
Python爬蟲之糗事百科段子寫入MySQL資料庫
在《Python爬取糗事百科段子》這篇文章中,我們獲取到了每一個段子的內容(content)、作者(auth)、作者主頁(home)、點贊數(votes)、評論數(comments)、段子地址(content_href)等資訊,現在我們只需要根據以上欄位名,建立資料庫表,將資訊逐條寫入資料庫就可以了。上程式碼!

# _*_ coding:utf-8 _*_
import requests
from bs4 import BeautifulSoup
import MySQLdb
import re
connect=MySQLdb.connect(host="localhost",user='root',passwd='',port=3306,charset='utf8')
cursor=connect.cursor()
def create_sql(cursor=cursor):
#用於建立資料庫
sql='create database if not exists qiushibaike default charset=utf8'
cursor.execute(sql)
print u'建立資料庫'
sql='use qiushibaike'
cursor.execute(sql)
sql='''create table if not exists info(
id int not null primary key auto_increment,
content varchar(500) not null ,
auth varchar(20) not null ,
votes int not null,
comms int not null,
home varchar(50) not null ,
content_href varchar(50) not null )
default charset=utf8
'''
cursor.execute(sql)
print u'建立資料表'
defget_content(url,connect=connect,cursor=cursor):
#用於獲取段子資訊,並將資訊寫入資料庫
sql='use qiushibaike'
cursor.execute(sql)
print u'選擇qiushibaike 資料庫'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
#url='https://www.qiushibaike.com/8hr/page/2/'
html=requests.get(url,headers=headers).content
soup=BeautifulSoup(html,'lxml')
div=soup.find_all('div',attrs={'class':'article block untagged mb15'})
#獲取段子所在的標籤塊
for item in div:
auth=item.find('h2').get_text()
print auth
#獲取作者資訊
home=item.find('a')['href']
home='https://www.qiushibaike.com/'+home
print home
#作者主頁
content_href=item.find('a',attrs={'class':'contentHerf'})['href']
content_href='https://www.qiushibaike.com/'+content_href
print content_href
#段子頁面
content=item.find('div',attrs={'class':'content'})
span=content.find('span').get_text()
print span
#獲取段子內容
stats=item.find('div',attrs={'class':'stats'}).get_text().replace(' ','')
print stats
#獲取評論數、點贊數
ss=re.findall('d+',stats)
if ss:
votes=ss[0]
comms=ss[1]
else:
votes=0
comms=0
print votes,comms
#點贊數、評論數
sql='insert into info (content,auth,votes,comms,home,content_href )values("%s","%s","%s","%s","%s","%s")'%(span,auth,votes,comms,home,content_href)
#print sql
try:
cursor.execute(sql)
print u'正在向資料庫插入資料'
connect.commit()
except Exception,e:
print u'發生異常',Exception,e
##捕捉異常資訊,有的欄位中有特殊符號,會導致資料寫入資料庫失敗
## raw_input(u'按enter鍵瀏覽下一條')
## print ' '
## ##邊看段子,邊將資料寫入資料庫。可以註釋掉
def main():
create_sql()
n=0
while n<30:
#這裡只抓取10頁,可根據需要設定n值
n=n+1
page=str(n)
print u'正在獲取第%s頁'%(page)
url='https://www.qiushibaike.com/8hr/page/%s/'%(page)
#print url
#抓取第n頁的段子
get_content(url)
if __name__ =='__main__':
main()
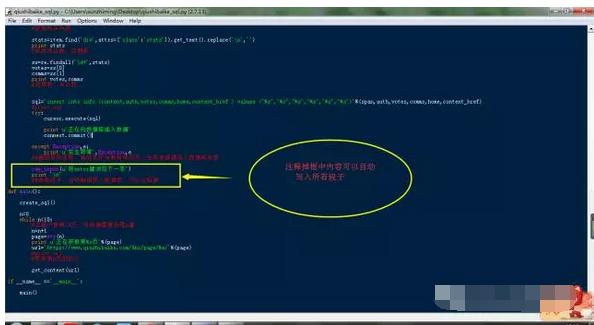
原始碼 群 960410445
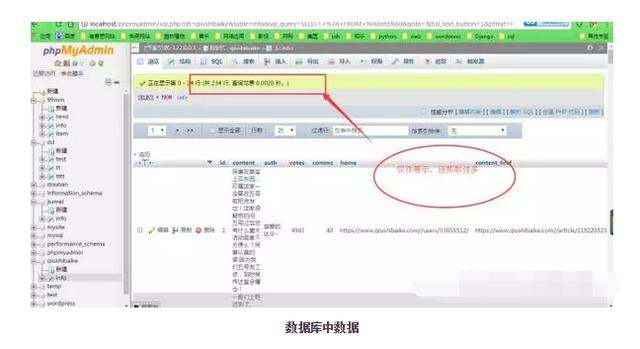
執行程式,我們就可以在資料庫中看到所有的段子了。之所以寫入資料庫,是便於以後更好的使用這些資料。比如找出點贊數大於5000的段子,根據段子手發的段子數以及其點贊數、評論數,分析誰是最熱的段子手,等等諸如此類的統計分析。當然還會有更有用的地方,這個我們以後會講到!