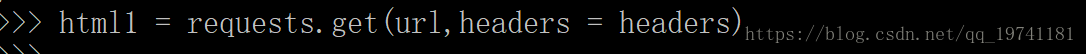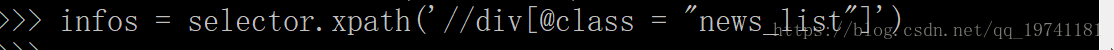Python-爬取小說文字內容(使用beautiful soup實現)
Python-爬取小說文字內容(beautiful soup)
本次爬取的網站為[http://www.136book.com/][6],你可以在頁面選擇你想要爬取的小說。 文中程式碼使用Anaconda的Jupyter書寫。
Beautiful Soup簡介
官方解釋: Beautiful Soup提供一些簡單的、python式的函式用來處理導航、搜尋、修改分析樹等功能。它是一個工具箱,通過解析文件為使用者提供需要抓取的資料,因為簡單,所以不需要多少程式碼就可以寫出一個完整的應用程式。 Beautiful Soup自動將輸入文件轉換為Unicode編碼,輸出文件轉換為utf-8編碼。你不需要考慮編碼方式,除非文件沒有指定一個編碼方式,這時,Beautiful Soup就不能自動識別編碼方式了。然後,你僅僅需要說明一下原始編碼方式就可以了。 Beautiful Soup已成為和lxml、html6lib一樣出色的python直譯器,為使用者靈活地提供不同的解析策略或強勁的速度。 ——
[ beautiful soup ]
此次實戰從網上爬取小說,需要使用到Beautiful Soup。 Beautiful Soup為python的第三方庫,可以幫助我們從網頁抓取資料。 它主要有如下特點:
1.Beautiful Soup可以從一個HTML或者XML提取資料,它包含了簡單的處理、遍歷、搜尋文件樹、修改網頁元素等功能。可以通過很簡短地程式碼完成我們地爬蟲程式。 2.Beautiful Soup幾乎不用考慮編碼問題。一般情況下,它可以將輸入文件轉換為unicode編碼,並且以utf-8編碼方式輸出。
對於本次爬蟲任務,只要瞭解以下幾點基礎內容就可以完成: 1.Beautiful Soup的物件種類: Tag Navigablestring BeautifulSoup Comment 2.遍歷文件樹:find、find_all、find_next和children 3.一點點HTML和CSS知識(沒有也將就,現學就可以)
Beautiful Soup安裝
在Anaconda Prompt中輸入:
pip install beautifulsoup4安裝beautiful soup。
使用python程式碼爬取
1.爬取思路分析
開啟目錄頁,可以看到章節目錄,想要爬取小說的內容,就要找到每個目錄對應的url,並且爬取其中的正文內容,然後將正文內容取出來,放在本地檔案中。這裡選取《羋月傳》作為示例。http://www.136book.com/mieyuechuanheji/
按F12檢視網頁的審查元素選單,選擇左上角[箭頭]的標誌,在目錄中選擇想要爬取的章節標題,如圖:選擇了【第六章 少司命(3)】,可以看到網頁的原始碼中,加深顯示了本章的連結。
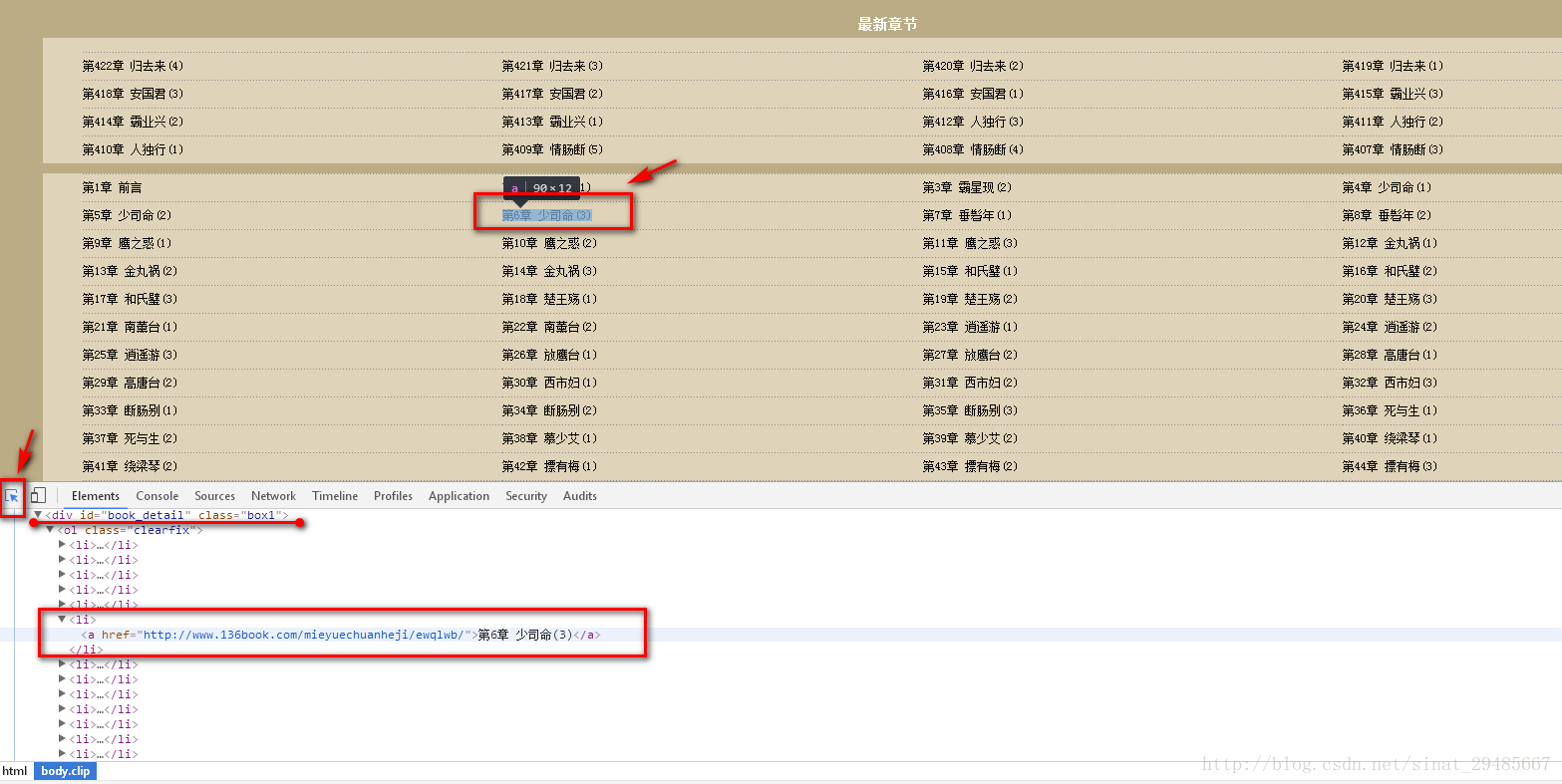
這樣我們可以看到,每一章的連結地址都是有規則地存放在<li>中。而這些<li>又放在<div id=”book_detail” class=”box1″>中。
2.單章節爬蟲
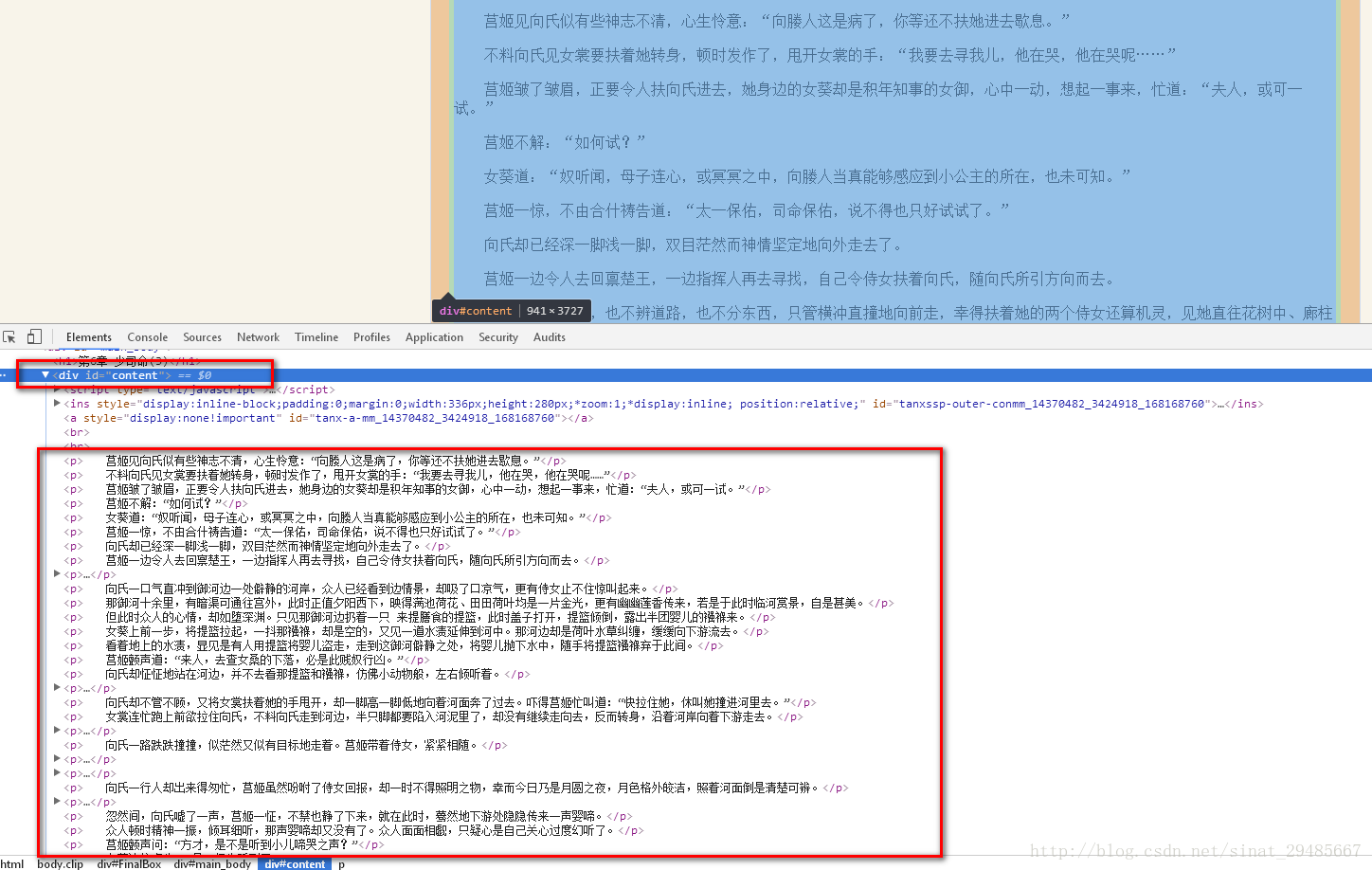
剛才已經分析過網頁結構。我們可以直接在瀏覽器中開啟對應章節的連結地址,然後將文字內容提取出來。我們要爬取的內容全都包含在這個<div>裡面。
# 爬取單章節的文字內容
from urllib import request
from bs4 import BeautifulSoup
if __name__ == '__main__':
# 第6章的網址
url = 'http://www.136book.com/mieyuechuanheji/ewqlwb/'
head = {}
# 使用代理
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
# 建立request物件
soup = BeautifulSoup(html, 'lxml')
# 找出div中的內容
soup_text = soup.find('div', id = 'content')
# 輸出其中的文字
print(soup_text.text)輸出的結果為:

3.小說全集爬蟲
思路是先在目錄頁中爬取所有章節的連結地址,然後再爬取每個連結對應的網頁中的文字內容。說來,就是比單章節爬蟲多一次解析過程,需要用到Beautiful Soup遍歷文件樹的內容。
1).解析目錄頁面
在思路分析中,我們已經瞭解了目錄頁的結構。所有的內容都放在一個所有的內容都放在一個<div id=”book_detail” class=”box1″>中。
程式碼整理如下:
# 爬取目錄頁面-章節對應的網址
from urllib import request
from bs4 import BeautifulSoup
if __name__ == '__main__':
# 目錄頁
url = 'http://www.136book.com/mieyuechuanheji/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
# 解析目錄頁
soup = BeautifulSoup(html, 'lxml')
# find_next找到第二個<div>
soup_texts = soup.find('div', id = 'book_detail', class_= 'box1').find_next('div')
# 遍歷ol的子節點,打印出章節標題和對應的連結地址
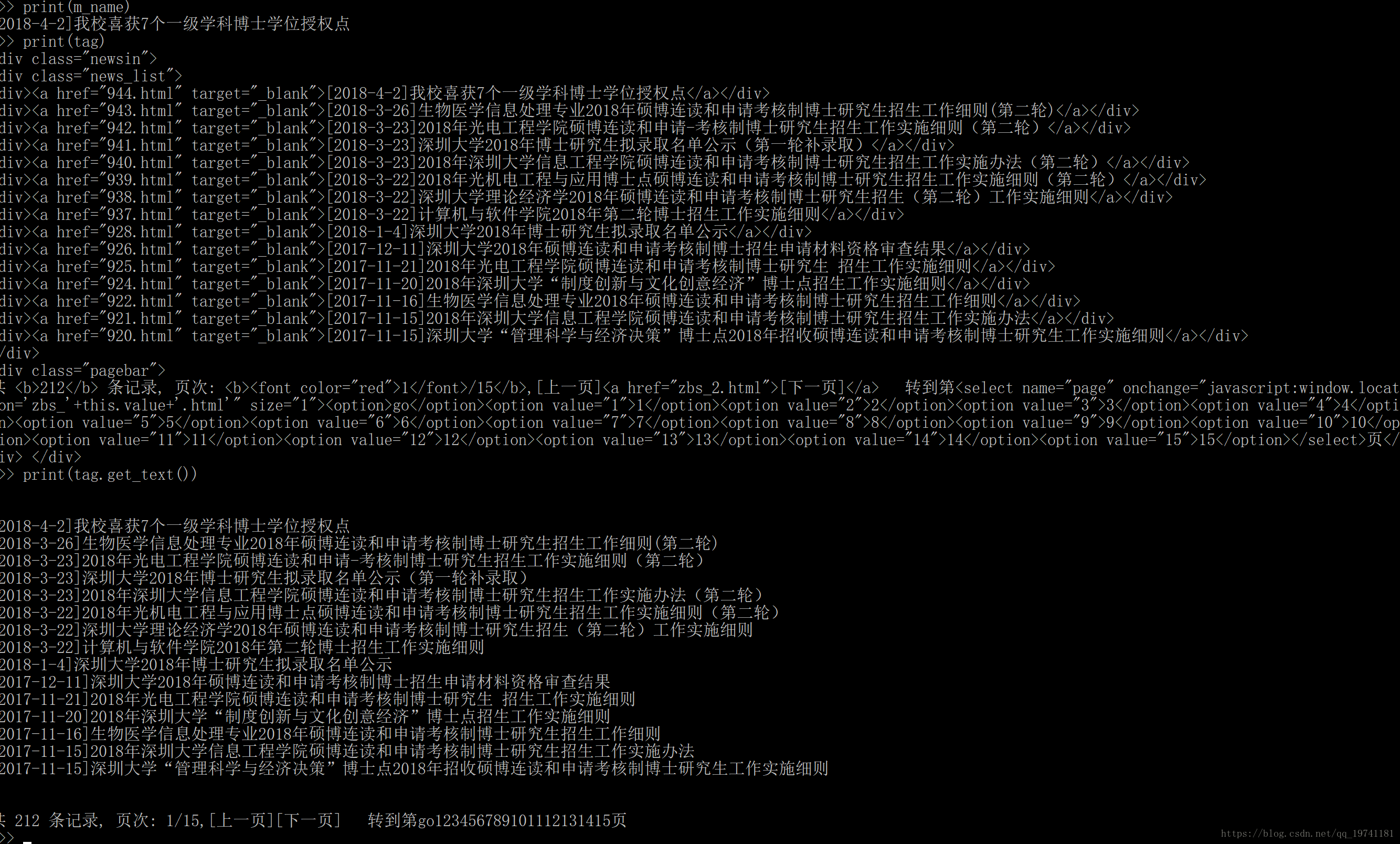
for link in soup_texts.ol.children:
if link != '\n':
print(link.text + ': ', link.a.get('href'))輸出結果為:

2).爬取全集內容
將每個解析出來的連結迴圈代入到url中解析出來,並將其中的文字爬取出來,並且寫到本地E:/miyuezhuan.txt中。(存放位置可以根據自己的本地情況自定義)
程式碼整理如下:
# 爬取全集內容
from urllib import request
from bs4 import BeautifulSoup
if __name__ == '__main__':
url = 'http://www.136book.com/mieyuechuanheji/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
soup = BeautifulSoup(html, 'lxml')
soup_texts = soup.find('div', id = 'book_detail', class_= 'box1').find_next('div')
# 開啟檔案
f = open('E:/miyuezhuan.txt','w')
# 迴圈解析連結地址
for link in soup_texts.ol.children:
if link != '\n':
download_url = link.a.get('href')
download_req = request.Request(download_url, headers = head)
download_response = request.urlopen(download_req)
download_html = download_response.read()
download_soup = BeautifulSoup(download_html, 'lxml')
download_soup_texts = download_soup.find('div', id = 'content')
# 抓取其中文字
download_soup_texts = download_soup_texts.text
# 寫入章節標題
f.write(link.text + '\n\n')
# 寫入章節內容
f.write(download_soup_texts)
f.write('\n\n')
f.close()可以開啟存放位置的檔案:E:/miyuezhuan.txt 檢視爬取結果。
第一步:
匯入模組
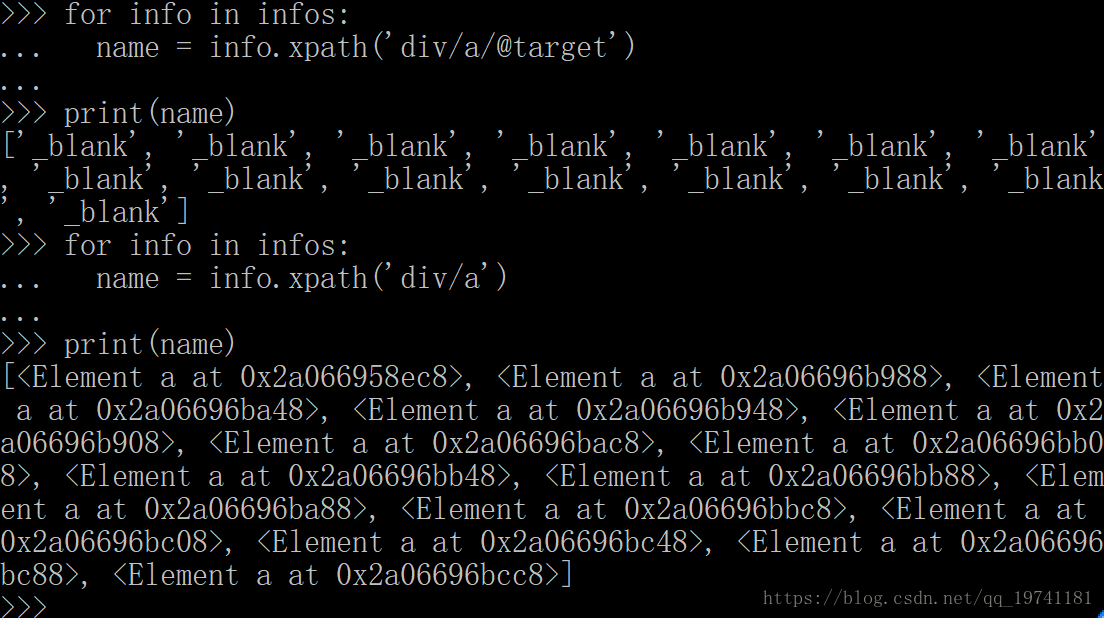
- >>> import re
- >>> from bs4 import BeautifulSoup
- >>> import urllib.request
-------------------------------------
第二步:
匯入網址
url = "http://zsb.szu.edu.cn/zbs.html"
-------------------------------------------------------------------------

第三步:
調動模組解析網址
>>> page = urllib.request.urlopen(url) #通過連結獲取整個網頁
>>> soup = BeautifulSoup(page,'lxml') #格式化排列
print(soup.prettify()) #打印出結構化的資料
第四步:

--------------------------------------------------------

-----------------------------------------------------------
下一步寫,模擬瀏覽器的規格
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
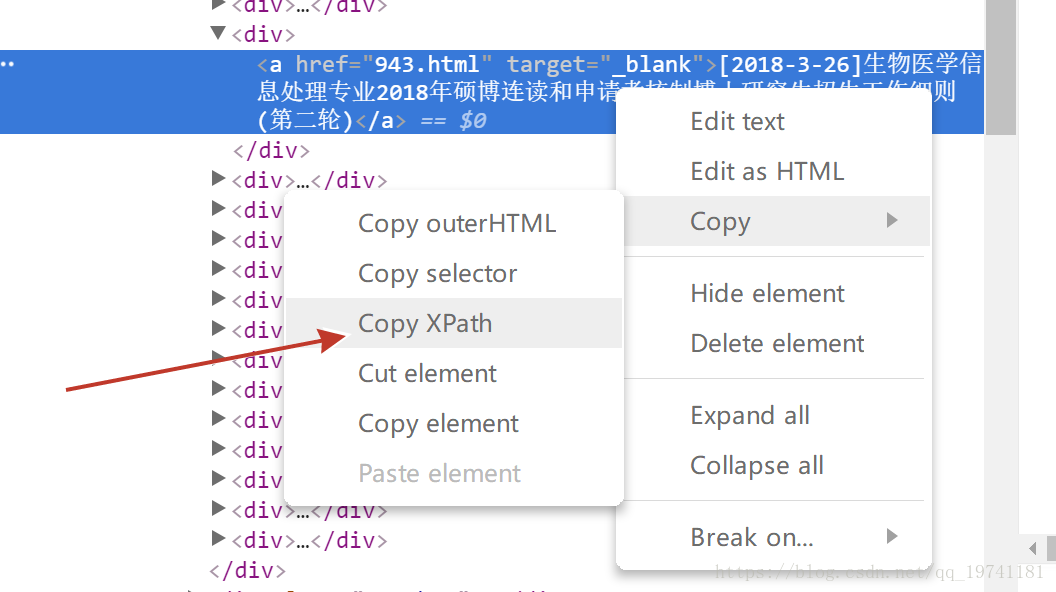
下一步,複製Xpath路徑
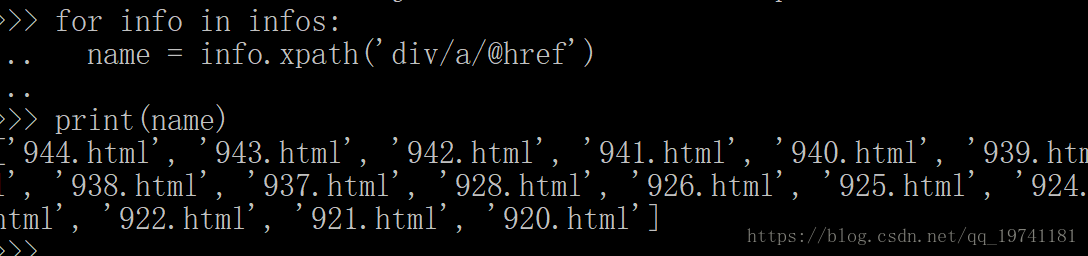
/html/body/div[5]/table/tbody/tr/td[2]/div[3]/div[1]/div[2]/a

-----------------------------------------------------------