
SQL Server列儲存實現方案
SQL Server從2012版本開始支援列儲存,但2012版本使用列儲存會導致表進入只讀狀態;2014版本使用可更新聚集列儲存索引技術解決了只讀的問題,使用列儲存的表支援修改;2016版本列儲存支援操作分析,能夠對事務工作負載執行高效能實時分析。
列儲存索引是一種使用列式資料格式(稱為“列儲存”)儲存、檢索和管理資料的技術。聚集列儲存索引是整個表的物理儲存。
以下將對聚集列儲存索引技術的實現方案進行分析。
目錄
資料儲存&劃分
行組
關係型資料庫中,資料以行寫入,列儲存首先需要將表的行資料劃分為行組,再將行組中的列進行壓縮,為了提高效能和壓縮率,行組中的行數必須足夠大,每個行組最多包含1,048,576 行。

列段
上面說到列儲存首先要劃分行組,再將行組中的列進行壓縮,這裡壓縮的單位稱為列段

物理儲存
聚集列儲存索引是整個表的物理儲存,磁碟的每個Page僅僅儲存來自單列的值。為了減少列段碎片和提升效能,列儲存索引可能會將一些資料暫時儲存到稱為“增量儲存”(DeltaStore)的聚集索引中。
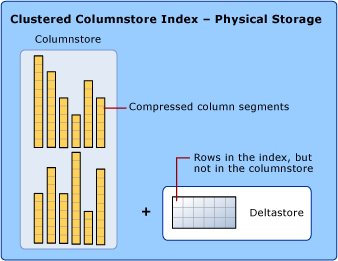
增量行組
上面提到“增量儲存”(DeltaStore),“增量儲存”就是所有增量行組(B-tree結構)的統稱。增量行組通過儲存行資料,並在行數達到閾值後將行移入列儲存,從而提升了列儲存壓縮率和效能。在增量行組達到最大行數後,它會關閉。 元組移動程序(tuple-mover) 會檢查是否有已關閉行組。將已關閉的行組進行壓縮,儲存到列儲存中。
Tuple Mover
當不斷有資料插入列儲存表的時候,DeltaStore中的資料會越來越多,因為DeltaStore是B-Tree結構,相對列儲存結構效能降低,當DeltaStore中的資料增多時,查詢效能會隨之降低。
為了解決這個問題,SQL Server 2014引入了一個稱為Tuple Mover的後臺程序。Tuple Mover後臺程序會週期性的檢查DeltaStore中已關閉的增量行組,並將其壓縮轉化為相應的列段。
Tuple Mover程序每次讀取一個已關閉的增量行組,在此過程中,並不會阻塞其他程序對DeltaStore的讀取操作(但會阻塞併發刪除和更新操作)。當Tuple Mover完成壓縮處理和轉化以後,會建立一個使用者可見的新的列段,並使DeltaStore結構中相應的資料不可見(真正的刪除操作會等待所有讀取該Delta Store程序退出後進行),在這以後的使用者讀取行為會直接從壓縮後的列儲存中讀取。

資料操作
對於更新操作中的刪除動作,聚集列儲存索引採用的是標記刪除的方式,而沒有立即物理刪除column store中的資料。為了達到標記刪除的目的,SQL Server 2014引入了另一個B-Tree結構Delete Bitmap,Delete Bitmap中記錄了被標記刪除的Row Group對應的RowId,在後續查詢過程中,系統會過濾掉已經被標記刪除的Row Group。實際上聚集列儲存索引本身是不可變的。它是在藉助了兩個可變結構以後,達到了可更新的目的。
query
由於columnstore只是將列的資料儲存在一起,但各個列儲存的位置都不同,在查詢時是如何將各個列的資料建立成行資料的 —— 資料的位置標明它屬於哪一行。
舉個例子:如果表有C1和C2兩個欄位,在列儲存中 C1欄位中位置1儲存值與C2欄位中位置1儲存的值屬於同一行。

insert
執行insert操作時,insert的資料不會直接進度列儲存中,而是先暫存在DeltaStore的增量行組中,DeltaStore中增量行組的資料會在達到行數上限或者列儲存索引重建時進入列儲存。
delete
執行DELETE操作的時候,如果要刪除的資料在DeltaStore中,則將DeltaStore中該資料刪除。如果要刪除的資料在列儲存中,並不會直接從列儲存中直接刪除資料,而是往Delete Bitmap結構中插入一條帶有rowid的記錄,系統會在列儲存索引重建(Rebuild)的時候最終刪除列儲存中的資料。DELETE操作完成後的資料讀取操作,SQL Server從列儲存中讀取資料,然後通過rowid過濾掉在Delete Bitmaps中已經標記刪除的資料,最後返回給使用者。
rowid由系統生成,代表資料的位置,結合上面query章節的描述可知rowid與ColumnStore中每列的值如何對應。
update
執行update操作時,實際上會被拆分成delete和insert兩個操作,先在Delete Bitmap中插入一條帶有舊資料rowid的記錄,將舊資料標記為刪除,然後在DeltaStore插入新資料。
BULK LOADING
在Bulk LOADING大批次資料匯入介紹之前,我們必須要重點介紹幾個重要的數字:
- 102400:資料是否直接進入Column Store的Row Group 行數的最小臨界值。
- 1048576:一個Row Group可以容納的最大行數。
- BatchSize:Bulk Insert操作的引數,表示每批次處理的記錄數。
- Rows:需要批量匯入聚集列儲存索引表的記錄總數,Rows應該總是大於等於0的整數。

如圖所示,批量載入時:
- 不會預先為資料排序。 按接收順序將資料插入行組。
- 如果批大小 >= 102400,行將直接插入壓縮的行組。 建議選擇 >= 102400 的批大小以提高批量匯入的效率,因為這樣可以避免在後臺執行緒“元組發動機”(TM) 最終將行移到壓縮行組之前,將資料行移到增量行組。
- 如果批大小 < 102,400 或者剩餘行數 < 102,400,行會載入增量行組。
優缺點
優點
1. 與面向行的傳統儲存相比,最多可實現 10 倍的資料倉庫查詢效能提升
-
只須讀取需要的列。因此,從磁碟讀到記憶體中、然後從記憶體移到處理器快取中的資料量減少了。
-
列經過了高度壓縮。這將減少必須讀取和移動的位元組數。
-
大多數查詢並不會涉及表中的所有列。 因此,許多列從不會進入記憶體。這一點與出色的壓縮方法相結合,可改善緩衝池使用率,從而減少總 I/O
-
高階查詢執行技術以簡化的方法處理列塊(稱為“批處理”),從而減少CPU使用率(?)
2. 與未壓縮資料大小相比,可最多實現 10 倍資料壓縮
缺點
1. 更新成本高,更新或刪除資料後磁碟空間不會釋放,需要重建列儲存索引(IO密集型操作)才能回收空間。
2. 整個表僅允許建立一個聚集列儲存索引,不允許再有其他的索引
3. 連結伺服器不可訪問聚集列儲存索引表
4. 聚集列儲存索引沒有對資料做任何排序
5. 聚集列儲存索引表不支援遊標和觸發器
6. 部分資料型別不支援,比如 image/text/varchar(max)/xml等
疑問
1. 每個page僅儲存單列的值, 每個page大小為 8KB, 每個列段至少102400個數據,一個列段儲存在一個還是多個page中?
如果一個列段儲存到多個page:壓縮時一個列段的資料是一起壓縮的,如果儲存在多個page,讀取時則讀取多個page來解壓縮?
如果一個列段儲存到一個page: 102400個數據,壓縮後資料量可能超過8KB如何處理?
2. 刪改和更新時產生的垃圾資料,需要進行列儲存索引重建才能釋放,索引重建時是否允許對錶進行操作?索引重建的代價?(暫時不清楚)
參考資料: