
SQL Server 列儲存索引強化
SQL Server 列儲存索引強化
1. 概述
之前SQL Server只有2個儲存組織方式,heaps和Btree,都是基於行的。SQL Server 2012之後加入了新的儲存方式是,列儲存壓縮方式。還加入了新的查詢處理方式,batch處理。
在SQL Server 2012中有不少限制,會在之後的版本中被修正:
1.列儲存索引可更新。
2.可以當主儲存方式用,比如聚集索引。
3.可以進一步壓縮,減少使用空間。
4.batch處理方式得到很大的擴充套件和加強。
2.背景
2.1 索引儲存

如圖演示了列儲存索引是如何建立和儲存的。注意在列儲存索引中資料是不排序的。在一個column segment也沒有排序。如圖中顯示,segment和目錄會被以blob的方式儲存每個column segment和目錄都以獨立的blob儲存。一個blob可能分佈在不同的磁碟page上,但是是有blob機制自動控制的。
目錄儲存了segment位置的資訊,所以所有segment包含了一個列和任何相關的目錄資訊可以被簡單的定位。目錄也包含了額外的元資料。
2.2 快取和I/O
Column segment和目錄根據需要會被載入到記憶體中。但是並不會被儲存在buffer pool中,有一個新的
2.3 Batch處理方式
SQL Server傳統使用行模式,新的查詢操作有些引入了batch模式。
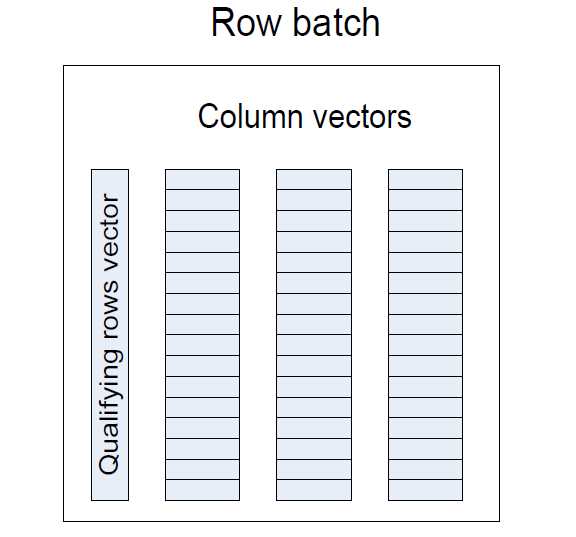
一個batch通常是由幾千行組成,如圖,每個列被儲存在連續的元素長度固定的向量上。Batch的執行方式效率很高,比如執行col1<5過濾,只需要掃描col1的向量比較執行,並且設定在qualifying row向量上的bit位。
SQL Server 2012只對一些操作符支援了batch模式,如
Cpu在hash join上的減少很顯著,行模式每行要用600個指令,但是batch模式只需要85個指令。
優化器會決定使用行模式還是batch模式。Batch模式通常被用在資料密集計算,行模式通常使用在小輸入,計算在樹上完成,或者不支援batch操作的地方。
3 聚集索引
在SQL Server 2012中,列儲存只能以secondary 索引方式存在,之後的版本SQL Server會取消這個限制。並且允許列儲存來組織表資料。
3.1 提高索引建立
SQL Server列儲存使用另一種目錄來編碼。在經常出現的值上,使用32bit對應到目錄上。SQL Server使用2種目錄,一個是全域性目錄和整個列相關,一個是區域性目錄,只和當前row group相關。
修改了建立索引的過程,現在過程分為2步:
1.採集每個列的資料,然後決定是否要為這個列建立一個全域性的目錄,並選一些資料放入到全域性目錄上。
2.使用第一步生成的全域性目錄來建立一個索引。
列儲存的建立過程是很耗記憶體的,因此會在建立之前先保留好記憶體,根據保留的記憶體和每個執行緒需要的記憶體決定執行緒個數。初始的記憶體評估是不準確的,因為記憶體分配和資料有關很難準確評估。為了解決這個問題,使用動態的決定活動的執行緒個數來解決,build過程會監控記憶體的消耗來決定活動執行緒個數。
3.2 取樣的支援
SQL Server的優化器使用資料分佈的統計資訊來優化查詢。統計資訊是一個直方圖,由隨機取樣活得。非聚集的列儲存索引不需要支援取樣,因為統計資訊可以通過基表活得。
統計資訊的取樣有2種方式:
1. 不太準確的,對io,cpu要求不高。
2. 準確的,io,cpu開銷較大。
效能優化的取樣掃描使用叢集取樣,即,一組row groups會被隨機選擇,行的掃描取決於取樣率。沒有被選中的row groups不會被讀取。從btree和heap上取樣也使用聚集取樣的方式。
第二種方式是真實的隨機行級別的取樣。掃描所有的列並且隨機選擇一些行的子集。這樣取樣會比btree和heap上取樣要準確。列儲存的聚集取樣只是用來幫助目錄的建立,不會被用於查詢優化。
3.3 BookMark的支援
在SQL Server BookMark是一個術語唯一的標示一行。在SQL Server中任何索引都可以被bookmark定位。最多的應用是在刪除操作上,刪除的時候會先收集bookmark然後在實際刪除行之前先刪除bookmark。因為列儲存索引沒有key來唯一標示一行,所以我們使用唯一標示row group中一行的tupleid和row group id組合來唯一標示使用。
3.4 其他加強
SQL Server 2012對某些列不支援,後續版本會對這部分型別支援,對於字串,以後支援儲存短字串的值,而不是轉為32bit的id。
4 更新處理
列儲存對讀取效能提升很大,但是直接對資料修改花費也很大。列儲存的設計目的是資料倉庫的事實表,通常有大量的insert,刪除和更新很少。老的資料定期刪除可以通過分割槽切換實現,高效能的常規插入和批量插入比較關鍵。
SQL Server使用了2個元件來自持列儲存可更新:delete bitmap和delta stores。
每個列儲存索引都有一個關聯的delete bitmap,在掃描disqualify rows的時候會去查詢bitmap過濾被刪除的行。在記憶體和磁碟上bitmap結構是不同的,在記憶體中是bitmap,但是在磁碟上則是btree。
插入的或者修改的會被插入到delta store,delta store是btree行模式儲存。Delta store對列儲存掃描是透明的。
有了這些元件,列儲存的增刪改就可以實現了:
insert:直接把新行插入到delta store,因為是btree所以可以高效的完成
delete:若行被刪除會把包含一個rowid的記錄儲存到儲存了delete bitmap的btree中。如果行在delta store比較簡單可以直接從btree中刪除。
update:update操作會被分為delete和insert
merge:Merge操作也會被分為delete,insert或者update操作。

Delta store和對應的列儲存有的列是一樣的。唯一鍵是rowid由系統生成。
列儲存可能有多個delta store,當有行要插入的時候,會建立新的delta store。Delta store到達上限之後就會關閉。SQL Server會自動檢查關閉的delta store並把它們轉化為列儲存的方式。處理這個的任務被稱為Tuple Mover,定期的在後臺執行,不會堵塞讀,但是會堵塞刪除。
Tuple Mover讀取一個關閉的delta store,開始建立相關的壓縮segment,當建立完新的segment會被設定為可見,相關的delta store就不可見了。Tuple Mover等delta store上的掃描都完成之後就會刪除這個delta store。
4.1 隨機插入
通常非批量插入,在這裡都稱為隨機插入。插入到列儲存對查詢處理是透明的。有內部的訪問方法層負責delta store的處理。
4.2 批量插入
大的bulk insert不會把行直接插入到delta store而是直接把一批行轉化為列儲存。這個操作會快取行,直到累計的行數滿足可以轉化為列儲存的條件,並把結果segment和目錄寫入到磁碟。這個很有效減少IO的需求。
當bulk insert完成的時候,必須壓縮並且關閉資料,bulk insert API中的batch_size是指一次bulk insert的行數。為了提高壓縮效率,建議把batch size設定為1MB。
雖然有時候batch size很大但是無法滿足壓縮row group的條件,SQL Server會自動的把這些行放入delta store。
4.3 刪除和更新
對於刪除操作,會直接把刪除行的rowid寫入到delete bitmap 上。Update操作則為被分為insert和delete 2個部分。
4.4 對查詢處理的影響
Delta store和delete bitmap的控制是由訪問方法層處理的,對查詢處理層透明。
在掃描列儲存時,發現rowid 存在在delete bitmap那麼這個行就會被跳過,這個操作也是在訪問方法層處理,對查詢處理器透明。
The process of segment elimination during scans (by checking segment metadata containing the minimum and maximum values in columns) does not need to consult the deleted bitmap. The interval between the minimum and maximum values within a column cannot grow when rows are deleted. Therefore, the original minimum and maximum values computed during column store segment creation can safely be used for segment elimination even after deletes.
有大量的delete會減少io的效能,因為delete bitmap 會變大。
併發掃描delta store是為每個delta分配一個執行緒,因為一個delta store併發掃描會顯得delta store 太小。Delta store的掃描比列儲存掃描慢,因為delta store是列儲存會讀入不必要的列。
5 查詢處理和優化
在SQL Server 2012中Batch處理之應用在大量查詢的資料倉庫的場景。batch處理圖形比較呆板,join循序是根據基數評估確定。當記憶體無法滿足要求是,會使用行模式執行。
之後的SQL Server版本,Batch處理有更強的能力。會考慮執行計劃中的迭代器的batch執行,不管輸入是不是使用batch執行的,不管資料的組織方式是列還是行。並且join的循序不再固定。Batch操作支援所有的join型別,union all,標量聚集。

如圖計劃是混合模式的,紅色框框是行模式處理。
5.1 混合執行模式
在SQL Server 行和batch之間轉化由計劃規定,轉化只有在必要的情況下才會發生。後續版本的SQL Server會有全新的模式來處理行和batch之間的轉化。
5.2 Hash Join
一開始只有inner join支援,現在已經支援所有join型別。
必須要有足夠的記憶體來建立hash表,如果沒有就會從batch模式轉化為row模式可以支援低記憶體情況下執行,通過把資料spilling到磁碟來降低記憶體使用。
提高了bitmap過濾的實現。
5.2.1 spilling
以簡單的join為例,hash join的spill:
Build階段:在build之前資料通過hash函式被分為若干個buckets。當決定spill的,選擇一個bucket然後標記為spilling,建立一個新的臨時檔案,並把bucket資料寫入到檔案中並釋放記憶體。
Probe階段:在處理probe時,不對輸入的行進行分割槽但是在lookup hash表之前先回去檢查相關的bucket是否在記憶體中,如果不在記憶體中,則寫入存probe記錄的臨時檔案中,之後留下一對對的build-probe,為每對都應用相同的演算法只是以檔案輸入。
Spilling的時候就個簡單的規則,總是spilling行較多的。
5.3 Bitmap過濾
下一個版本中會修改bitmap過濾生產的和在計劃中的位置,在SQL Server 2012中優化器會決定bitmap過濾的準確位置:
好處:不需要花時間來移動bitmap。
壞處:限制bitmap過濾了其他好處。
在每個join下面加個bitmap 過濾被證明是不可行的,是因為會導致邏輯計劃空間爆炸,為了避免這個,hash join操作會儲存bitmap和它建立的評估的選擇度,再是現實把選擇度資訊轉給子操作,可以讓他來調整cost來計算bitmap的選擇度。
Bitmap有2種:
簡單的bitmap:就是hash 表,由一個int值為索引的bit陣列
修改過的bitmap:就是bloom filter,優化了cpu cache 的使用。
6 歸檔壓縮
某些資料,越老使用的就越少,所以這種情況下可以使用列儲存的歸檔壓縮。
歸檔壓縮是每個表或者分割槽的選項。為了能夠簡單的擴充套件到磁碟,歸檔壓縮由流壓縮實現,透明的序列化和反序列化。使用LZ77壓縮演算法。
7 效能測試
7.1 Batch模式效能
SQL Server 2012 使用batch模式來處理從列儲存索引上過來的資料。有些操作可以減少40倍左右的cpu。效能測試使用TPC-DS資料庫。
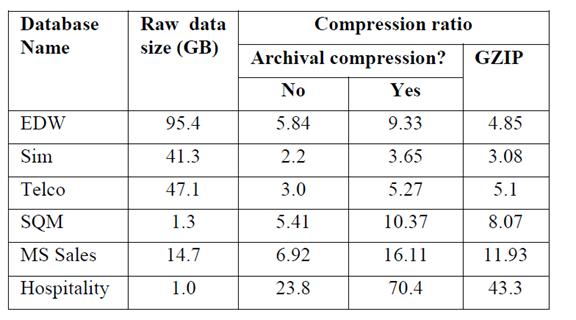
壓縮率
對一下SQL進行測試:
Q_count:
select count(*) from store_sales
Q_outer:
select item.i_brand_id brand_id, item.i_brand brand,
sum(ss_ext_sales_price) ext_price
from item left outer join store_sales
on (store_sales.ss_item_sk = item.i_item_sk)
where item.i_manufact_id = 128
group by item.i_brand_id, item.i_brand
order by ext_price desc, brand_id
Q_union_all:
select d.d_date_sk, count (*)
from (select ss_sold_date_sk as date_sk,
ss_quantity as quantity
from store_sales
union all
select ws_sold_date_sk as date_sk,
ws_quantity as quantity
from web_sales) t, date_dim d
where t.date_sk = d.d_date_sk
and d.d_weekend = 'Y'
group by d.d_date_sk;
Q_count_in:
-- Here, store_study_group contains a
-- set of 100 IDs of interesting stores.
select count(*) from store_sales where ss_store_sk in (select s_store_sk from store_study_group);
Q_not_in:
-- bad_ticket_numbers contains a
set of ticket numbers
-- with known data errors that we want to ignore.
select
ss_store_sk, d_moy, sum(ss_sales_price)
from store_sales, date_dim
where
ss_sold_date_sk = d_date_sk and d_year = 2002
and ss_ticket_number not in
(select * from bad_ticket_numbers)
group by ss_store_sk, d_moy

7.2 儲存需求
列儲存方式,store_sales表要13.2GB空間,大概46byte一樣。在Btree下聚集索引35.7GB,非聚集索引7.7GB,一共43.5GB大概151byte一行。
7.3 刪除效能
刪除效能通過以下語句來測試:
delete from Purchase where MediaId % 20 = 1;
在一個4核的裝置上,資料在磁碟彙總,delete語句在57s後完成,在相同的裝置上,使用btree,需要使用239s。delete在列儲存中比較快是因為,只要在dlete bitmap上插入row_group_id,row_number,而btree則要做實際的刪除動作,會生成很多log。若在列儲存上刪除>>10%建議重建列儲存索引。
7.4 批量和隨機插入
對於列儲存索引,bulk insert在16核設別上16個併發,可以達到600GB/h,如果做隨機插入,每次一行,在4核8個物理執行緒的設別上插入393W,需要花費22分16秒,每秒2944行。
參考:
相關推薦
SQL Server 列儲存索引強化
SQL Server 列儲存索引強化 1. 概述 之前SQL Server只有2個儲存組織方式,heaps和Btree,都是基於行的。SQL Server 2012之後加入了新的儲存方式
SQL Server 列儲存索引概述
第一次接觸ColumnStore是在2017年,資料庫環境是SQL Server 2012,Microsoft 第一次在SQL Server 2012中推廣列儲存索引,到現在的SQL Server 2017環境,列儲存索引發生了很大的變化。簡單來說,列儲存索引是資料倉庫中用於查詢和儲存大型事實表和維度表的標準
SQL Server 列儲存索引 第二篇:設計
列儲存索引可以是聚集的,也可以是非聚集的,使用者可以在表上建立聚集的列儲存索引(Clustered Columnstore Index)或非聚集的列儲存索引(Nonclustered Columnstore Index)。由於聚集索引實際上是表的物理儲存,因此,表上只能建立一個聚集索引,該聚集索引要
SQL Server 列儲存索引 第三篇:維護
列儲存索引分為兩種型別:聚集的列儲存索引和非聚集的列儲存索引,在一個表上只能建立一個聚集索引,要麼是聚集的列儲存索引,要麼是聚集的行儲存索引,然而一個表上可以建立多個非聚集索引。 一,建立列儲存索引 建立列儲存索引的語法如下: -- Create a clustered columnstore index
SQL Server 列儲存索引 第四篇:實時運營資料分析
實時運營資料分析(real-time operational analytics )是指同時在同一張資料表上執行分析處理和業務處理。分析查詢主要是對海量資料執行聚合查詢,而事務主要是指對資料表進行少量資料的更新和查詢。 運營工作負載(Operational workload)是指對開展業務至關重要的
SQL Server列儲存實現方案
SQL Server從2012版本開始支援列儲存,但2012版本使用列儲存會導致表進入只讀狀態;2014版本使用可更新聚集列儲存索引技術解決了只讀的問題,使用列儲存的表支援修改;2016版本列儲存支援操作分析,能夠對事務工作負載執行高效能實時分析。 列儲存索引是一種使用列式
使用Spark載入資料到SQL Server列儲存表
原文地址https://devblogs.microsoft.com/azure-sql/partitioning-on-spark-fast-loading-clustered-columnstore-index/ 介紹 SQL Server的Bulk load預設為序列,這意味著例如,一個BULK INS
SQL Server 深入解析索引儲存(非聚集索引)
概述 非聚集索引與聚集索引具有相同的 B 樹結構,它們之間的顯著差別在於以下兩點: 基礎表的資料行不按非聚集鍵的順序排序和儲存。 非聚集索引的葉層是由索引頁而不是由資料頁組成。
SQL Server 深入解析索引儲存(聚集索引)
標籤:SQL SERVER/MSSQL SERVER/資料庫/DBA/索引體系結構/堆/聚集索引 概述 最近要分享一個課件就重新把這塊知識整理了一遍出來,篇幅有點長,想要理解的透徹還是要上機實踐。 聚集索引 --建立測試資料庫 CREATE DATABASE Ixdata GO
SQL Server 深入解析索引儲存(堆)
標籤:SQL SERVER/MSSQL SERVER/資料庫/DBA/索引體系結構/堆 概述 本篇文章是關於堆的儲存結構。堆是不含聚集索引的表(所以只有非聚集索引的表也是堆)。堆的 sys.partitions 中具有一行,對於堆使用的每個分割槽,都有 index_id = 0。預設情況下,
SQL SERVER大話儲存結構(2)_非聚集索引如何查詢到行記錄
1 行記錄如何儲存 這裡引入兩個概念:堆跟聚集索引表。本部分參考MSDN。 1.1 堆表 堆表,沒有聚集索引的表格,可以建立一個或者多個非聚集索引。沒有按照某個規則進行儲存,一般來說,按照行記錄入表的順序,但是由於效能要求,可能會在不同區域移動入庫資料
SQL SERVER查看索引使用情況
use can png log table schema ats _id sca SELECT DISTINCT DB_NAME() AS N‘db_name‘ , E.name AS N‘schema_name‘ , O
SQL Server 非聚集索引的覆蓋,連接,交叉和過濾 <第二篇>
相對 col 超過 引用 保持 書簽 基本 nbsp 當我 在SQL Server中,非聚集索引其實可以看做是一個含有聚集索引的表,但相對實際的表來說,非聚集索引中所存儲的表的列數要少得多,一般就是索引列,聚集鍵(或RID)。非聚集索引僅僅包含源表中的非聚集索引的列和指
SQL Server 創建索引的 5 種方法
log htm bool 是我 大量 還在 serve src with 引自https://www.cnblogs.com/JiangLe/p/4007091.html 前期準備: create table Employee (
SQL SERVER全面優化-------索引有多重要?
link 發現 main hash join 不能 舉例 最優 double 無法 想了好久索引的重要性應該怎麽寫?講原理結構?我估計大部分人不願意看,也不願意花那麽多時間仔細研究。光寫應用?感覺不明白原理一樣不會用。舉例說明?情況太多也寫不全....到底該怎麽寫呢?
SQL Server 與儲存過程相關的資源網址
儲存過程相關文章 引用連線: 1、SQL server儲存過程建立與使用----http://blog.csdn.net/miniduhua/article/details/52102176 2、SQLSERVER儲存過程基本語法----http://www.cnb
資料庫——SQL Server的儲存過程
上一篇部落格總結了許多資料庫常用的SQL語句,今天我們就來看一下SQL的儲存過程。 簡單來說,儲存過程就是一條或者多條sql語句的集合,可視為批處理檔案,但是其作用不僅限於批處理。 本篇主要介紹變數的使用,儲存過程和儲存函式的建立,呼叫,檢視,修改以及刪除操作。上一篇部落格對這一部分內容也有
SQL Server 非聚集索引的覆蓋,連線,交叉和過濾 (第二篇)
在SQL Server中,非聚集索引其實可以看做是一個含有聚集索引的表,但相對實際的表來說,非聚集索引中所儲存的表的列數要少得多,一般就是索引列,聚集鍵(或RID)。非聚集索引僅僅包含源表中的非聚集索引的列和指向實際物理表的指標。 一、非聚集索引之INCLUDE 非聚集索引其實可以看做一
Sql Server在儲存過程裡面使用遊標遍歷一個表
這裡關於SqlServer有兩個知識點:一個是使用遊標遍歷表,另一個是使用if not exists的sql語句進行插入。 一、使用遊標遍歷表 這個表可以是資料庫的表,也可以是外面DataTable型別的引數傳進去,使用遊標可以概括為以下步驟:宣告遊標、開啟遊標、讀取
Java呼叫SQL Server的儲存過程詳解
本文較長,包含了如下幾部分 1使用不帶引數的儲存過程 使用 JDBC 驅動程式呼叫不帶引數的儲存過程時,必須使用 call SQL 轉義序列。不帶引數的 call 轉義序列的語法如下所示: {call procedure-name}