【Python】網路爬蟲(靜態網站)例項
阿新 • • 發佈:2018-12-15
本爬蟲的特點:
1.目標:靜態網站
2.級數:二級
3.執行緒:單執行緒(未採用同步,為了避免順序錯亂,因此採用單執行緒)
4.結果:爬取一部網路小說,將分散的各章節合併成一個txt文字檔案
獲取網頁模板:
def get_url(url): try: response = requests.get(url) print(response.encoding) print(response.apparent_encoding) response.encoding = response.apparent_encoding if response.status_code == 200: return response.text else: print("url Error:", url) except RequestException: print("URL RequestException Error:", url) return None
解析儲存函式:
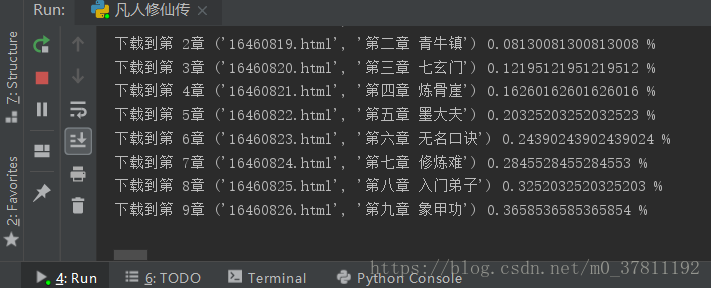
def parse_url(html): count = 0 essay = "" pattern = re.compile('<td class="L"><a href="(.*?)">(.*?)</a></td>', re.S) items = re.findall(pattern, html) pattern_page = re.compile('<meta property="og:url" content="(.*?)"/>', re.S) item_page = re.findall(pattern_page, html) print(items) print(items.__len__()) for item in items: count += 1 if count <= 2416: continue this_url = item_page[0] + item[0] this_title = item[1] essay = get_book(this_url, this_title).replace("\ufffd", "*") try: if count % 100 == 1: file = open(sys.path[0]+"凡人修仙傳.txt", "a") file.write(essay) if count % 100 == 0 or count == items.__len__(): file.close() print("前"+str(count)+"章儲存完畢!") print("下載到第 " + str(count) + "章", item, count / items.__len__() * 100, "%") except RequestException: # print("Error", item) print(essay)
完整程式碼:
import requests from requests.exceptions import RequestException import re import sys from multiprocessing import Pool import sqlite3 import os def get_url(url): try: response = requests.get(url) print(response.encoding) print(response.apparent_encoding) response.encoding = response.apparent_encoding if response.status_code == 200: return response.text else: print("url Error:", url) except RequestException: print("URL RequestException Error:", url) return None def parse_url(html): count = 0 essay = "" pattern = re.compile('<td class="L"><a href="(.*?)">(.*?)</a></td>', re.S) items = re.findall(pattern, html) pattern_page = re.compile('<meta property="og:url" content="(.*?)"/>', re.S) item_page = re.findall(pattern_page, html) print(items) print(items.__len__()) for item in items: count += 1 if count <= 2416: continue this_url = item_page[0] + item[0] this_title = item[1] essay = get_book(this_url, this_title).replace("\ufffd", "*") try: if count % 100 == 1: file = open(sys.path[0]+"凡人修仙傳.txt", "a") file.write(essay) if count % 100 == 0 or count == items.__len__(): file.close() print("前"+str(count)+"章儲存完畢!") print("下載到第 " + str(count) + "章", item, count / items.__len__() * 100, "%") except RequestException: # print("Error", item) print(essay) def get_book(url, title): data = "\n" + str(title) + "\n" pattern = re.compile('<dd id="contents">(.*?)</dd>', re.S) essay = re.findall(pattern, get_url(url)) essay_str = str(essay[0]) data = data + essay_str.replace(" ", " ").replace("<br />", "\n") return data if __name__ == '__main__': parse_url(get_url("https://www.x23us.com/html/0/328/"))