
大話叢集和負載均衡
在“高併發,海量資料,分散式,NoSql,雲端計算......”概念滿天飛的年代,相信不少朋友都聽說過甚至常與人提起“叢集,負載均衡”等,
但不是所有人都有機會真正接觸到這些技術,也不是所有人都真正理解了這些“聽起來很牛的”技術名詞。下面簡單解釋一下吧。
要了解這些概念首先要了解一下專案架構的演進,我這裡應用一張Dubbo的文件圖片如圖
一:專案架構的演進

ORM與MVC:
早期的架構都集中在一臺伺服器上,這樣對於小型的業務訪問量是完全可以的,但是隨著業務的增多,我們引進的MVC的架構,這種架構是將整個業務分成不同的層(表現層,業務層,資料訪問層)維護也更加方面了,開發更加方便。
PRC架構:
但是業務如果繼續增大,專案會出現臃腫,一臺伺服器已經完全沒辦法支援了,所以出現了RPC分散式的架構,RPC架構就是將服務進行合理拆分,分別放入多臺伺服器執行,伺服器與伺服器之間通過遠端呼叫的方式進行通訊。
服務提供者:執行在伺服器端,提供服務介面與服務實現類
服務中心:執行在伺服器端,負責將本地服務釋出成遠端服務,管理遠端服務,提供服務給消費者使用。
服務消費者:執行在客戶端,通過遠端代理物件呼叫遠端服務
SOA架構:
但是業務繼續增加,對RPC架構來說,各個服務與服務之間的通訊越來越多,依賴越來越多,越來越混亂,給開發帶來了困難,於是SOA架構應運而生,SOA架構將服務與服務集中起來進行管理,加上一個服務治理中心。誰釋出了服務來中心進行註冊,誰需要依賴什麼服務來中心進行請求。
而最近很火的微服務,則是將業務拆分更加精細,每一個可以成為一個完整的服務。演變肯定會演變,但是過程得多久誰也不好說。

二:名詞解釋
接下來進入正題,解釋讓外行看起來高大上的名詞
1:叢集
叢集(Cluster)
所謂叢集是指一組獨立的計算機系統構成的一個鬆耦合的多處理器系統,它們之間通過網路實現程序間的通訊。應用程式可以通過網路共享記憶體進行訊息傳送,實現分散式計算機。通俗一點來說,就是讓若干臺計算機聯合起來工作(服務),可以是並行的,也可以是做備份。
大規模叢集,通常具備以下一些特點:
(1)高可靠性(HA)
利用叢集管理軟體,當主伺服器故障時,備份伺服器能夠自動接管主伺服器的工作,並及時切換過去,以實現對使用者的不間斷服務。
(2)高效能運算(HP)
即充分利用叢集中的每一臺計算機的資源,實現複雜運算的並行處理,通常用於科學計算領域,比如基因分析、化學分析等。
(3)負載平衡(LB)
即把負載壓力根據某種演算法合理分配到叢集中的每一臺計算機上,以減輕主伺服器的壓力,降低對主伺服器的硬體和軟體要求。
常用的叢集又分以下幾種:
load balance cluster(負載均衡叢集)
一共有四兄弟開裁縫鋪,生意特別多,一個人做不下來,老是延誤工期,於是四個兄弟商量:老大接訂單, 三個兄弟來幹活。 客戶多起來之後,老大根據一定的原則(policy) 根據三兄弟手上的工作量來分派新任務。
High availability cluster(高可用叢集)
兩兄弟開早餐鋪,生意不大,但是每天早上7點到9點之間客戶很多並且不能中斷。為了保證2個小時內這個早餐鋪能夠保證持續提供服務,兩兄弟商量幾個方法:
方法一:平時老大做生意,老二這個時間段在家等候,一旦老大無法做生意了,老二就出來頂上,這個叫做 Active/Standby.(雙機熱備)
方法二:平時老大做生意,老二這個時候就在旁邊幫工,一旦老大無法做生意,老二就馬上頂上,這個叫做Active/Passive.(雙機雙工)
方法三:平時老大賣包子,老二也在旁邊賣豆漿,老大有問題,老二就又賣包子,又賣豆漿,老二不行了,老大就又賣包子,又賣豆漿.這個叫做Active/Active (dual Active)(雙機互備)
high computing clustering(高效能運算叢集)
10個兄弟一起做手工傢俱生意,一個客戶來找他們的老爹要求做一套非常複雜的仿古傢俱,一個人做也可以做,不過要做很久很久,為了1個星期就交出這一套傢俱,10個兄弟決定一起做。
老爹把這套傢俱的不同部分分開交給兒子們作,然後每個兒子都在做木製傢俱的加工,最後拼在一起叫貨。
老爹是scheduler任務排程器,兒子們是compute node. 他們做的工作叫做作業。
2:負載均衡
HTTP重定向負載均衡
當用戶發來請求的時候,Web伺服器通過修改HTTP響應頭中的Location標記來返回一個新的url,然後瀏覽器再繼續請求這個新url,實際上就是頁面重定向。通過重定向,來達到“負載均衡”的目標。例如,我們在下載JAVA原始碼包的時候,點選下載連結時,為了解決不同國家和地域下載速度的問題,它會返回一個離我們近的下載地址。重定向的HTTP返回碼是302。優點:比較簡單。缺點:瀏覽器需要兩次請求伺服器才能完成一次訪問,效能較差。重定向服務自身的處理能力有可能成為瓶頸,整個叢集的伸縮性國模有限;使用HTTP302響應碼重定向,有可能使搜尋引擎判斷為SEO作弊,降低搜尋排名。
DNS域名解析負載均衡
DNS(Domain Name System)負責域名解析的服務,域名url實際上是伺服器的別名,實際對映是一個IP地址,解析過程,就是DNS完成域名到IP的對映。而一個域名是可以配置成對應多個IP的。因此,DNS也就可以作為負載均衡服務。事實上,大型網站總是部分使用DNS域名解析,利用域名解析作為第一級負載均衡手段,即域名解析得到的一組伺服器並不是實際提供Web服務的物理伺服器,而是同樣提供負載均衡服務的內部伺服器,這組內部負載均衡伺服器再進行負載均衡,將請求分發到真是的Web伺服器上。優點:將負載均衡的工作轉交給DNS,省掉了網站管理維護負載均衡伺服器的麻煩,同時許多DNS還支援基於地理位置的域名解析,即會將域名解析成舉例使用者地理最近的一個伺服器地址,這樣可以加快使用者訪問速度,改善效能。缺點:不能自由定義規則,而且變更被對映的IP或者機器故障時很麻煩,還存在DNS生效延遲的問題。而且DNS負載均衡的控制權在域名服務商那裡,網站無法對其做更多改善和更強大的管理。
反向代理負載均衡
反向代理服務可以快取資源以改善網站效能。實際上,在部署位置上,反向代理伺服器處於Web伺服器前面(這樣才可能快取Web相應,加速訪問),這個位置也正好是負載均衡伺服器的位置,所以大多數反向代理伺服器同時提供負載均衡的功能,管理一組Web伺服器,將請求根據負載均衡演算法轉發到不同的Web伺服器上。Web伺服器處理完成的響應也需要通過反向代理伺服器返回給使用者。由於web伺服器不直接對外提供訪問,因此Web伺服器不需要使用外部ip地址,而反向代理伺服器則需要配置雙網絡卡和內部外部兩套IP地址。優點:和反向代理伺服器功能整合在一起,部署簡單。缺點:反向代理伺服器是所有請求和響應的中轉站,其效能可能會成為瓶頸。
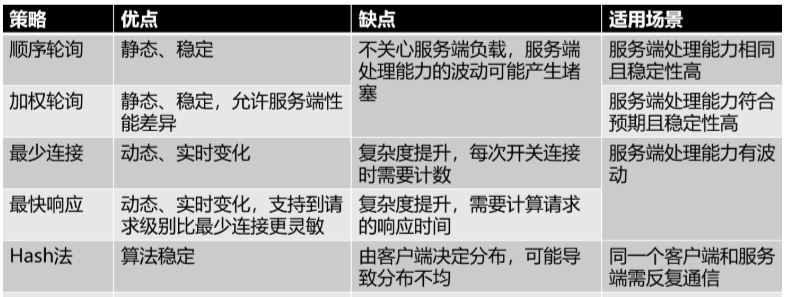
負載均衡策略
輪詢
加權輪詢
最少連線數
最快響應
Hash法
3:快取
快取就是將資料存放在距離計算最近的位置以加快處理速度。快取是改善軟體效能的第一手段,現在CPU越來越快的一個重要因素就是使用了更多的快取,在複雜的軟體設計中,快取幾乎無處不在。大型網站架構設計在很多方面都使用了快取設計。
CDN快取
內容分發網路,部署在距離終端使用者最近的網路服務商,使用者的網路請求總是先到達他的網路服務商哪裡,在這裡快取網站的一些靜態資源(較少變化的資料),可以就近以最快速度返回給使用者,如視訊網站和入口網站會將使用者訪問量大的熱點內容快取在CDN中。
反向代理快取
反向代理屬於網站前端架構的一部分,部署在網站的前端,當用戶請求到達網站的資料中心時,最先訪問到的就是反向代理伺服器,這裡快取網站的靜態資源,無需將請求繼續轉發給應用伺服器就能返回給使用者。
本地快取
在應用伺服器本地快取著熱點資料,應用程式可以在本機記憶體中直接訪問資料,而無需訪問資料庫。
分散式快取
大型網站的資料量非常龐大,即使只快取一小部分,需要的記憶體空間也不是單機能承受的,所以除了本地快取,還需要分散式快取,將資料快取在一個專門的分散式快取叢集中,應用程式通過網路通訊訪問快取資料。
3: 流控(流量控制)
流量丟棄
通過單機記憶體佇列來進行有限的等待,直接丟棄使用者請求的處理方式顯得簡單而粗暴,並且如果是I/O密集型應用(包括網路I/O和磁碟I/O),瓶頸一般不再CPU和記憶體。因此,適當的等待,既能夠替身使用者體驗,又能夠提高資源利用率。
通過分散式訊息佇列來將使用者的請求非同步化。