
如何從零構建實時的個性化推薦系統?
前言
在移動網際網路迅速發展的今天,資訊量爆發性增長,人們獲取資訊的途徑越來越多,如何從大量的資訊中獲取我們想要的內容,成為了推薦系統研究的重點。 隨著大資料產業的不斷壯大,推薦系統在企業也越來越重要,從亞馬遜的“猜您喜歡”,到阿里雙十一手機淘寶的“千人千面”,無一不彰顯著推薦系統至關重要的作用。
相比之下, 訊息推送作為傳遞資訊的一種重要的手段,能夠有效地提高活躍度,被各大App廠商廣泛使用,本應有很大的發展。 但是由於終端上應用越來越多,每天各大App推送的資訊也越來越龐大,加上資訊都是千篇一律,沒有新意, 不但不能起到響應的作用, 反而會引起使用者強烈的反感,使用者收到的推送資訊,基本都會忽略, 刪除,甚至完全限制推送。
隨著推薦系統的成熟,將其應用於推送變成了可能, 通過推薦系統尋找使用者關注的焦點,精準定位使用者興趣,從而推送使用者感興趣的內容,達到提升推送的效果。
個性化推送整體架構
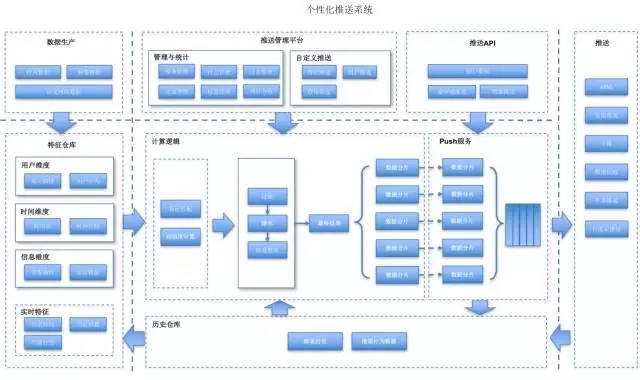
個性化推送的核心思想,是將推薦系統與推送系統結合,用推薦系統提取使用者感興趣的內容給使用者推送,提高使用者對推送訊息的點選率,提升推送效果。
從個性化推送架構圖上可以看出,個性化推送系統,核心元件有三層:資料層、計算邏輯層和推送服務層。
-
基礎資料層 是個性化推送的基礎, 通過資料,將使用者與資訊相關聯,通過特徵,將使用者與使用者相區分,從而達到千人千面的效果。
-
計算邏輯層
是個性化推送的核心,通過特徵匹配等相關的邏輯運算,將使用者和資訊做關聯,篩選更適合的資料,計算邏輯直接影響到個性化推送的準確度。 -
推送服務層 是個性化推送與使用者互動的通道。推送服務,間接地影響到個性化推送的到達率,影響著推送的效果。
資料層
推薦系統的基本任務是聯絡使用者和內容,解決資訊過載的問題。 想要做到使用者和內容更大程度的匹配, 就必須去深入瞭解使用者和資訊。 在這裡,我們將資料分為三個維度, 方便對用於,資訊的把握。
-
使用者維度資料
-
資訊維度資料
-
時間維度資料
1
使用者維度資料
使用者維度資料,是用來描述使用者的特徵資料。 瞭解使用者,一般從使用者標籤屬性和使用者行為屬性兩個層面入手。
-
使用者標籤屬性是用來描述使用者的靜態特徵屬性,如使用者的性別,年齡,喜好,出行偏好,住址等。
-
使用者行為資料,簡單來說就是使用者的行為日誌,使用者在網際網路上的任何行為,都會產生日誌, 比如使用者瀏覽了哪個網站,使用者搜尋了哪個名詞,使用者點選了哪個廣告,使用者播放了哪個視訊等等,都屬於使用者行為資料。 使用者行為常被分為兩類,顯性反饋行為和隱性反饋行為。顯性反饋行為是指使用者明確表示物品喜好的行為, 如常見的評分,點贊等。 隱性反饋行為是指那些不能明確反映使用者喜好的行為。常見的有頁面瀏覽的行為。 使用者瀏覽一個頁面,不代表使用者一定喜歡這個頁面展現的物品,很有可能只是因為這個頁面在首頁,使用者更容易點選而已。
對收集的使用者特徵做融合,根據不同的方向,對使用者特徵庫做劃分, 方便之後的使用。
我們整理了使用者常見的一些特徵指標,如下:

所屬的行業不同,所關注的使用者特徵也不同,不同的行業,會對使用者在某一方面有更細緻的特徵描述。
從原始的使用者行為資料,使用者標籤資料,以及其它第三方的資料中,提取我們所要關注的特徵值,形成特徵向量,為後續資訊篩選做準備。
2
資訊維度資料
資訊維度資料,用於描述資訊的特徵屬性。 不同種類的訊息內容,用不同的特徵指標來標識。

上述的三個類似,列舉了舞蹈,視訊,音樂三個型別內容所關注的特徵。 更細、更準確的特徵描述,有利於我們更加準確地去匹配內容。
3
時間維度資料
時間維度資料,就是與時間相關的使用者特徵和資訊特徵。 如使用者當前在中關村, 中關村某店未來三小時有搶購活動等。 在使用這些特徵的時候,一定要注意其時效性。
計算邏輯層
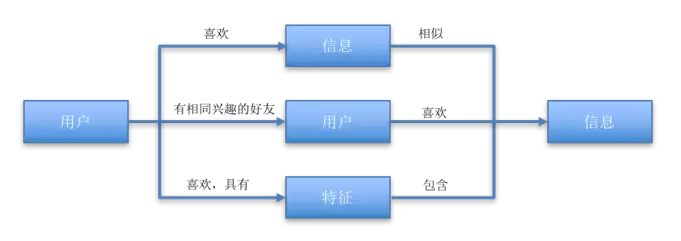
我們準備好了使用者和內容之後,接下來要做的就是連線使用者和內容。 推薦系統連線使用者和內容的方式有三種:
-
使用者資訊匹配:使用者喜歡某些特徵的內容,如果資訊裡包含了這些特徵,則認為該內容是使用者最有可能感興趣的內容;
-
資訊匹配:利用使用者之前喜歡的內容,尋找與這些內容相似的內容,視為使用者最有可能感興趣的內容;
-
使用者匹配:根據使用者特徵尋找相似的使用者,將相似使用者所感興趣的內容視為該使用者最有可能感興趣的內容;
使用者資訊匹配,是直接通過使用者特徵和資訊特徵做匹配,篩選出使用者感興趣的內容,這種方式計算方式簡單,直接了當,但是覆蓋面比較窄,能夠完全匹配上的內容佔很少一部分,為了擴大召回, 將大部分特徵相匹配的資訊也篩選出來,視為使用者最感興趣的內容。 資訊匹配和使用者匹配,則是典型的協同過濾,更多是計算相似度,資訊匹配計算內容的相似度,使用者匹配則是計算使用者的相似度, 於是使用者和資訊的連線問題轉化為了計算相似度的問題。
常用的計算相似度的演算法有以下幾種:
-
毆氏距離或者曼哈頓距離
-
餘弦相似度
-
皮爾遜相關係數
兩個n維向量的毆氏距離計算公式如下:

兩個n維向量的曼哈頓距離計算公式如下:
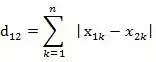
兩個n維向量的餘弦係數如下:
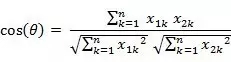
兩個n維向量的皮爾遜係數如下:

這裡不再贅述各個公式的由來以及推倒,有興趣大家可以自行查詢相關文章。 一般的,如果資料比較稠密,而且屬性值大小都比較重要,則採用毆氏距離或者曼哈頓距離,如果資料稀疏,考慮使用餘弦距離,如資料受到分數貶值的影響(及不同的型別採用不同的評分),則使用皮爾遜相關係數。
經過特徵匹配和若干輪的相似度計算後,我們拿到了一個初步的使用者資訊匹配結果集, 接下來我們會對結果集做進一步的處理。
-
過濾:主要是根據推送的歷史,將之前推送過的資訊過濾掉,同時,我們會根據實際情況,將不滿足要求,或者質量比較差的資訊過濾掉
-
排名:主要是擬定推送資訊的優先順序, 一般按照新穎性,多樣性和使用者反饋等規則來做排序,新穎性保證了儘量給使用者推送他們不知道的,長尾的資訊,多樣性保證使用者可以獲取更廣的內容,而使用者反饋則通過收集使用者真實的意願(如通過使用者對推送內容的開啟,關閉操作反應使用者的喜好)實現更優的排序。
-
資訊整理:選擇最優內容,形成訊息,進行推送
這只是簡單介紹了一下資料處理和匹配的邏輯,在具體的實現過程中,需要考慮特徵權重的問題, 特徵權重對特徵匹配,結果排序等影響較大。
推送服務
推送服務,作為個性化訊息的出口, 根據客戶端的種類,也被分為了Apple和Android兩大體系。 Apple系推送服務統一將推送資訊送入apns,由apns負責後續推送工作。 Android則通過後臺守護程序,和推送服務建立聯絡後獲取推送內容。 目前行業內有很多開放的推送服務,如umeng推送,信鴿推送,個推等,基本上都是對上述功能的封裝。 一些開源推送服務,如umeng, 由於背靠阿里,和所有阿里系應用共享推送資料通道(也就是後臺的守護程序), 大大提高了訊息的到達率。
個性化推送,在推送的內容和時機上都是離散的,所以很難做到批量推送,這就對推送服務的設計和效能提出了比較高的要求。 我們推送服務做了如下改進:
-
資料區域性聚合:將相同訊息內容的推送放在一起, 這樣就可以做區域性的批量推送,增加服務吞吐
-
資料分片:將不同訊息內容的推送分割為不同的資料片, 不同的資料片可以並行推送, 提高推送效率
-
守護執行緒:每臺服務例項都保留一個守護執行緒,用於監控推送過程,確保推送有且僅有一次送達
基於使用者位置的個性化推送
在個性化推送的基礎上,藉助於LBS,我們完成一個新的推送場景的嘗試,這就是基於使用者位置的實效性個性化推送推送。 當你步入中關村商圈,那裡的新中關購物中心正在搞活動,其中耐克正在打折,從你的使用者特徵可以看出,你是個運動達人,最近在某電商網站上瀏覽了多次運動鞋, 這個時候,我們為你推送了耐克打折的這個訊息, 這就是一個典型的基於位置的個性化推送場景。
通過定位服務獲取使用者的實時位置資料,通過計算,獲取與參照物的位置關係,結合上述的個性化推送,為使用者推送該參照物範圍內使用者感興趣的內容。 一般的,通過空間索引,來提高計算地理位置關係的效能,空間索引分為兩類:
-
網狀索引, 如geohash等
-
樹狀索引, 如R樹,四差樹等
可以根據時間的場景來選擇不同的空間索引。