
pytorch+yolov3(1)
參考:https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
如何在PyTorch中從頭開始實現YOLO(v3)物件檢測器:第1部分
圖片來源:Karol Majek。在這裡檢視他的YOLO v3實時檢測視訊
物件檢測是一個從深度學習的最新發展中受益匪淺的領域。近年來人們開發了許多用於物體檢測的演算法,其中一些演算法包括YOLO,SSD,Mask RCNN和RetinaNet。
在過去的幾個月裡,我一直致力於改善研究實驗室的物體檢測。從這次經歷中獲得的最大收穫之一就是意識到學習物件檢測的最佳方法是從頭開始自己實現演算法。這正是我們在本教程中要做的。
我們將使用PyTorch實現基於YOLO v3的物件檢測器,YOLO v3是一種更快的物件檢測演算法。
本教程的程式碼旨在在Python 3.5和PyTorch 0.4上執行。它可以在這個Github回購中找到它的全部內容。
本教程分為5個部分:
-
第1部分(本章):瞭解YOLO的工作原理
先決條件
-
您應該瞭解卷積神經網路的工作原理。這還包括殘差塊,跳過連線和上取樣的知識。
-
什麼是物件檢測,邊界框迴歸,IoU和非最大抑制。
-
基本的PyTorch用法。您應該能夠輕鬆建立簡單的神經網路。
我已經在帖子的末尾提供了連結,以防你在任何方面都不知所措。
什麼是YOLO?
YOLO代表你只看一次。它是一個物體探測器,它使用深度卷積神經網路學習的特徵來探測物體。在我們弄清楚程式碼之前,我們必須瞭解YOLO的工作原理。
完全卷積神經網路
YOLO僅使用卷積層,使其成為完全卷積網路(FCN)。它有75個卷積層,具有跳過連線和上取樣層。不使用任何形式的池,並且使用具有步幅2的卷積層來對特徵圖進行下采樣。這有助於防止丟失通常歸因於池的低階功能。
作為FCN,YOLO對輸入影象的大小不變。然而,在實踐中,我們可能希望堅持不變的輸入大小,因為在我們實現演算法時只會出現各種問題。
這些問題中最重要的一點是,如果我們想要批量處理我們的影象(批量生成的影象可以由GPU並行處理,從而提高速度),我們需要擁有固定高度和寬度的所有影象。這需要將多個影象連線成一個大批量(將許多PyTorch張量連線成一個)
網路通過稱為網路步幅的因素對影象進行下采樣。例如,如果網路的步幅為32,那麼大小為416 x 416的輸入影象將產生大小為13 x 13的輸出。通常,網路中任何層的步幅等於輸出的大小。該圖層小於網路的輸入影象。
解釋輸出
通常,(對於所有物件檢測器的情況),由卷積層學習的特徵被傳遞到分類器/迴歸器上,該分類器/迴歸器進行檢測預測(邊界框的座標,類標籤等)。
在YOLO中,通過使用使用1×1卷積的卷積層來完成預測。
現在,首先要注意的是我們的輸出是一個特徵對映。由於我們使用了1 x 1個卷積,因此預測貼圖的大小正好是之前的特徵貼圖的大小。在YOLO v3(及其後代)中,您解釋此預測圖的方式是每個單元格可以預測固定數量的邊界框。
雖然在特徵圖中描述單元的技術上正確的術語將是神經元,但將其稱為單元格使其在我們的上下文中更直觀。
在深度方面,我們在特徵圖中有(B x(5 + C))個條目。B表示每個小區可以預測的邊界框的數量。根據該論文,這些B邊界框中的每一個可以專門檢測某種物件。每個邊界框都有5 + C屬性,用於描述每個邊界框的中心座標,尺寸,物件度分數和C類置信度。YOLO v3為每個單元預測3個邊界框。
如果物件的中心落在該單元格的感知區域中,您希望要素圖的每個單元格通過其中一個邊界框預測物件。(感受野區域是細胞可見的輸入影象區域。有關進一步說明,請參閱卷積神經網路上的連結)。
這與YOLO的訓練方式有關,其中只有一個邊界框負責檢測任何給定的物件。首先,我們必須確定這個邊界框屬於哪個單元格。
為此,我們將輸入影象劃分為尺寸等於最終要素圖的網格。
讓我們考慮下面的一個例子,其中輸入影象是416×416,網路的步幅是32.如前所述,特徵圖的尺寸將是13×13。然後我們將輸入影象分成13×13細胞。

然後,選擇包含物件的地面實況框的中心的單元(在輸入影象上)作為負責預測物件的單元。在影象中,它是標記為紅色的單元格,其中包含地面實況框的中心(標記為黃色)。
現在,紅色單元格是網格中第7行的第7個單元格。我們現在將特徵圖上的第7行中的第7個單元(特徵圖上的相應單元)指定為負責檢測狗的第7個單元。
現在,這個單元格可以預測三個邊界框。哪一個將被分配給狗的地面真相標籤?為了理解這一點,我們必須圍繞錨的概念進行梳理。
請注意,我們在這裡討論的單元格是預測要素圖上的單元格。我們將輸入影象劃分為網格,以確定預測特徵圖的哪個單元負責預測
錨箱
預測邊界框的寬度和高度可能是有意義的,但實際上,這會導致訓練期間不穩定的梯度。相反,大多數現代物體探測器預測對數空間變換,或簡單地偏移到預定義的稱為錨點的預設邊界框。
然後,將這些變換應用於錨箱以獲得預測。YOLO v3有三個錨點,可以預測每個單元格的三個邊界框。
回到我們之前的問題,負責檢測狗的邊界框將是其錨具有最高IoU和地面實況框的那個。
做出預測
以下公式描述瞭如何轉換網路輸出以獲取邊界框預測。
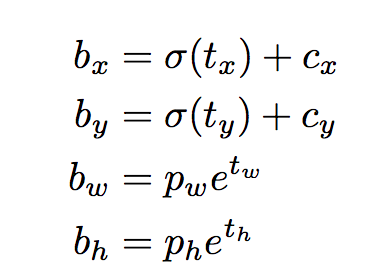
bx,by,bw,bh是我們預測的x,y中心座標,寬度和高度。tx,ty,tw,th是網路輸出的內容。cx和cy是網格的左上角座標。pw和ph是盒子的錨尺寸。
中心座標
請注意,我們通過sigmoid函式執行中心座標預測。這會強制輸出值介於0和1之間。為什麼會出現這種情況?忍受我。
通常,YOLO不會預測邊界框中心的絕對座標。它可以預測偏移量:
-
相對於預測物件的網格單元格的左上角。
-
由特徵圖中的單元尺寸標準化,即1。
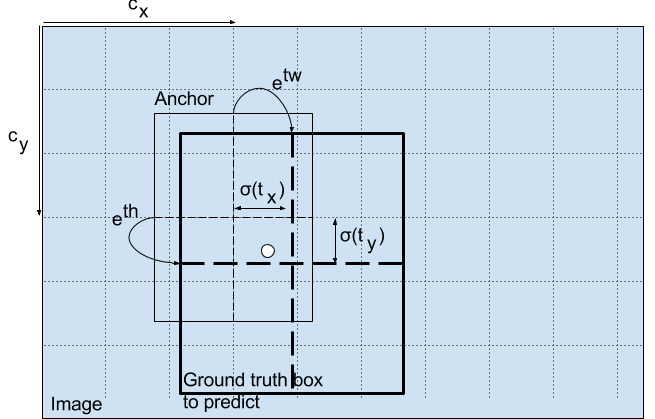
例如,考慮我們的狗影象的情況。如果對中心的預測是(0.4,0.7),那麼這意味著中心位於13 x 13特徵圖上的(6.4,6.7)。(由於紅細胞的左上角座標是(6,6))。
但等等,如果預測的x,y座標大於1,會發生什麼,比如說(1.2,0.7)。這意味著中心位於(7.2,6.7)。請注意,中心現在位於我們的紅細胞右側的細胞中,或者位於第7行的第8個細胞中。這打破了YOLO背後的理論,因為如果我們假設紅色框負責預測狗,那麼狗的中心必須位於紅色單元格中,而不是位於旁邊的單元格中。
因此,為了解決這個問題,輸出通過sigmoid函式傳遞,該函式將輸出壓縮在0到1的範圍內,有效地將中心保持在預測的網格中。
邊界框的尺寸
通過對輸出應用對數空間變換然後乘以錨來預測邊界框的尺寸。
如何轉換檢測器輸出以給出最終預測。圖片來源。http://christopher5106.github.io/
結果預測bw和bh由影象的高度和寬度標準化。(培訓標籤以這種方式選擇)。因此,如果包含狗的框的預測bx和by是(0.3,0.8),那麼13 x 13特徵圖上的實際寬度和高度是(13 x 0.3,13 x 0.8)。
物件分數
物件分數表示物件包含在邊界框內的概率。對於紅色和相鄰的網格,它應該接近1,而對於角落處的網格,幾乎為0。
物件性得分也通過sigmoid傳遞,因為它被解釋為概率。
階級信心
類置信度表示檢測到的物件屬於特定類(狗,貓,香蕉,汽車等)的概率。在v3之前,YOLO習慣了softmax的課堂成績。
但是,該設計選擇已在v3中刪除,作者選擇使用sigmoid。原因是Softmaxing類得分假設類是互斥的。簡單來說,如果一個物件屬於一個類,那麼它就保證它不屬於另一個類。這對於我們將以檢測器為基礎的COCO資料庫來說是正確的。
但是,當我們有像女人和人一樣的課程時,這種假設可能不會成立。這就是作者避免使用Softmax啟用的原因。
跨越不同尺度的預測。
YOLO v3通過3種不同的尺度進行預測。檢測層用於在三種不同尺寸的特徵圖上進行檢測,分別具有步幅32,16,8。這意味著,輸入為416 x 416,我們在13 x 13,26 x 26和52 x 52的刻度上進行檢測。
網路對輸入影象進行下采樣,直到第一檢測層為止,其中使用具有步幅32的層的特徵圖進行檢測。此外,將層上取樣2倍並且與具有相同特徵圖的先前層的特徵圖連線。大小。現在在具有步幅16的層處進行另一檢測。重複相同的上取樣過程,並且在步幅8的層處進行最終檢測。
在每個尺度上,每個單元格使用3個錨點預測3個邊界框,使得使用的錨點總數為9.(不同尺度的錨點不同)

作者報告說,這有助於YOLO v3更好地檢測小物體,這是YOLO早期版本的常見抱怨。上取樣可以幫助網路學習細粒度的特徵,這些特徵有助於檢測小物體。
輸出處理
對於尺寸為416×416的影象,YOLO預測((52×52)+(26×26)+ 13×13))×3 = 10647個邊界框。然而,在我們的影象的情況下,只有一個物件,一隻狗。我們如何將檢測從10647減少到1?
通過物件置信度進行閾值處理
首先,我們根據物件得分過濾盒子。通常,忽略具有低於閾值的分數的框。
非最大抑制
NMS旨在解決同一影象的多次檢測問題。例如,紅色網格單元的所有3個邊界框可以檢測到框,或者相鄰的單元可以檢測相同的物件。

如果您不瞭解NMS,我已經提供了一個連結到網站解釋相同的內容。
我們的實施
YOLO只能檢測屬於用於訓練網路的資料集中存在的類的物件。我們將使用官方重量檔案作為我們的探測器。這些權重是通過在COCO資料集上訓練網路獲得的,因此我們可以檢測80個物件類別。
這是第一部分。這篇文章詳細解釋了YOLO演算法,使您能夠實現檢測器。但是,如果您想深入瞭解YOLO如何工作,如何訓練以及如何與其他探測器相比,您可以閱讀原始論文,我在下面提供的連結。
就是這部分。在下一部分中,我們實現了將檢測器組合在一起所需的各種層。
進一步閱讀
Ayoosh Kathuria目前是印度國防研究與發展組織的實習生,他正致力於改善粒狀視訊中的物體檢測。當他不工作時,他正在睡覺或者在他的吉他上玩粉紅色弗洛伊德。您可以在LinkedIn上與他聯絡,或者檢視他在GitHub上做的更多內容
保持最新!將所有最新且最好的帖子直接傳送到您的收件箱
訂閱