
Spark Idea Maven 開發環境搭建
阿新 • • 發佈:2019-01-06
一、安裝jdk
jdk版本最好是1.7以上,設定好環境變數,安裝過程,略。
二、安裝Maven
我選擇的Maven版本是3.3.3,安裝過程,略。
編輯Maven安裝目錄conf/settings.xml檔案,
?| 1 2 |
<!-- 修改Maven 庫存放目錄-->
<localRepository>D:\maven-repository\repository</localRepository>
|
三、安裝Idea
安裝過程,略。
四、建立Spark專案
1、新建一個Spark專案,
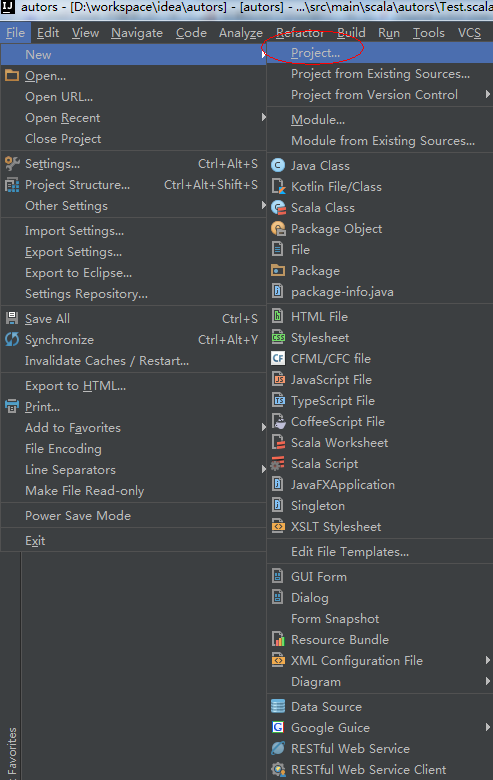
2、選擇Maven,從模板建立專案,

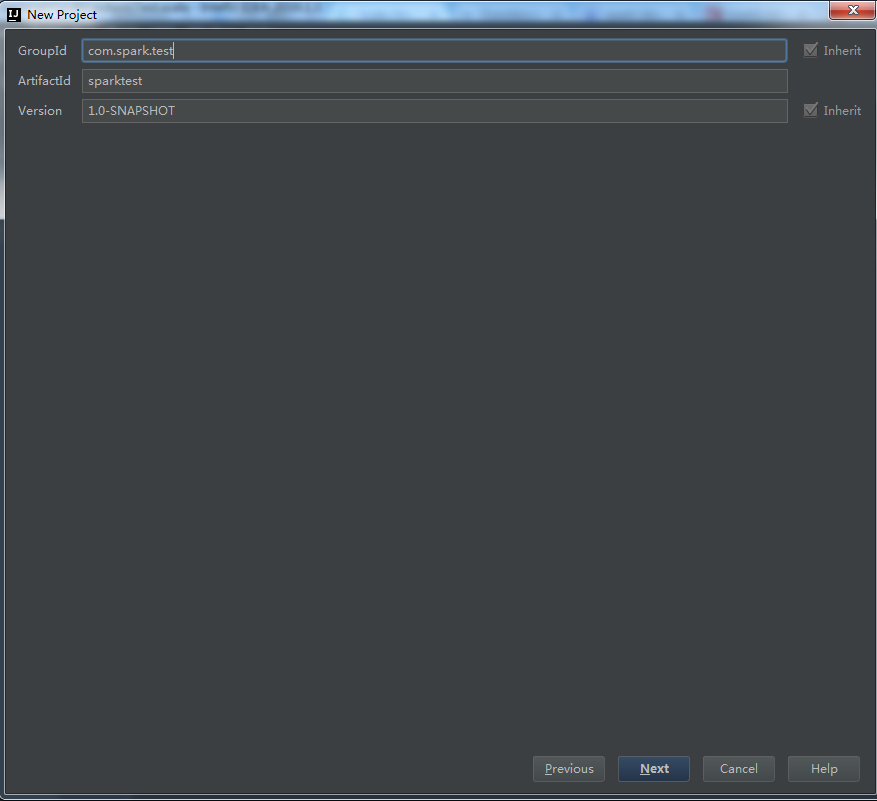
3、填寫專案GroupId等,
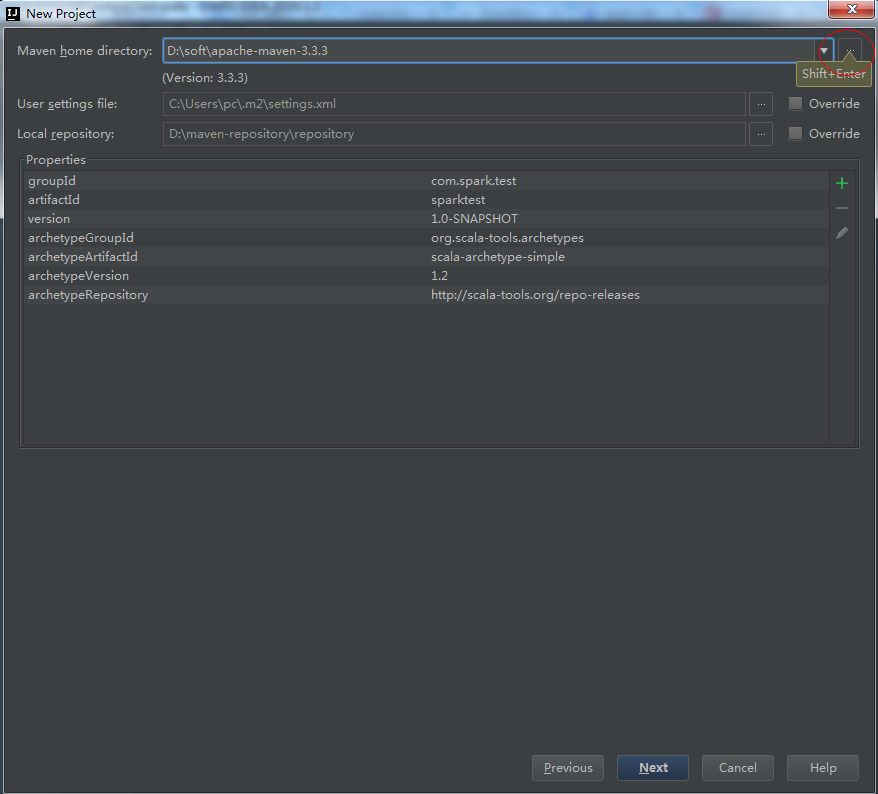
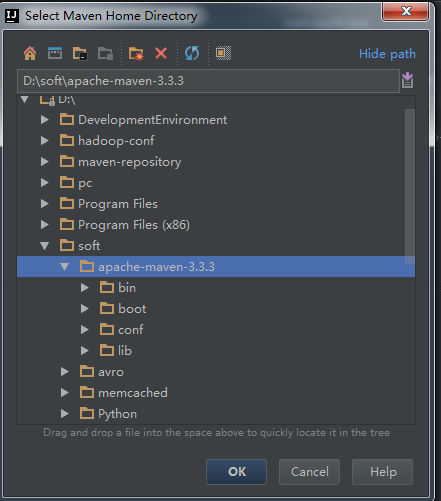
4、選擇本地安裝的Maven和Maven配置檔案。
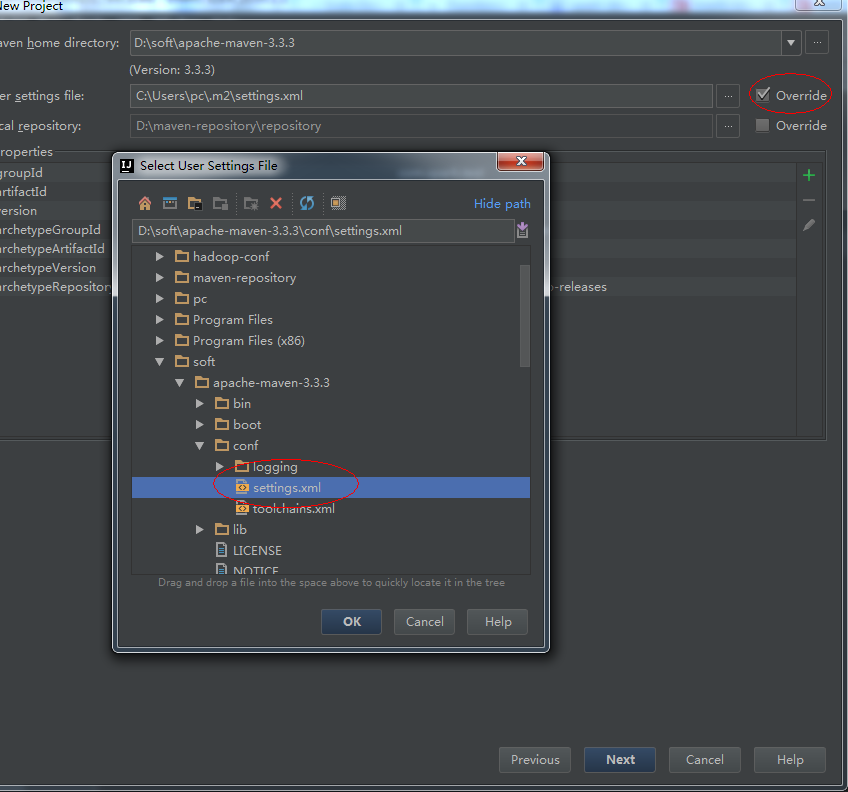
5、next
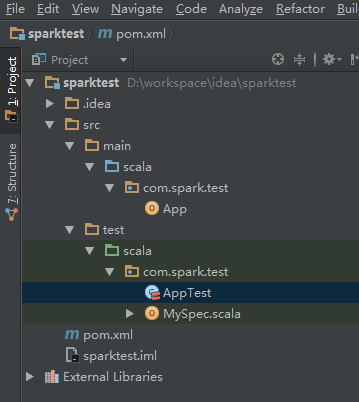
6、建立完畢,檢視新專案結構:
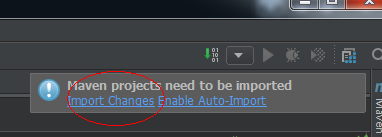
7、自動更新Maven pom檔案
8、編譯專案
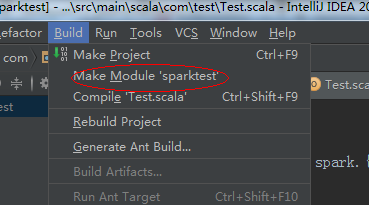
如果出現這種錯誤,這個錯誤是由於Junit版本造成的,可以刪掉Test,和pom.xml檔案中Junit的相關依賴,
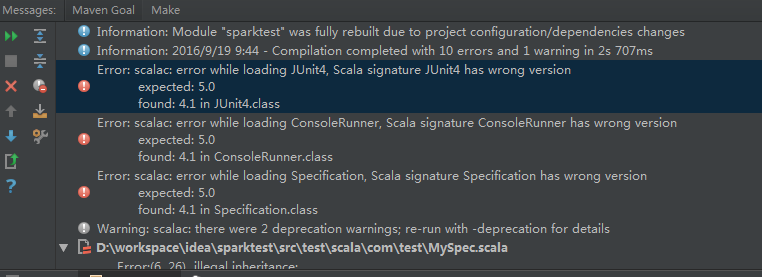
即刪掉這兩個Scala類:

和pom.xml檔案中的Junit依賴:
?| 1 2 3 4 5 |
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId><version>4.12</version>
</dependency>
|
9、重新整理Maven依賴

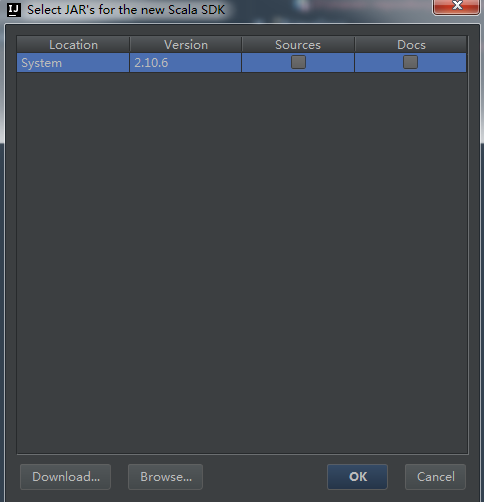
10、引入Jdk和Scala開發庫
11、在pom.xml加入相關的依賴包,包括Hadoop、Spark等
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
<dependency>
<groupId>commons-logging</groupId><artifactId>commons-logging</artifactId>
<version>1.1.1</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.1</version>
</dependency>
|
然後重新整理maven的依賴,
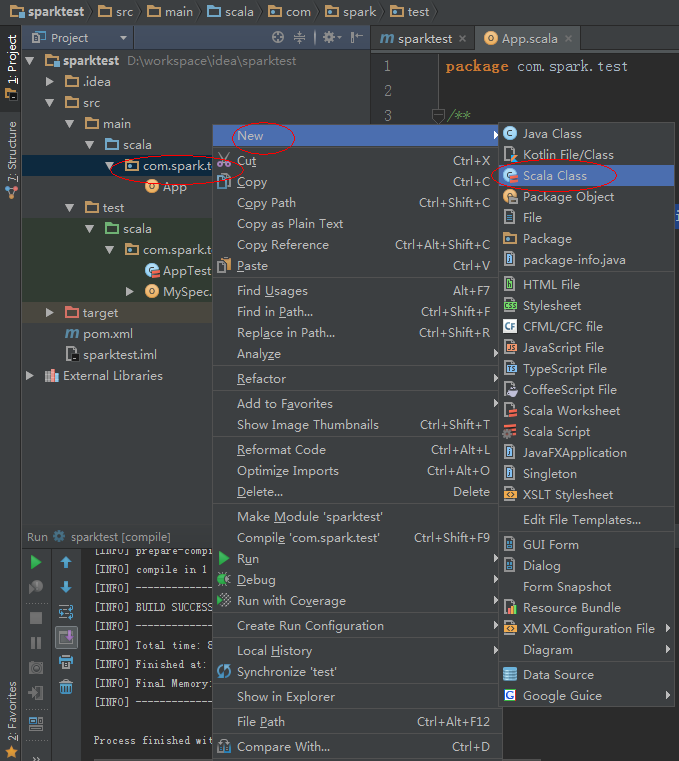
12、新建一個Scala Object。
測試程式碼為:
?| 1 2 3 4 5 |
def main(args: Array[String]) {
println("Hello World!")
val sparkConf =
new SparkConf().setMaster("local").setAppName("test")
val sparkContext =
new SparkContext(sparkConf)
}
|
執行,
如果報了以下錯誤,
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
java.lang.SecurityException:
class "javax.servlet.FilterRegistration"'s signer information does not match signer information of other classes in the same
package
at java.lang.ClassLoader.checkCerts(ClassLoader.java:952)
at java.lang.ClassLoader.preDefineClass(ClassLoader.java:666)
at java.lang.ClassLoader.defineClass(ClassLoader.java:794)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at org.spark-project.jetty.servlet.ServletContextHandler.<init>(ServletContextHandler.java:136)
at org.spark-project.jetty.servlet.ServletContextHandler.<init>(ServletContextHandler.java:129)
at org.spark-project.jetty.servlet.ServletContextHandler.<init>(ServletContextHandler.java:98)
at org.apache.spark.ui.JettyUtils$.createServletHandler(JettyUtils.scala:110)
at org.apache.spark.ui.JettyUtils$.createServletHandler(JettyUtils.scala:101)
at org.apache.spark.ui.WebUI.attachPage(WebUI.scala:78)
at org.apache.spark.ui.WebUI$$anonfun$attachTab$1.apply(WebUI.scala:62)
at org.apache.spark.ui.WebUI$$anonfun$attachTab$1.apply(WebUI.scala:62)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.ui.WebUI.attachTab(WebUI.scala:62)
at org.apache.spark.ui.SparkUI.initialize(SparkUI.scala:61)
at org.apache.spark.ui.SparkUI.<init>(SparkUI.scala:74)
at org.apache.spark.ui.SparkUI$.create(SparkUI.scala:190)
at org.apache.spark.ui.SparkUI$.createLiveUI(SparkUI.scala:141)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:466)
at com.test.Test$.main(Test.scala:13)
at com.test.Test.main(Test.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
|
可以把servlet-api 2.5 jar刪除即可:
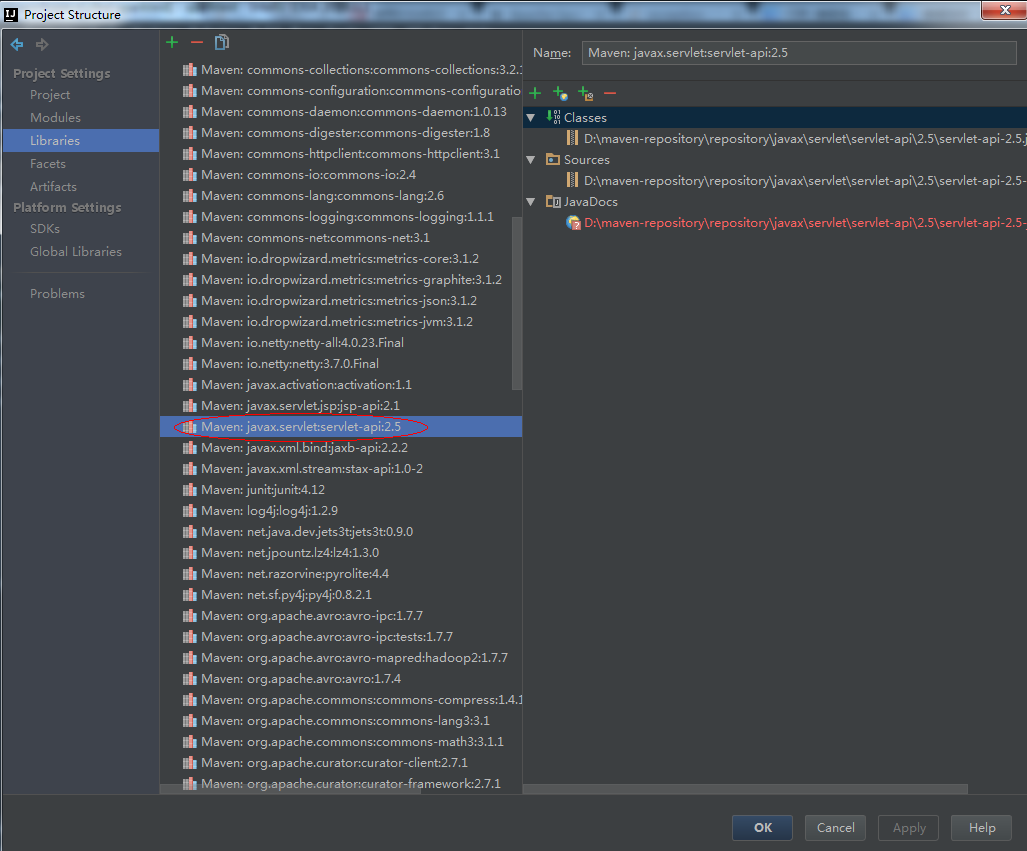
最好的辦法是刪除pom.xml中相關的依賴,即
?| 1 2 3 4 5 |
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
|
最後的pom.xml檔案的依賴是
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>com.databricks</groupId>
<artifactId>spark-avro_2.10</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.5.2</version>
</dependency>
</dependencies>
|
如果是報了這個錯誤,也沒有什麼問題,程式依舊可以執行,
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
java.io.IOException: Could not locate executable
null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:364)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:272)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:790)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:760)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:633)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2084)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:311)
at com.test.Test$.main(Test.scala:13)
at com.test.Test.main(Test.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
|
最後看到的正常輸出:
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
Hello World!
Using Spark's
default log4j profile: org/apache/spark/log4j-defaults.properties
16/09/19
11:21:29
INFO SparkContext: Running Spark version 1.5.1
16/09/19
11:21:29
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable
null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:364)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:272)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:790)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:760)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:633)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2084)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:311)
at com.test.Test$.main(Test.scala:13)
at com.test.Test.main(Test.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
16/09/19
11:21:29
WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
16/09/19
11:21:30
INFO SecurityManager: Changing view acls to: pc
16/09/19
11:21:30
INFO SecurityManager: Changing modify acls to: pc
16/09/19
11:21:30
INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(pc); users with modify permissions: Set(pc)
16/09/19
11:21:30
INFO Slf4jLogger: Slf4jLogger started
16/09/19
11:21:31
INFO Remoting: Starting remoting
16/09/19
11:21:31
INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:52500]
16/09/19
11:21:31
INFO Utils: Successfully started service 'sparkDriver'
on port 52500.
16/09/19
11:21:31
INFO SparkEnv: Registering MapOutputTracker
16/09/19
11:21:31
INFO SparkEnv: Registering BlockManagerMaster
16/09/19
11:21:31
INFO DiskBlockManager: Created local directory at C:\Users\pc\AppData\Local\Temp\blockmgr-f9ea7f8c-68f9-4f9b-a31e-b87ec2e702a4
16/09/19
11:21:31
INFO MemoryStore: MemoryStore started with capacity
966.9 MB
16/09/19
11:21:31
INFO HttpFileServer: HTTP File server directory is C:\Users\pc\AppData\Local\Temp\spark-64cccfb4-46c8-4266-92c1-14cfc6aa2cb3\httpd-5993f955-0d92-4233-b366-c9a94f7122bc
16/09/19
11:21:31
INFO HttpServer: Starting HTTP Server
16/09/19
11:21:31
INFO Utils: Successfully started service 'HTTP file server'
on port 52501.
16/09/19
11:21:31
INFO SparkEnv: Registering OutputCommitCoordinator
16/09/19
11:21:31
INFO Utils: Successfully started service 'SparkUI'
on port 4040.
16/09/19
11:21:31
INFO SparkUI: Started SparkUI at http://192.168.51.143:4040
16/09/19
11:21:31
WARN MetricsSystem: Using default
|