
手寫爬蟲之糗事百科段子及神回覆
阿新 • • 發佈:2018-12-14
先貼程式碼吧,然後再說遇到的坑
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/10/11 16:35 # @Author : yuantup # @Site : # @File : jokes_.py # @Software: PyCharm import urllib.request import re import os def open_url(url): head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/5' '37.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} req = urllib.request.Request(url, headers=head) response = urllib.request.urlopen(req) html = response.read() return html def get_content(html): text1 = html.decode('utf-8') text2 = text1.replace('\n', '') text3 = text2.replace('<br>', '\n') text = text3.replace('<br/>', '\n') pattern = '<h2>(.*?)</h2>.*?<div class="content">.*?span>(.*?)</span>.*?<span class="stats-vote"><i class="number">(.*?)</i> 好笑</span>.*?<span class="cmt-name">(.*?)</span><div class="main-text">(.*?)<div class="likenum">.*?(\d*?)</div>' all_content_list = re.findall(pattern, text, re.S) print(all_content_list) for i in range(len(all_content_list)): with open('jokes_plus.txt', 'a', encoding='utf-8') as f: author = all_content_list[i][0] joker_content = all_content_list[i][1] fun_num = all_content_list[i][2] commentator = all_content_list[i][3] comment = all_content_list[i][4] dianzan_num = all_content_list[i][5] f.write('******這不是一條分界線*****\n\n') f.write(author + ':') print('1') f.write(':\n') f.write(joker_content) print('2') f.write('\n') f.write('有') f.write(fun_num) print('3') f.write('人覺得這個段子很好笑,你覺得呢?') f.write('\n') f.write('神評:') f.write('\n') f.write(commentator + ':') f.write(comment) f.write(' 點贊數:') f.write(dianzan_num) f.write('\n\n') def main(): path = 'E:\spiser_sons\jokes' a = os.getcwd() print(a) if os.path.exists(path): os.chdir(path) print(os.getcwd()) else: os.mkdir(path) os.chdir(path) for i in range(1, 21): url = 'https://www.qiushibaike.com/text/page/' + str(i) + '/' html = open_url(url) get_content(html) if __name__ == '__main__': main()
我是將爬取的程式碼整合到一個txt檔案中,
執行結果如圖:

昨天沒仔細看,我程式碼裡是計劃爬取20頁小段子的,現在發現從第十四頁開始就和第一頁重複了!!!
用瀏覽器進入糗事百科的網址,發現確實只有13頁,當頁數大於13時,自動跳轉為第一頁。
看來以後還是要更加仔細!
最後得到的檔案及部分內容:
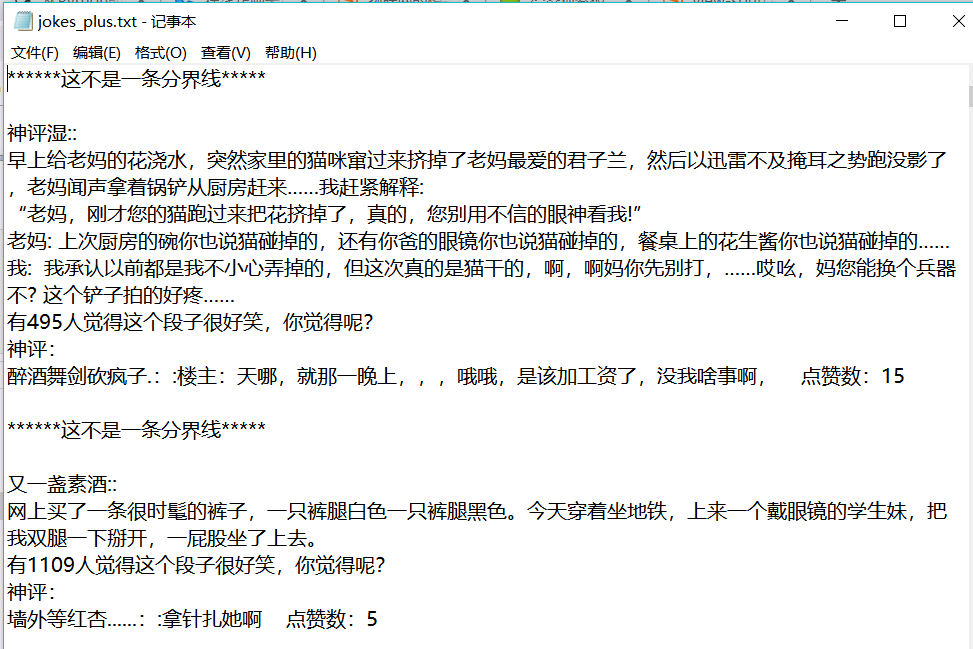
勉強能看,有藝術細胞的可以加工一下,hhhhh
坑一:
爬取下來的文字中夾雜這<br><br/>,使用字串的替換方法replace(),或者用re.sub()也可以
坑二:
這是我寫的正則表示式:
'<h2>(.*?)</h2>.*?<div class="content">.*?span>(.*?)</span>.*?<span class="stats-vote"><i class="number">(.*?)</i> 好笑</span>.*?<span class="cmt-name">(.*?)</span><div class="main-text">(.*?)<div class="likenum">.*?(\d*?)</div>'
可以看到裡面有很多小括號,這個時候我們用re.findall()得到的返回值是一個列表,每匹配一次列表就新增一個元素(元組),要理清他們的關係,搞混了就很難得到需要的內容
類似於這樣的:all_content_list = [(第1組資料),(第2組資料),(第3組資料)......]
每組資料裡包含6個數據,分別是
(
author, # 段子的作者名
joker_content, # 段子的內容
fun_num, # 覺得段子好笑的人數
commentator, # 神評的作者名
comment, # 神評的內容
dianzan_num # 神評點贊人數
)
它這個編輯器自動換行了我去。
坑三(未解決):
就是我寫的正則表示式過長,我試著用pycharm裡的燈泡解決問題,它給我換行之後就匹配不上我需要的內容了,求助各位大佬有啥好的解決辦法沒有!!!
燈泡是這個:
點選第一行後:

pycharm 也沒有警告了,但是也匹配不到東西的,還原成一行又可以成共匹配。
我自己感覺是不是因為換行之後多出了\n,或者是表示換行的'\'沒有被轉義,我怎麼感覺我找到答案了我去
試試去。。。。。
我還以為在=後面加個'r'就行。。。。。
失敗了,不行。。。。。
求助各位大佬給個建議,謝謝