
MySQL排序函式field()詳解
在日常開發過程中,排序是經常用到的,有時候有這樣的需求。
比如,需要在查詢結果中根據某個欄位的具體值來排序。如下面例子
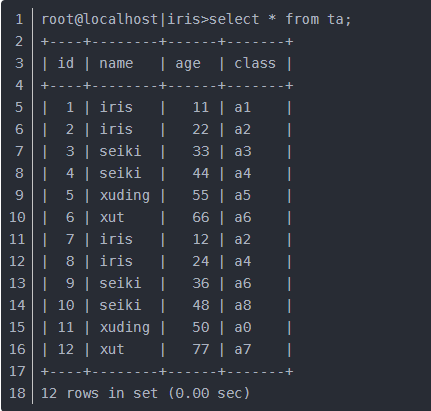
上面是一張個人資訊 表,假如我們想按照'seiki','iris','xut'來排序。也就是name='seiki','iris','xut'的來排序。
碰到這樣的需求,我們應該怎麼做呢,其實有一個MySQL函式可以非常方便的處理此需求
那就是field()函式
使用方式如下

其中,order by (str,str1,str2,str3,str4……),str與str1,str2,str3,str4比較,其中str指的是欄位名字,
意為:欄位str按照字串str1,str2,str3,str4的順序返回查詢到的結果集。如果表中str欄位值不存在於str1,str2,str3,str4中的記錄,放在結果集最前面返回。
現在使用方法知道了,那我們就來實現上面的需求
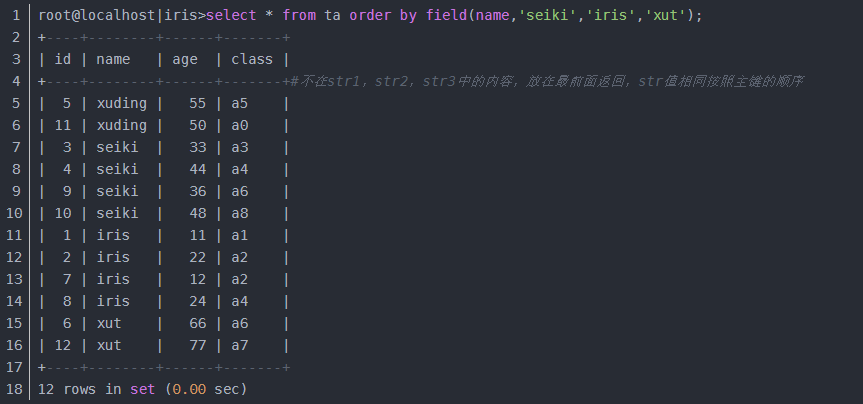
首先來個正序排序
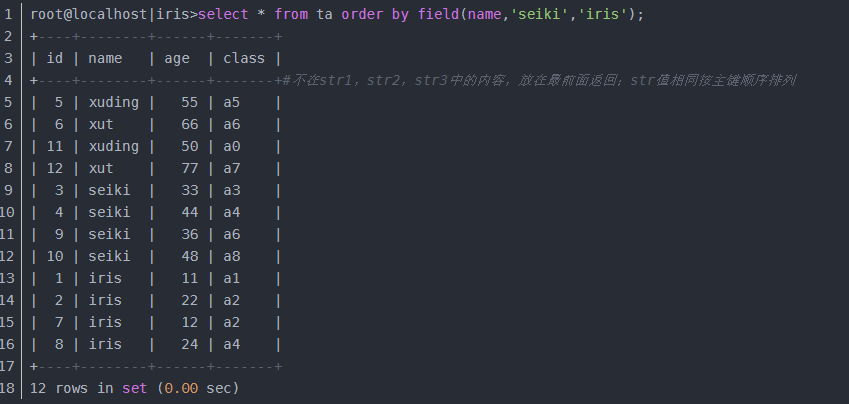
或者按照'seiki','iris'來排序,結果如下
現在讓我們來倒序排序‘seiki','iris'
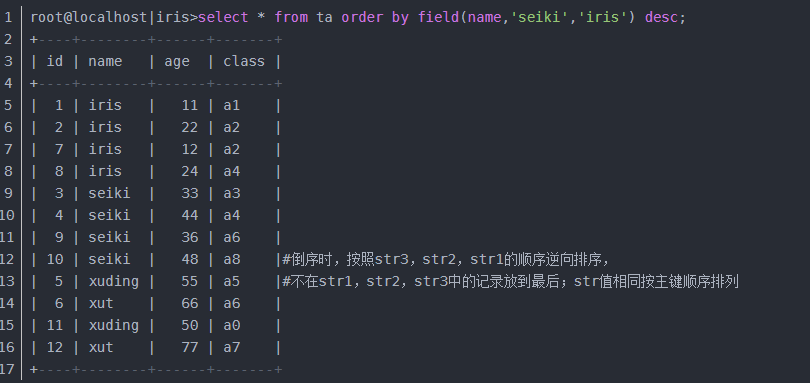
可以看到iris是在最前面,這是為何呢,看上面圖上的註釋!
好了,這函式還是非常好用 的
相關推薦
MySQL排序函式field()詳解
在日常開發過程中,排序是經常用到的,有時候有這樣的需求。 比如,需要在查詢結果中根據某個欄位的具體值來排序。如下面例子 上面是一張個人資訊 表,假如我們想按照'seiki','iris','xut'來排序。也就是name='seiki','iris','xut'的來排序。 碰到這樣的需求,我們應該怎麼做呢,
ROW_NUMBER() OVER()函式用法詳解 (分組排序 例子多)
語法格式:row_number() over(partition by 分組列 order by 排序列 desc) row_number() over()分組排序功能: 在使用 row_number() over()函式時候,over()裡頭的分組以及排序的執行晚於 wher
MySQL自定義函式用法詳解-複合結構自定義變數/流程控制
自定義函式 (user-defined function UDF)就是用一個象ABS() 或 CONCAT()這樣的固有(內建)函式一樣作用的新函式去擴充套件MySQL。 所以UDF是對MySQL功能的一個擴充套件 建立和刪除自定義函式語法: 建立UDF: CREATE
mysql中date_add與date_sub函式使用詳解
mysql中date_add與date_sub函式使用詳解 轉載:http://www.111cn.net/database/mysql/52936.htm 在mysql中date_a
MySQL中的儲存過程和函式使用詳解
一.對待儲存過程和函式的態度 在實際專案中應該儘量少用儲存過程和函式,理由如下: 1.移植性差,在MySQL中的儲存過程移植到sqlsever上就不一定可以用了。 2.除錯麻煩,在db中報一個錯誤和在應用層報一個錯誤不是一個概念,那將是毀滅性打擊,直接一個error:1045什麼的更本毫無頭緒。 3.擴充套件
MySQL自定義排序函式FIELD()
MySQL可以通過field()函式自定義排序,格式:field(value,str1,str2,str3,str4),value與str1、str2、str3、str4比較,返回1、2、3、4,如遇到null或者不在列表中的資料則返回0. 這個函式好像Oracle中沒有專
MySQL自定義函式用法詳解
自定義函式 (user-defined function UDF)就是用一個象ABS() 或 CONCAT()這樣的固有(內建)函式一樣作用的新函式去擴充套件MySQL。 所以UDF是對MySQL功能的一個擴充套件 建立和刪除自定義函式語法: 建立UDF: CREATE [AGGREGATE] FUN
php冒泡排序與快速排序實例詳解
lag ++ function 開始 ret light 記錄 php冒泡排序 php $a=array(‘3‘,‘8‘,‘1‘,‘4‘,‘11‘,‘7‘); print_r($a); $len = count($a); //從小到大 for($i=1;$i<$le
MySQL之SELECT 語句詳解
限制 right ont 定義 過程 lar load avg sel 本文參考實驗樓的SELECT 語句詳解結合自己操作部分而寫成。 註意:大多數系統中,SQL語句都是不區分大小寫的,但是出於嚴謹和便於區分保留字和變量名,在書寫的時,保留字應大寫,而變量名應小寫。所謂的保
MySql表結構修改詳解
參數 詳解 增加 not des reat fault sign charset 修改表的語法=========================增加列[add 列名]=========================①alter table 表名 add 列名 列類型 列參
mysql數據庫 詳解 之 自學成才1
簡化 註意 可能 方法 after 字符型 專題 mar 建議 一、學習目錄 1.認識數據庫和mysql 2.mysql連接 3.入門語句 4.詳解列類型 5.增刪改查 INSERT INTO 表名(列1,…… 列n) VALUES(值 1,…… 值 n); *(列
php中二維數組排序問題方法詳解
ges cti cmp each ace esc 對數 x11 用法 PHP中二維數組排序,可以使用PHP內置函數uasort() 示例一: 使用用戶自定義的比較函數對數組中的值進行排序並保持索引關聯 回調函數如下:註意回調函數的返回值是負數或者是false的時候,表
mysql慢查詢功能詳解
mysql 慢查詢 優化有人的地方就有江湖,數據庫也是,sql優化這個問題,任重道遠,我們總是禁不住有爛sql。怎麽辦呢,還好各大數據庫都有相關爛sql的收集功能,而mysql的慢查詢收集也是異曲同工,配合分析sql的執行計劃,這個優化就有了搞頭了。開啟mysql慢查詢日誌1.查看當前慢查詢設置情況#查看慢查
MySQL配置文件mysql.ini參數詳解、MySQL性能優化
說明 select 磁盤 addition sock 硬盤 並發連接 查詢緩存 show my.ini(Linux系統下是my.cnf),當mysql服務器啟動時它會讀取這個文件,設置相關的運行環境參數。 my.ini分為兩塊:Client Section和Serv
排序算法詳解
分治思想 分享 ray span 排序 排序算法 序列 jpg 兩個 1.歸並算法步驟: 1>分解:將無序序列不斷分裂,直到每個區間都只有一個數據為止(遞歸實現) 2>合並:將兩個區間合並為有序區間,一直合並到只有一個區間為止(分治思想) 下面代碼為歸
mysql explain執行計劃詳解
xtend ble 根據 order 其他 重復記錄 計劃 現在 中間 1)、id列數字越大越先執行,如果說數字一樣大,那麽就從上往下依次執行,id列為null的就表是這是一個結果集,不需要使用它來進行查詢。 2)、select_type列常見的有: A
Mysql加鎖過程詳解
插入記錄 控制 uniq null 詳細 server 讀者 index 理論知識 1、背景 MySQL/InnoDB的加鎖分析,一直是一個比較困難的話題。我在工作過程中,經常會有同事咨詢這方面的問題。同時,微博上也經常會收到MySQL鎖相關的私信,讓我幫助解決一些死
Mysql加鎖過程詳解(4)-select for update/lock in share mode 對事務並發性影響
per inno targe 允許 evel transacti 修改 not null warn select for update/lock in share mode 對事務並發性影響 事務並發性理解 事務並發性,粗略的理解就是單位時間內能夠執行的事務數量,常見的單
MySQL事務隔離級別詳解
默認 多少 bcf 結構 有一個 個數 ref tle eat 轉載自: MySQL事務隔離級別詳解 SQL標準定義了4類隔離級別,包括了一些具體規則,用來限定事務內外的哪些改變是可見的,哪些是不可見的。低級別的隔離級一般支持更高的並發處理,並擁有更低的系統開銷。Read
「mysql優化專題」詳解引擎(InnoDB,MyISAM)的內存優化攻略?(9)
區域 order by 順序 重做日誌 浪費 變量 效率 攻略 分區 註意:以下都是在MySQL目錄下的my.ini文件中改寫(技術文)。 一、InnoDB內存優化 InnoDB用一塊內存區域做I/O緩存池,該緩存池不僅用來緩存InnoDB的索引塊,而且也用來緩存InnoD