
用 Go 搭建 Kubernetes Operators
隨著容器越來越流行,k8s也成為很多公司標配,Kubernetes 讓當前主流的基礎架構有一套易用的 API 。利用好 Kubernetes ,我們可以實現更高的、更通用的基礎架構自動化管理。基於此, CoreOS 實現了一套能“自動駕駛”的 Kubernetes 。在本次演講中,來自 CoreOS 的鄧洪超將通過自身參與的經驗,講解其中的技術細節。並以主要負責的 etcd operator 為例,講解在 Kubernetes 搭建 Operator 的通用模式。
鄧洪超:今天非常榮幸來到這裡。首先介紹一下 Operator ,它是用來自動化應用的運維的。這裡的應用指的是你的 code+config、程式、邏輯層和部署層。
一個例子
開始之前我們先講一個故事,這個故事一般朋友圈比較多,我們是從朋友圈開始的,大家知道pingCAP不僅資料庫做得好,周邊也做得很好。

圖1
賣周邊就得做一個網站,那黃東旭是GO的大牛,GO這個語言可以讓我們非常快速的做一個網站出來。Golang 可以讓我們非常快速地做一個網站出來。於是我們很快的就有了一個原形,給大家欣賞一下底層程式設計師的設計。
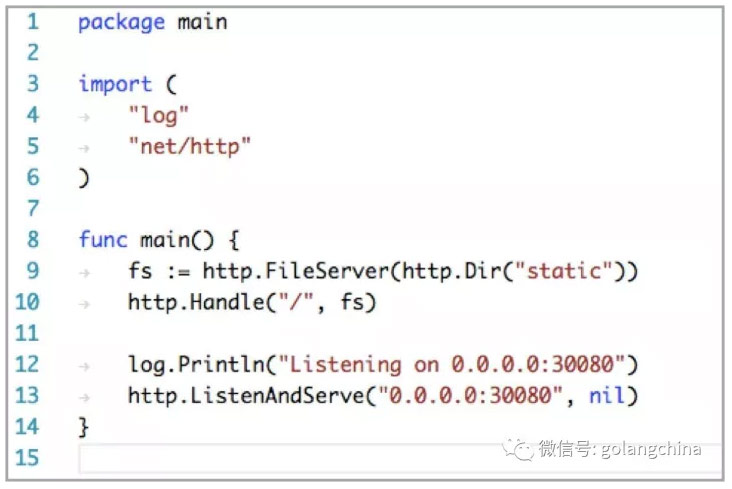
圖2
可以說GO是一門非常好的語言,它可以讓我們非常簡單和方便的實現從想法到程式的轉變。然後我們寫程式是本地層面的,需要部署到一個伺服器層面裡面。首先我們要對這個程式進行打包,並且把我們的服務包釋出出去。這就需要在伺服器叢集裡面配置儲存等資源,把程式部署出去,讓它跑起來去服務這些使用者請求。
部署無狀態的應用
接下來會告訴大家怎麼打包這個程式。如圖4所示,首先這是一個打包的命令,這是一個容器映象。我們會把這個進向釋出出去,釋出出去的時候我們已經有了一個叢集,是在跑的。我們現在把這個應用跑起來。首先在本地的這個關口我們是訪問不了的,我們會在本地30080埠,相當於我們找到了另外一個方法找這個服務。我們看到這時候的服務已經部署起來,我們可以訪問了。
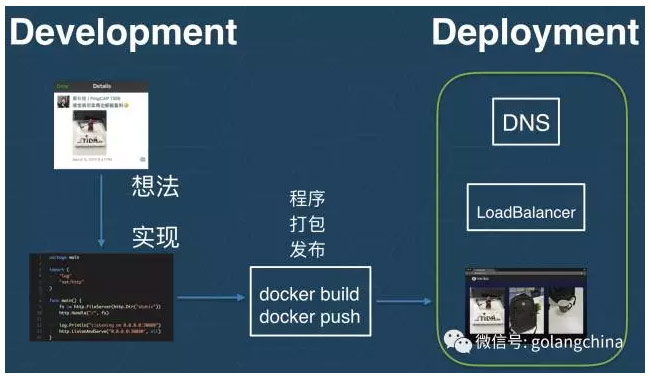
圖3
有了容器技術,讓我們非常方便——哪怕我從來不寫應用的,我也能非常簡單的部署一個應用。而我們剛才在這個過程中使用了容器的兩個工具,

圖4
這個對應了容器發展的兩個階段,在第一個階段我們對如何打包應用進行的標準化,這樣的話你服務包在網路傳輸裡面的格式是一致的,只要你用這種標準的格式打包了你的應用,無論跑在哪一個平臺上,無論服務提供商是誰——谷歌,或者騰訊雲,阿里雲,你的服務包在任何地方都可以被跑起來,是相容的。然後剛才這個過程是本地,是一個個體層面的。我們在部署的時候是要部署到一個伺服器叢集裡面去,這往往要求我們對這個叢集的資源進行配置、管理和排程。所以第二個階段我們需要一些工具去管理這個叢集。

圖5
有狀態的應用
容器技術發展到現在,可以說部署這一類的無狀態的外表應用是非常簡單的。而且據我所知,現在大部分
的這些企業的應用都是無狀態的應用,哪怕包括谷歌自身。這也是容器技術的出發點。然而對於部署一些有狀態的應用還是非常困難的,現階段大家都沒有很好的解決方面。那什麼是有狀態的應用呢?我這裡給大家舉一些例子。
比如說資料庫,你一些中介軟體,像Kafka,heron,還有做大資料的spark,等等這些都是狀態的服務。可以說部署這些有狀態服務是非常困難的,比這些無狀態的外表應用要複雜的多。一方面他們要求的這些配置更為複雜,而現在也很多,首先很多公司他們會有專門的團隊去管理,他們不會這麼簡單的管理,而是有專門的團隊去管理一個個叢集。甚至很多公司通過幫助管理這些有狀態的應用叢集來盈利。
prometheus
我們首先通過幾個例子,首先是prometheus,它是一個開源工具,當我們在跑這個prometheus的時候,一方面它需要知道選定服務的埠,它會對這些埠進行掃描,並且抓取它們的Matrix,最後把Matrix整合到一個接口裡面。另外一方面他要抓取這些規則,然後根據這個Matrix和規則,所以你在避暑prometheus的時候,會遇到一些非常複雜的關係型依賴。你在部署的時候不僅需要知道這個prometheus自身的部署規則,另一方面你還要根本環境的不同,而做一些重複性的運維操作。

圖6
Etcd
Etcd,是一款強一直的高可用的服務發現儲存倉庫。由於架構,它在啟動的時候會給所有成員的資訊,這樣所有人會去投票,從而產生一個leader,然後我們需要配置這些ID,配置這個運營,配置這個埠,然後我們還得對每一個都重複做同樣的操作,這些還只是靜態的。如果是動態的時候,我們還需要做一些有順序的操作。

圖7
Self-updating Kubernetes
大家都知道 OS 是會自動更新的,因為它有一套自動更新伺服器。那麼在它的另一個產品裡面,它就利用這一套更新伺服器,去給它做自動更新的服務。當一個更新發出來的時候,它的策略會長得像如圖8所示,他會說我需要把 APIServer 升級到 1.6 ,我把 etcd 升到 3.1.4 。當我們要升 etcd 的時候,我們在更新的時候,我們先會對叢集的資料做一遍備份,然後我們還要檢查這些更新路徑。比如我從3.0升到3.2,它會先從3.0升到3.1,然後從3.1升到3.2。然後叢集做滾動升級。確保每個都升級成功。最後當整個升級不成功的時候,他還會做回滾。
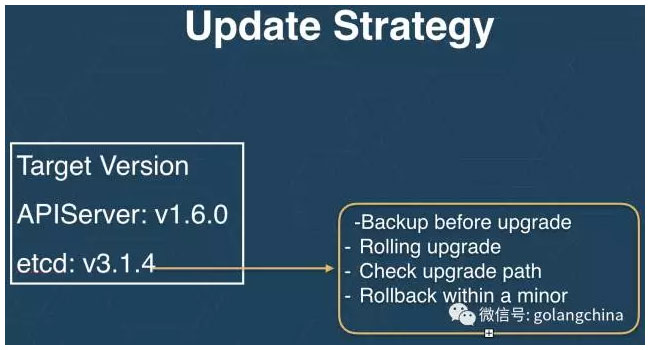
圖8
從我們看的這幾個例子,我們發現為什麼部署這些有狀態的應用和部署管理它們會比無狀態的複雜呢?是因為它們有這些複雜的運維和邏輯在裡面。它需要你去配置像ID,像網路資源,像儲存等等這些操作。並且這些會根據環境的不同而做一些重複性的工作。
operator
那麼正是為了解決這個問題,推出了一個叫operator的概念,那麼從軟體上我們會模擬一個運維人員,去不斷的更新,去做一些配置,來保證你的叢集、你的服務正常執行。那麼operator的工作原理如圖9所示。
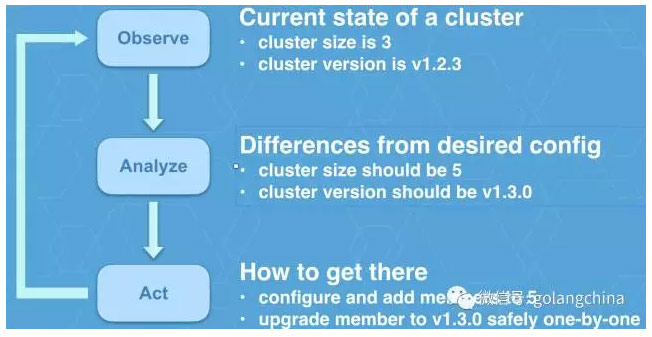
圖9
它主要有三個步驟,首先它會去觀察當前的狀態,比如說當前的叢集節點數量是三個,當前的叢集的版本等等,它會比較跟期望的有什麼不同。比如它發現我期望的叢集節點數量應該是5個,我期望的版本應該是1.3.0。最後它會做出行為去糾正。可能它會想辦法新增這些成員,把它從三個變成五個;也可能它會去更新這些一個個的成員,把它們從 1.2.3 升級到 3 。而在一輪做完之後又回到原點,去重新觀察,不斷的重複做這樣的工作,就像一個24小時在上班的運維人員一樣的,來保證這個叢集或者服務的正常健康的執行。
那麼正是基於這樣一個想法,我們寫了一個etcd operator來管理和部署ectd叢集。如圖10。

圖10
首先 ectd operator 能幫助大家在日常運維中的工作,比如說這個擴容,你要從三個節點擴容到五個結點,或者從五個節點縮減到三個節點。然後備份,因為 etcd 畢竟是存資料的,所以我們要對這個叢集進行自動備份。還有故障切換,當你有一個成員它死掉的時候,etcd operator 會自動換一個新的成員上去,來保證這個叢集健康執行。而對於更高階的使用者我們甚至提供更高階的功能,像恢復、TLS等等。
那麼 etcd operator 如果實現了上面這個功能,可以說它就是一個 RDS ,但是我個人覺得,etcd operator比 RDS 要高階的多。因為它這個etcd operator有一套陳述式的 API ,如圖11所示。什麼是陳述式的 API 呢,就是你只需要告訴說,我最後希望變成什麼樣?我不需要說究竟要怎麼一步步做成那樣。

圖11
我這裡舉個例子,比如我要建立一個 etcd 叢集,我告訴節點數量它是 3 個,然後叢集版本是3.1.5,我每隔300秒做一次備份,也就是每隔5分鐘做一次備份,我最多的這個備份數量是5個,那我們甚至還可以配置說我需要去存在這個PV裡邊還是S3裡面等等。這就是一個陳述式的API。就是陳述式的API可以讓裡面的線路是相容,是互通的。就像我們剛才定的API是一個更結構性的。但是我們一樣可以轉換成和其他的線路溝通。它一樣可以轉化成GO的API。

圖12

圖13
總結
容器發展我們經歷了兩個階段,第一個是格式的標準化,第二個是對容器更方便的配置這些資源,管理和排程這些資源。那慢慢的隨著這個應用的多元化,和應用的專門話以後未來在容器上會有越來越多的針對專門應用的自動化出現。這個也是我們推 operator 的原因,圖14是未來operator的發展方向,會以應用以服務為中心的一些自動化。

圖14
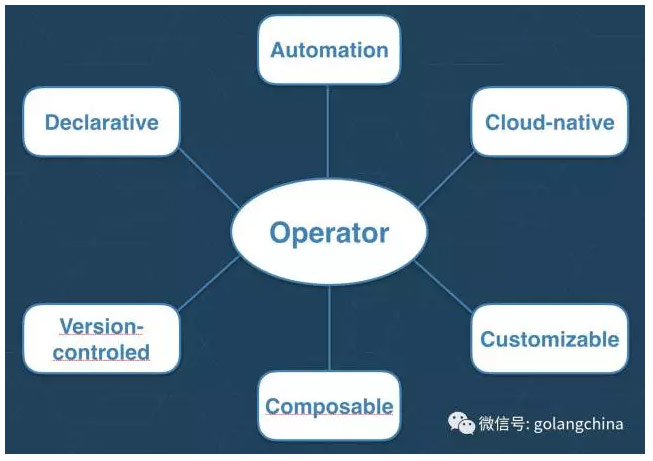
最後我們來定義operator究竟是什麼東西,以及prometheus未來會做什麼東西。operator的核心在於自動化,我們也看到operator的API是陳述式的,然後operator的API也是Cloud-native,operator也是customizable的,你可以自定義prometheus來跑在不同的環境裡面。
 本文轉自kubernetes中文社群-
用 Go 搭建 Kubernetes Operators
本文轉自kubernetes中文社群-
用 Go 搭建 Kubernetes Operators