
Spark2.2,IDEA,Maven開發環境搭建附測試
阿新 • • 發佈:2018-12-14
前言:
停滯了一段時間,現在要沉下心來學習點東西,出點貨了。
本文沒有JavaJDK ScalaSDK和 IDEA的安裝過程,網路上會有很多文章介紹這個內容,因此這裡就不再贅述。
一、在IDEA上安裝Scala外掛
首先開啟IDEA,進入最初的視窗,選擇Configure -——>Plugins

然後會看到下面的視窗:
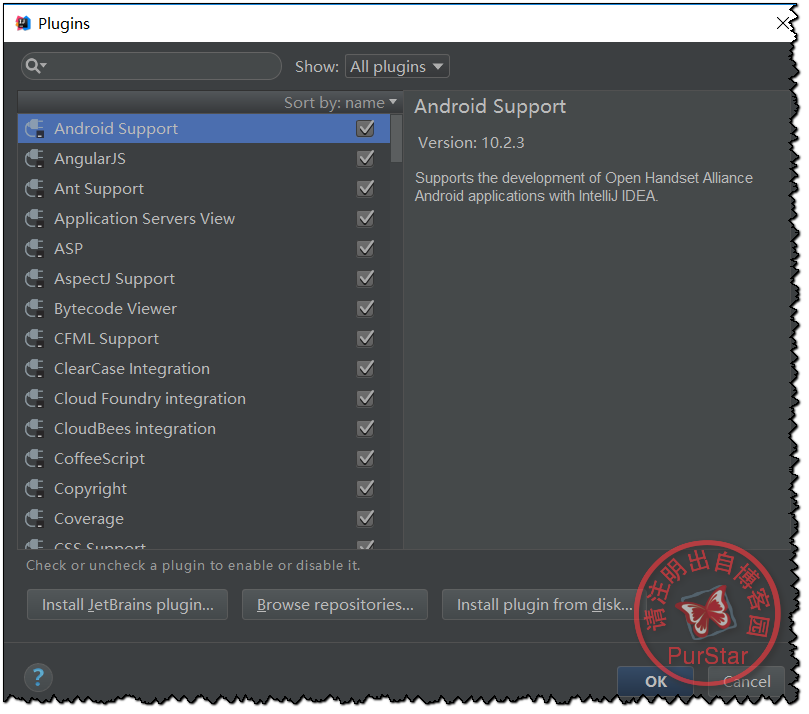
此時我們選擇‘Browse Repositories …’,然後輸入Scala,
找到下圖這一項,點選“install”即可
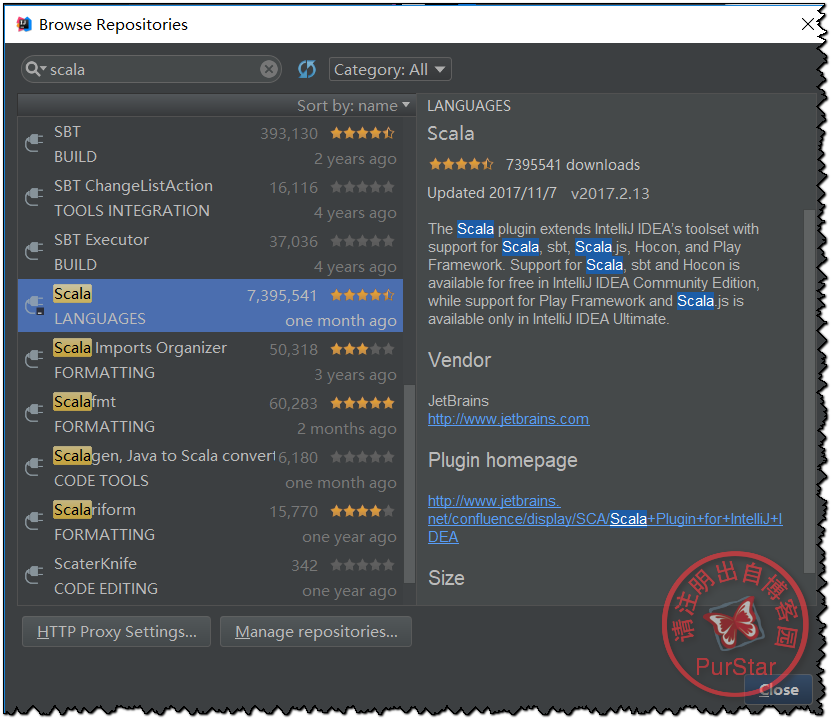
安裝完成後,請重啟IDEA。
二、建立一個Scala工程
依次點選Create New Project ——>Scala——>IDEA——>Next
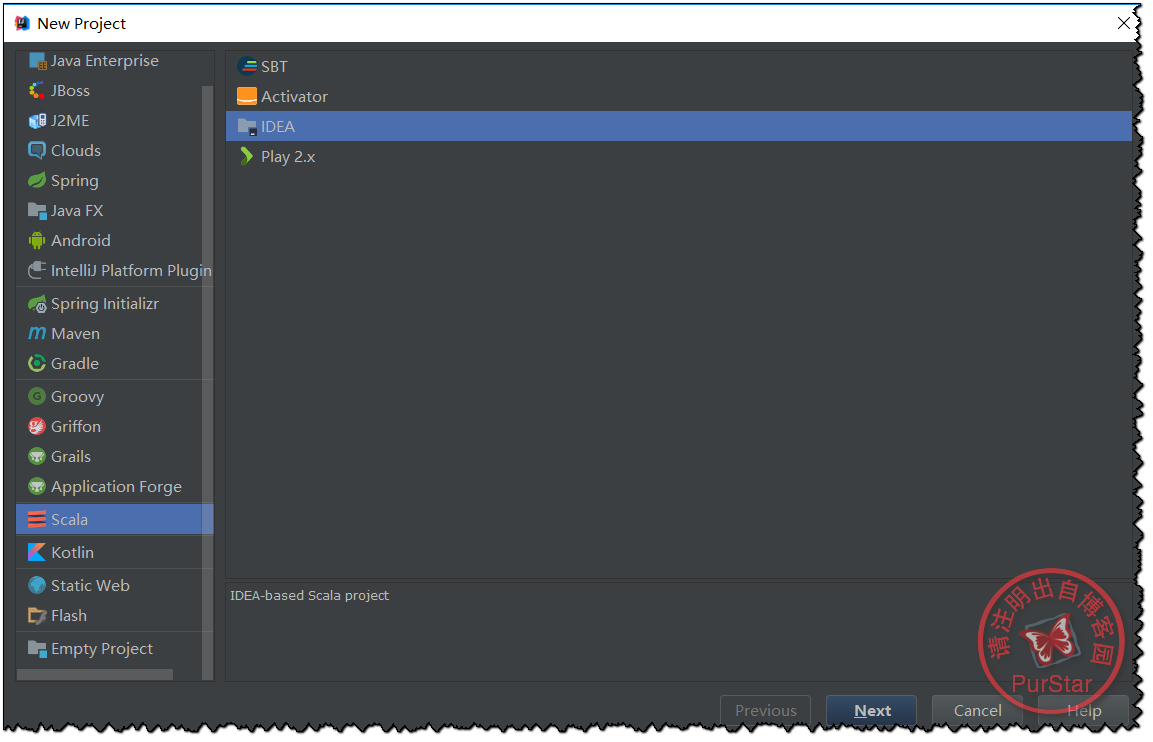
然後我們需要點選create,增加相應的SDK版本及位置。
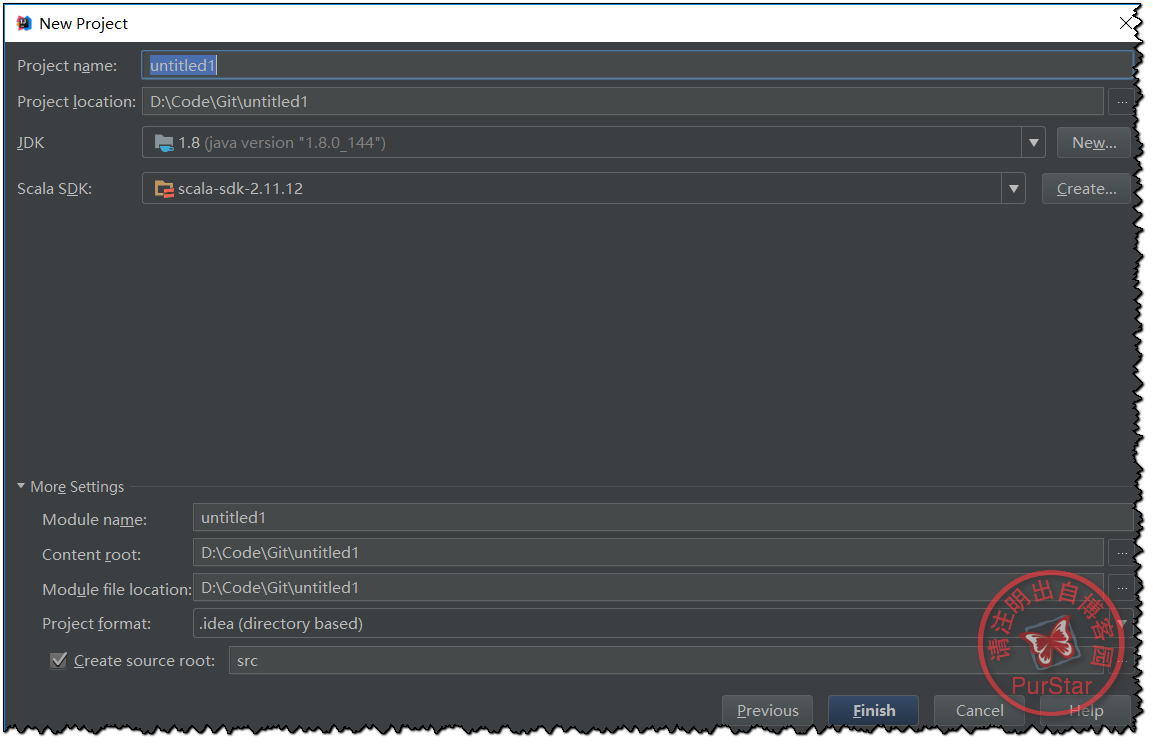
自己填寫好其他資訊後就可以,點選Finish了。
三、新增Maven框架以及編寫pom.xml
首先右鍵專案名然後選擇Add Framework Support...

然後找到maven打鉤,點選Ok即可.
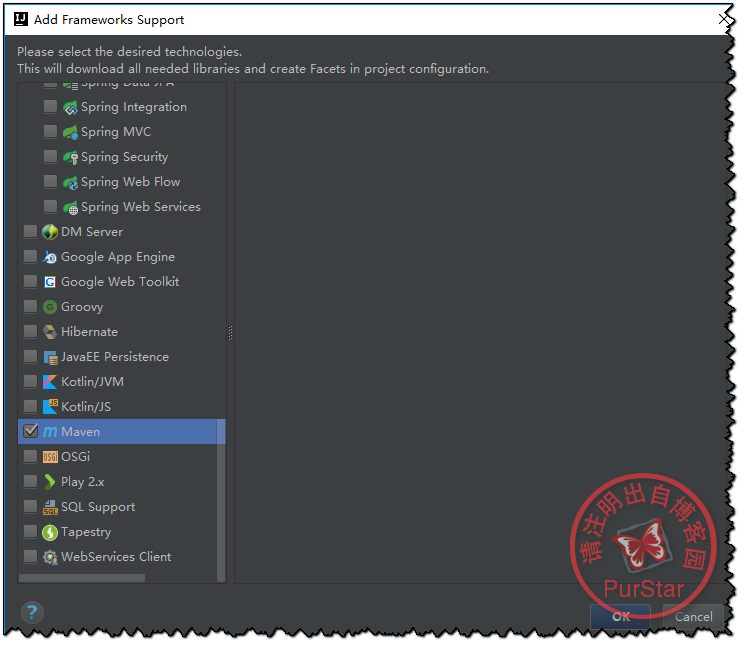
接下來,編寫Pom.xml,如下:

<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sudy</groupId>
<artifactId>SparkStudy</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.2.0</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>
四、新增winutils.exe檔案
winutils.exe下載地址:
解壓後,記住放入的路徑就好。
五、使用local模式測試環境是否搭建成功?
右鍵java資料夾,依次點選New——>Scala Class

然後選擇Object,輸入名稱即可。
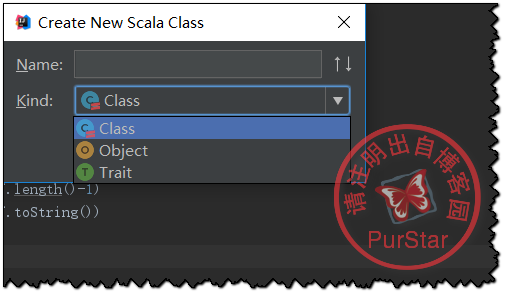
寫入測試程式碼:
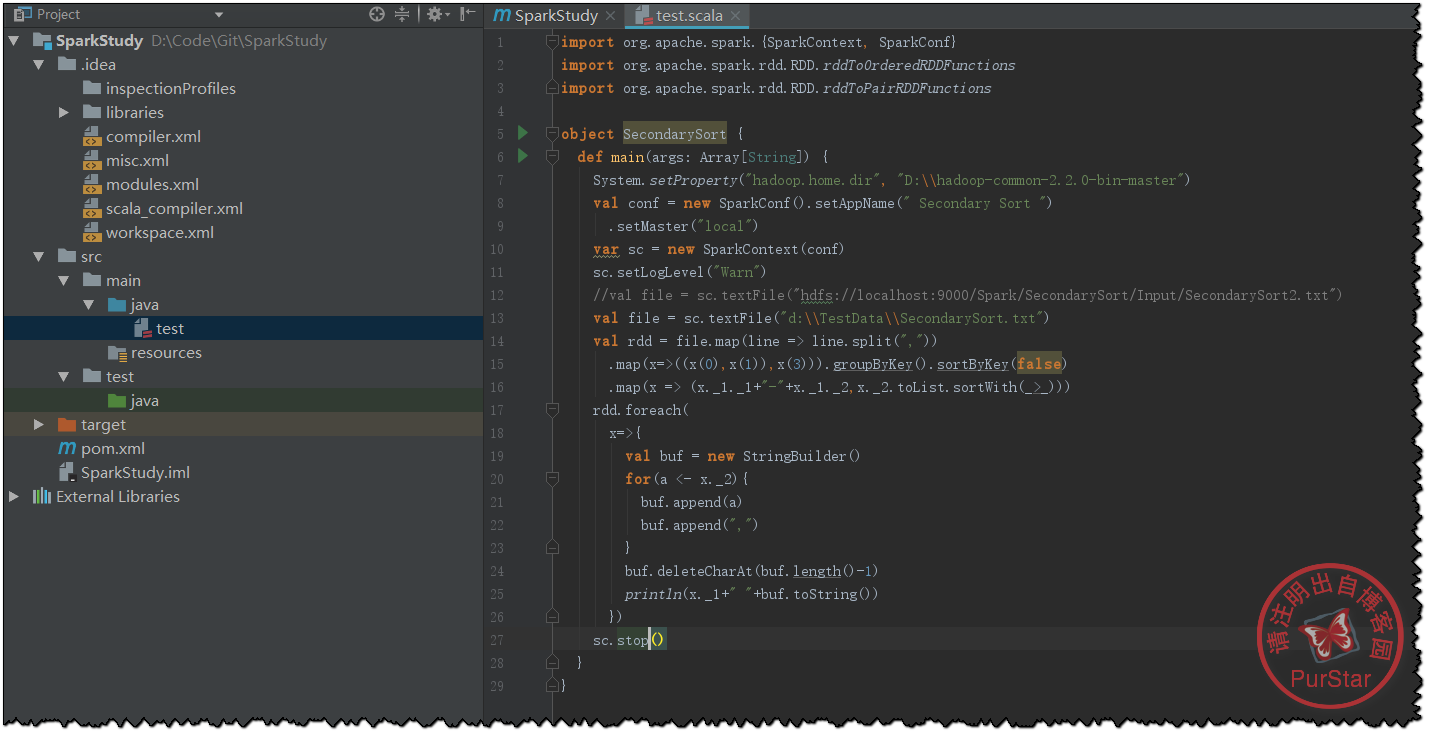
測試程式碼部分可以參照我之前寫的一篇部落格的後半部分:
為了大家方便這裡複製出程式碼和測試文字:
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.rdd.RDD.rddToOrderedRDDFunctions
import org.apache.spark.rdd.RDD.rddToPairRDDFunctions
object SecondarySort {
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master")
val conf = new SparkConf().setAppName(" Secondary Sort ")
.setMaster("local")
var sc = new SparkContext(conf)
sc.setLogLevel("Warn")
//val file = sc.textFile("hdfs://localhost:9000/Spark/SecondarySort/Input/SecondarySort2.txt")
val file = sc.textFile("d:\\TestData\\SecondarySort.txt")
val rdd = file.map(line => line.split(","))
.map(x=>((x(0),x(1)),x(3))).groupByKey().sortByKey(false)
.map(x => (x._1._1+"-"+x._1._2,x._2.toList.sortWith(_>_)))
rdd.foreach(
x=>{
val buf = new StringBuilder()
for(a <- x._2){
buf.append(a)
buf.append(",")
}
buf.deleteCharAt(buf.length()-1)
println(x._1+" "+buf.toString())
})
sc.stop()
}
}
測試文字如下:
2000,12,04,10 2000,11,01,20 2000,12,02,-20 2000,11,07,30 2000,11,24,-40 2012,12,21,30 2012,12,22,-20 2012,12,23,60 2012,12,24,70 2012,12,25,10 2013,01,23,90 2013,01,24,70 2013,01,20,-10
注意:
D:\\hadoop-common-2.2.0-bin-master 是我解壓後放入的路徑。
d:\\TestData\\SecondarySort.txt 是測試資料的位置,用於程式的執行。 好了,這篇文章結束了,剩下就是你的動手操作了。