
LSTM入門學習——本質上就是比RNN的隱藏層公式稍微複雜了一點點而已
LSTM入門學習
摘自:http://blog.csdn.net/hjimce/article/details/51234311
下面先給出LSTM的網路結構圖:
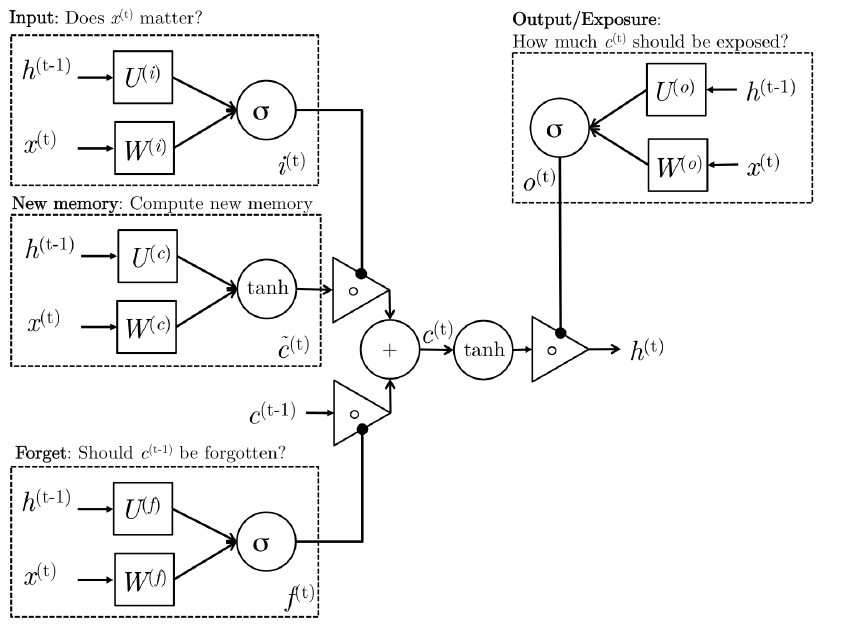
看到網路結構圖好像很複雜的樣子,其實不然,LSTM的網路結構圖無非是為了顯示其高大上而已,這其實也是一個稍微比RNN難那麼一丁點的演算法。為了簡單起見,下面我將直接先採用公式進行講解LSTM,省得看見LSTM網路結構圖就頭暈。
(1)RNN回顧
先簡單回顧一下RNN隱層神經元計算公式為:
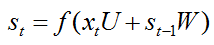
其中U、W是網路模型的引數,f(.)表示啟用函式。RNN隱層神經元的計算由t時刻輸入xt,t-1時刻隱層神經元啟用值st-1作為輸入。總之說白了RNN的核心計算公式就只有上面這麼簡簡單單的公式,所以說會者不難,難者不會,對於已經懂得RNN的人來說,RNN是一個非常簡單的網路模型。
(2)LSTM前向傳導
相比於RNN來說,LSTM隱層神經元的計算公式稍微複雜一點,LSTM隱藏層前向傳導由下面六個計算公式組成,而且其中前4個公式跟上面RNN公式都非常相似:
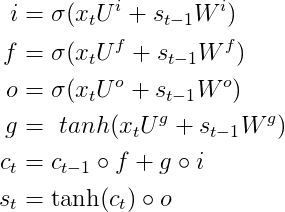
首先需要先記住上面五個公式中輸入變數的含義:
(1)輸入變數:x(t)表示t時刻網路的輸入資料,S(t-1)表示t-1時刻隱藏層神經元的啟用值、C是一個記憶單元
(2)網路引數:U、W都是網路LSTM模型的引數,或者稱之為權值矩陣
(3)σ表示sigmoid啟用函式
(4)另外s(t)是t時刻,LSTM隱藏層的啟用值
從上面的公式我們可以看出LSTM在t時刻的輸入包含:X(t)、S(t-1)、C(t-1),輸出就是t時刻隱層神經元啟用值S(t)。LSTM前四個公式和RNN非常相似,模型都是:
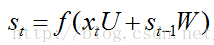
這四個公式的輸入都是x(t),s(t-1),每個公式各有各自的引數U、W。前面三個公式的啟用函式選擇s型函式,大牛門給它們起了一個非常裝逼的名詞,i、f、o分別稱之為輸入門、遺忘門、輸出門;第4個公式選用tanh啟用函式。
1、輸入門
輸入門可以控制你的輸入是否影響你的記憶當中的內容。因變數為i,自變數為:輸入資料x(t)、上一時刻隱藏層神經元啟用值s(t-1),其採用S啟用函式,輸出的數值在0~1之間。如果從業餘的角度來講,可以把它看成是一個權值;當i為0的時候,表示當前時刻x(t)的資訊被遮蔽,沒有儲存到記憶中。
2、遺忘門
遺忘門是來看你的記憶是否自我更新保持下去。因變數為f,自變數依舊為:
3、輸出門
輸出門是影響你的記憶是否被輸出出來影響將來這三個們有一個特點:它們的輸入資料都是x(t),上一時刻隱藏層的啟用值s(t-1),另外這三個們
這種方式使你的記憶得到靈活的保持,而控制記憶如何保持的這些門本身是通過學習得到的,通過不同的任務學習如何去控制這些門。
三、原始碼實現
-
- x_i = K.dot(x * B_W[0], self.W_i) + self.b_i
- x_f = K.dot(x * B_W[1], self.W_f) + self.b_f
- x_c = K.dot(x * B_W[2], self.W_c) + self.b_c
- x_o = K.dot(x * B_W[3], self.W_o) + self.b_o
- i = self.inner_activation(x_i + K.dot(h_tm1 * B_U[0], self.U_i))
- f = self.inner_activation(x_f + K.dot(h_tm1 * B_U[1], self.U_f))
- c = f * c_tm1 + i * self.activation(x_c + K.dot(h_tm1 * B_U[2], self.U_c))
- o = self.inner_activation(x_o + K.dot(h_tm1 * B_U[3], self.U_o))
- h = o * self.activation(c)