog", "_type": "post", "_id": "1" }} -
{ "title": "What is the best water temperature, Mr Water" } -
{ "create": { "_index": "blog", "_type": "post", "_id": "2" }} -
{ "title": "Water no symptoms" } -
{ "create": { "_index": "blog", "_type": "post", "_id": "3" }} -
{ "title": "Did Vitamin B6 alone work for you? Water?" } -
{ "create": { "_index": "blog", "_type": "post", "_id": "4" }} -
{ "title": "The ball drifted on the water." } -
{ "create": { "_index": "blog", "_type": "post", "_id": "5" }} -
{ "title": "No water no food no air" } -
'
bulk insert 以後先用 Kopf 外掛輸出看一下, 5 個文件並不是平均分配在 5 個分片的, 其中, 編號為 2 的這個分片裡邊有兩個文件, 其中編號為 0 的那個分片是沒有分配文件在裡面的.

接下來, 搜尋的同時 explain
原本輸出的 json 即使加了 pretty 也很難看, 換成 yaml 會好不少
-
curl -XGET "http://127.0.0.1:9200/blog/post/_search?explain&format=yaml" -d ' -
{ -
"query": { -
"term": { -
"title": "water" -
} -
} -
}'
輸出如圖(json)

可以看到五個文件都命中了這個查詢, 注意看每個文件的 _shard
整個輸出 yml 太長了, 丟到最後面, 只截取了其中一部分, 如圖,

返回排名第一的分數是 _score: 0.2972674, _shard(2),
"weight(title:water in 0) [PerFieldSimilarity], result of:" 這裡的 0 不是 _id, 只是 Lucene 的一個內部文件 ID, 可以忽略.
排名第一和第二的兩個文件剛好是在同一個分片的, 所以跟另外三個的返回結果有些許不一樣, 主要就是多了一個 queryWeight, 裡面的 queryNorm 只要在同一分片下, 都是一樣的, 總而言之, 這個可以忽略(至少目前這個例子可以忽略)
只關注 fieldWeight, 排名第一和第二的的 tf 都是 1,
在 idf(docFreq=2, maxDocs=2) 中, docFreq 和 maxDocs 都是針對單個分片而言, 2號分片一共有 2個文件(maxDocs), 然後命中的文件也是兩個(docFreq).
所以 idf 的得分, 根據公式, 1 + ln(maxDocs/(docFreq + 1)) 是 0.59453489189
最後 fieldNorm, 這個 field 有三個詞, 所以是 1/sqrt(3), 但是按官方給的這個公式怎麼算都不對, 不管哪個文件. 後來查了一下, 說是 Lucene 存這個 lengthNorm 資料時候都是用的 1 byte來存, 所以不管怎麼著都會丟掉一些精度. 呵呵噠了 = . =
最後的最後, 總得分 = 1 * 0.5945349 * 0.5 = 0.2972674.
同理其他的幾個文件也可以算出這個得分, 只是都要被 fieldNorm 的精度問題蛋疼一把.
Elasticsearch 5 (Lucene 6) 的 BM25 演算法
Elasticsearch 前不久釋出了 5.0 版本, 基於 Lucene 6, 預設使用了 BM25 評分演算法.
BM25 的 BM 是縮寫自 Best Match, 25 貌似是經過 25 次迭代調整之後得出的演算法. 它也是基於 TF/IDF 進化來的. Wikipedia 那個公式看起來很嚇唬人, 尤其是那個求和符號, 不過分解開來也是比較好理解的.
總體而言, 主要還是分三部分, TF - IDF - Document Length

IDF 還是和之前的一樣. 公式 IDF(q) = 1 + ln(maxDocs/(docFreq + 1))
f(q, D) 是 tf(term frequency)
|d| 是文件的長度, avgdl 是平均文件長度.
先不看 IDF 和 Document Length 的部分, 變成 tf * (k + 1) / (tf + k),
相比傳統的 TF/IDF (tf(q in d) = sqrt(termFreq)) 而言, BM25 抑制了 tf 對整體評分的影響程度, 雖然同樣都是增函式, 但是, BM25 中, tf 越大, 帶來的影響無限趨近於 (k + 1), 這裡 k 值通常取 [1.2, 2], 而傳統的 TF/IDF 則會沒有臨界點的無限增長.
而文件長度的影響, 同樣的, 可以看到, 命中搜索詞的情況下, 文件越短, 相關性越高, 具體影響程度又可以由公式中的 b 來調整, 當設值為 0 的時候, 就跟之前 'TF/IDF' 那篇提到的 "norms": { "enabled": false } 一樣, 忽略文件長度的影響.
綜合起來,
k = 1.2
b = 0.75
idf * (tf * (k + 1)) / (tf + k * (1 - b + b * (|d|/avgdl)))
最後再對所有的 terms 求和. 就是 Elasticsearch 5 中一般查詢的得分了.
Related:
From: