
通過Function Score Query優化Elasticsearch搜尋結果(綜合排序)
在使用 Elasticsearch 進行全文搜尋時,搜尋結果預設會以文件的相關度進行排序,如果想要改變預設的排序規則,也可以通過sort指定一個或多個排序欄位。
但是使用sort排序過於絕對,它會直接忽略掉文件本身的相關度(根本不會去計算)。在很多時候這樣做的效果並不好,這時候就需要對多個欄位進行綜合評估,得出一個最終的排序。
function\_score
在 Elasticsearch 中function_score是用於處理文件分值的 DSL,它會在查詢結束後對每一個匹配的文件進行一系列的重打分操作,最後以生成的最終分數進行排序。它提供了幾種預設的計算分值的函式:
weight:設定權重field_value_factor:將某個欄位的值進行計算得出分數。random_score:隨機得到 0 到 1 分數- 衰減函式:同樣以某個欄位的值為標準,距離某個值越近得分越高
-
script_score:通過自定義指令碼計算分值它還有一個屬性
boost_mode可以指定計算後的分數與原始的_score如何合併,有以下選項: -
multiply:將結果乘以_score sum:將結果加上_scoremin:取結果與_score的較小值max:取結果與_score的較大值-
replace:使結果替換掉_score接下來本文將詳細介紹這些函式的用法,以及它們的使用場景。
weight
weight 的用法最為簡單,只需要設定一個數字作為權重,文件的分數就會乘以該權重。
他最大的用途應該就是和過濾器一起使用了,因為過濾器只會篩選出符合標準的文件,而不會去詳細的計算每個文件的具體得分,所以只要滿足條件的文件的分數都是 1,而 weight 可以將其更換為你想要的數值。
field\_value\_factor
field\_value\_factor 的目的是通過文件中某個欄位的值計算出一個分數,它有以下屬性:
-
field:指定欄位名
factor:對欄位值進行預處理,乘以指定的數值(預設為 1)
-
modifier將欄位值進行加工,有以下的幾個選項:none:不處理log:計算對數log1p:先將欄位值 +1,再計算對數log2p:先將欄位值 +2,再計算對數ln:計算自然對數ln1p:先將欄位值 +1,再計算自然對數ln2p:先將欄位值 +2,再計算自然對數square:計算平方sqrt:計算平方根reciprocal:計算倒數
舉一個簡單的例子,假設有一個商品索引,搜尋時希望在相關度排序的基礎上,銷量(
sales)更高的商品能排在靠前的位置,那麼這條查詢 DSL 可以是這樣的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
{
"query": {
"function_score": {
"query": {
"match": {
"title": "雨傘"
}
},
"field_value_factor": {
"field": "sales",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum"
}
}
}
|
這條查詢會將標題中帶有雨傘的商品檢索出來,然後對這些文件計算一個與庫存相關的分數,並與之前相關度的分數相加,對應的公式為:
1
|
_score = _score + log (1 + 0.1 * sales)
|
Java實現:
-
String index = "wareic"; -
String type = "product"; -
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index).setTypes(type); -
searchRequestBuilder.setSearchType(SearchType.DFS_QUERY_THEN_FETCH); -
//分頁 -
searchRequestBuilder.setFrom(0).setSize(10); -
//explain為true表示根據資料相關度排序,和關鍵字匹配最高的排在前面 -
searchRequestBuilder.setExplain(true); -
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery(); -
queryBuilder.must(QueryBuilders.matchQuery("title", "雨傘")); -
ScoreFunctionBuilder<?> scoreFunctionBuilder = ScoreFunctionBuilders.fieldValueFactorFunction("sales").modifier(Modifier.LN1P).factor(0.1f); -
FunctionScoreQueryBuilder query = QueryBuilders.functionScoreQuery(queryBuilder,scoreFunctionBuilder).boostMode(CombineFunction.SUM); -
searchRequestBuilder.setQuery(query); -
SearchResponse searchResponse = searchRequestBuilder.execute().get(); -
System.out.println(searchResponse.toString()); -
long totalCount = searchResponse.getHits().getTotalHits(); -
System.out.println("總條數 totalCount:" + totalCount); -
//遍歷結果資料 -
SearchHit[] hitList = searchResponse.getHits().getHits(); -
for (SearchHit hit : hitList) { -
System.out.println("SearchHit hit string:" + hit.getSourceAsString()); -
}
random\_score
這個函式的使用相當簡單,只需要呼叫一下就可以返回一個 0 到 1 的分數。
它有一個非常有用的特性是可以通過seed屬性設定一個隨機種子,該函式保證在隨機種子相同時返回值也相同,這點使得它可以輕鬆地實現對於使用者的個性化推薦。
衰減函式
衰減函式(Decay Function)提供了一個更為複雜的公式,它描述了這樣一種情況:對於一個欄位,它有一個理想的值,而欄位實際的值越偏離這個理想值(無論是增大還是減小),就越不符合期望。這個函式可以很好的應用於數值、日期和地理位置型別,由以下屬性組成:
- 原點(
origin):該欄位最理想的值,這個值可以得到滿分(1.0) - 偏移量(
offset):與原點相差在偏移量之內的值也可以得到滿分 - 衰減規模(
scale):當值超出了原點到偏移量這段範圍,它所得的分數就開始進行衰減了,衰減規模決定了這個分數衰減速度的快慢 -
衰減值(
decay):該欄位可以被接受的值(預設為 0.5),相當於一個分界點,具體的效果與衰減的模式有關例如我們想要買一樣東西:
-
它的理想價格是 50 元,這個值為原點
- 但是我們不可能非 50 元就不買,而是會劃定一個可接受的價格範圍,例如 45-55 元,±5 就為偏移量
-
當價格超出了可接受的範圍,就會讓人覺得越來越不值。如果價格是 70 元,評價可能是不太想買,而如果價格是 200 元,評價則會是不可能會買,這就是由衰減規模和衰減值所組成的一條衰減曲線
或者如果我們想租一套房:
-
它的理想位置是公司附近
- 如果離公司在 5km 以內,是我們可以接受的範圍,在這個範圍內我們不去考慮距離,而是更偏向於其他資訊
-
當距離超過 5km 時,我們對這套房的評價就越來越低了,直到超出了某個範圍就再也不會考慮了
衰減函式還可以指定三種不同的模式:線性函式(linear)、以 e 為底的指數函式(Exp)和高斯函式(gauss),它們擁有不同的衰減曲線:
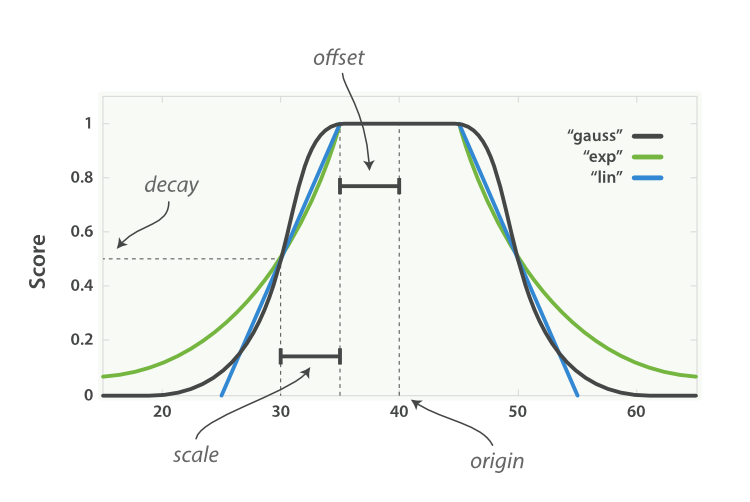
將上面提到的租房用 DSL 表示就是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
{
"query": {
"function_score": {
"query": {
"match": {
"title": "公寓"
}
},
"gauss": {
"location": {
"origin": { "lat": 40, "lon": 116 },
"offset": "5km",
"scale": "10km"
}
},
"boost_mode": "sum"
}
}
}
|
我們希望租房的位置在40, 116座標附近,5km以內是滿意的距離,15km以內是可以接受的距離。
衰減函式Java實現:
-
String index = "wareic"; -
String type = "product"; -
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index).setTypes(type); -
searchRequestBuilder.setSearchType(SearchType.DFS_QUERY_THEN_FETCH); -
//分頁 -
searchRequestBuilder.setFrom(0).setSize(50); -
//explain為每個匹配到的文件產生一大堆額外內容,設為 true就可以得到更詳細的資訊; -
//輸出 explain 結果代價是十分昂貴的,它只能用作除錯工具 。千萬不要用於生產環境 -
searchRequestBuilder.setExplain(false); -
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery(); -
queryBuilder.must(QueryBuilders.matchQuery("nicknames.nickname", "菜")); -
//原點(origin):該欄位最理想的值,這個值可以得到滿分(1.0) -
double origin = 200; -
//偏移量(offset):與原點相差在偏移量之內的值也可以得到滿分 -
double offset = 30; -
//衰減規模(scale):當值超出了原點到偏移量這段範圍,它所得的分數就開始進行衰減了,衰減規模決定了這個分數衰減速度的快慢 -
double scale = 40; -
//衰減值(decay):該欄位可以被接受的值(預設為 0.5),相當於一個分界點,具體的效果與衰減的模式有關 -
double decay = 0.5; -
//高斯函式 -
// GaussDecayFunctionBuilder functionBuilder = ScoreFunctionBuilders.gaussDecayFunction("productID", origin, scale, offset, decay); -
//以 e 為底的指數函式 -
ExponentialDecayFunctionBuilder functionBuilder = ScoreFunctionBuilders.exponentialDecayFunction("productID", origin, scale, offset, decay); -
//線性函式 -
// LinearDecayFunctionBuilder functionBuilder = ScoreFunctionBuilders.linearDecayFunction("productID", origin, scale, offset, decay); -
FunctionScoreQueryBuilder query = QueryBuilders.functionScoreQuery(queryBuilder,functionBuilder).boostMode(CombineFunction.SUM); -
searchRequestBuilder.setQuery(query); -
SearchResponse searchResponse = searchRequestBuilder.execute().get(); -
System.out.println(searchResponse.toString()); -
long totalCount = searchResponse.getHits().getTotalHits(); -
System.out.println("總條數 totalCount:" + totalCount); -
//遍歷結果資料 -
SearchHit[] hitList = searchResponse.getHits().getHits(); -
for (SearchHit hit : hitList) { -
System.out.println("SearchHit hit string:" + hit.getSourceAsString()); -
}
script\_score
雖然強大的 field\_value\_factor 和衰減函式已經可以解決大部分問題了,但是也可以看出它們還有一定的侷限性:
- 這兩種方式都只能針對一個欄位計算分值
-
這兩種方式應用的欄位型別有限,field\_value\_factor 一般只用於數字型別,而衰減函式一般只用於數字、位置和時間型別
這時候就需要 script\_score 了,它支援我們自己編寫一個指令碼執行,在該指令碼中我們可以拿到當前文件的所有欄位資訊,並且只需要將計算的分數作為返回值傳回 Elasticsearch 即可。
注:使用指令碼需要首先在配置檔案中開啟相關功能:
1
2
3
4
5
|
script.groovy.sandbox.enabled: true
script.inline: on
script.indexed: on
script.search: on
script.engine.groovy.inline.aggs: on
|
舉一個之前做不到的例子,假如我們有一個位置索引,它有一個分類(category)屬性,該屬性是字串列舉型別,例如商場、電影院或者餐廳等。現在由於我們有一個電影相關的活動,所以需要將電影院在搜尋列表中的排位相對靠前。
之前的兩種方式都無法給字串打分,但是如果我們自己寫指令碼的話卻很簡單,使用 Groovy(Elasticsearch 的預設指令碼語言)也就是一行的事:
1
|
return doc ['category'].value == '電影院' ? 1.1 : 1.0
|
接下來只要將這個指令碼配置到查詢語句中就可以了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
{
"query": {
"function_score": {
"query": {
"match": {
"name": "天安門"
}
},
"script_score": {
"script": "return doc ['category'].value == '電影院' ? 1.1 : 1.0"
}
}
}
}
|
或是將指令碼放在elasticsearch/config/scripts下,然後在查詢語句中引用它:
category-score.groovy:
1
|
return doc ['category'].value == '電影院' ? 1.1 : 1.0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
{
"query": {
"function_score": {
"query": {
"match": {
"name": "天安門"
}
},
"script_score": {
"script": {
"file": "category-score"
}
}
}
}
}
|
在script中還可以通過params屬性向指令碼傳值,所以為了解除耦合,上面的 DSL 還能接著改寫為:
category-score.groovy:
1
|
return doc ['category'].value == recommend_category ? 1.1 : 1.0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
{
"query": {
"function_score": {
"query": {
"match": {
"name": "天安門"
}
},
"script_score": {
"script": {
"file": "category-score",
"params": {
"recommend_category": "電影院"
}
}
}
}
}
}
|
這樣就可以在不更改大部分查詢語句和指令碼的基礎上動態修改推薦的位置類別了。
同時使用多個函式
上面的例子都只是呼叫某一個函式並與查詢得到的_score進行合併處理,而在實際應用中肯定會出現在多個點上計算分值併合並,雖然指令碼也許可以解決這個問題,但是應該沒人願意維護一個複雜的指令碼吧。這時候通過多個函式將每個分值都計算出在合併才是更好的選擇。
在 function\_score 中可以使用functions屬性指定多個函式。它是一個數組,所以原有函式不需要發生改動。同時還可以通過score_mode指定各個函式分值之間的合併處理,值跟最開始提到的boost_mode相同。下面舉兩個例子介紹一些多個函式混用的場景。
第一個例子是類似於大眾點評的餐廳應用。該應用希望向使用者推薦一些不錯的餐館,特徵是:範圍要在當前位置的 5km 以內,有停車位是最重要的,有 Wi-Fi 更好,餐廳的評分(1 分到 5 分)越高越好,並且對不同使用者最好展示不同的結果以增加隨機性。
那麼它的查詢語句應該是這樣的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
{
"query": {
"function_score": {
"filter": {
"geo_distance": {
"distance": "5km",
"location": {
"lat": $lat,
"lon": $lng
}
}
},
"functions": [
{
"filter": {
"term": {
"features": "wifi"
}
},
"weight": 1
},
{
"filter": {
"term": {
"features": "停車位"
}
},
"weight": 2
},
{
"field_value_factor": {
"field": "score",
"factor": 1.2
}
},
{
"random_score": {
"seed": "$id"
}
}
],
"score_mode": "sum",
"boost_mode": "multiply"
}
}
}
|
注:其中所有以$開頭的都是變數。
這樣一個飯館的最高得分應該是 2 分(有停車位)+ 1 分(有 wifi)+ 6 分(評分 5 分 \* 1.2)+ 1 分(隨機評分)。
另一個例子是類似於新浪微博的社交網站。現在要優化搜尋功能,使其以文字相關度排序為主,但是越新的微博會排在相對靠前的位置,點贊(忽略相同計算方式的轉發和評論)數較高的微博也會排在較前面。如果這篇微博購買了推廣並且是建立不到 24 小時(同時滿足),它的位置會非常靠前。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
{
"query": {
"function_score": {
"query": {
"match": {
"content": "$text"
}
},
"functions": [
{
"gauss": {
"createDate": {
"origin": "$now",
"scale": "6d",
"offset": "1d"
}
}
},
{
"field_value_factor": {
"field": "like_count",
"modifier": "log1p",
"factor": 0.1
}
},
{
"script_score": {
"script": "return doc ['is_recommend'].value && doc ['create_date'] > time ? 1.5 : 1.0",
params: {
"time": $time
}
}
}
],
"boost_mode": "multiply"
}
}
}
|
它的公式為:
1
|
_score * gauss (create_date, $now, "1d", "6d") * log (1 + 0.1 * like_count) * is_recommend ? 1.5 : 1.0
|