
深度學習 --- 改善深度神經網路 1
1. 如何劃分Train/Dev/Test Sets(訓練集,開發集,測試集)
-
資料集很小時,比如1萬或者10萬個樣本 機器學習中有很多種劃分Train,Dev,Test Sets的方法,在資料集比較小的時候,這些傳統的方法同樣適用於深度學習。最為常見的分配比例為7:3(Train vs Test)和6:2:2(Train vs Dev vs Test),這在機器學習中被認為是最佳的分配的比例。
-
資料集很大時,比如100萬 那麼此時的Dev和Test完全不需要20%,1%也許就可以了,因為1萬個資料也足以評估處模型的效能了。所以在大資料時代,這些比例的分配需要按照實際情況而定。
在大資料時代,還存在的以為問題就是資料分配的不匹配
總之,合理地分配好Train,Dev,Test Set,會使訓練迭代得更快,而且還能更高效地測量演算法存在的偏差和方差,然後就能更高效的選用適當的方法來改進演算法。
2. 如何分析High Bias/High Variance(高偏差,高方差)
2.1 High Bias和High Variance圖示
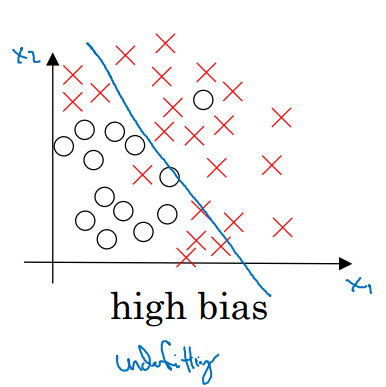 造成High Bias的原因可能是feature簡單,數量少,階次低等
造成High Bias的原因可能是feature簡單,數量少,階次低等
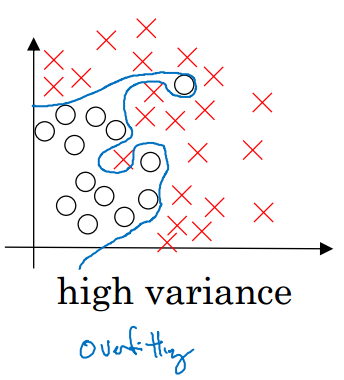
這兩種情況下,模型的泛化能力都比較差。一個好的模型應該達到下面這種‘剛剛好’的狀態
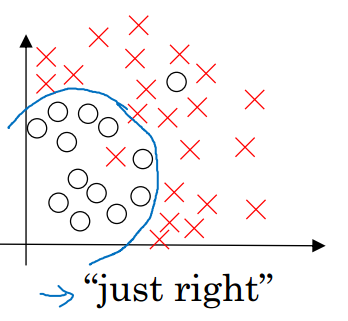
2.2 High Bias和High Variance分析
對於下面表格裡面的資料,我們分析一下其原因:
| Case 1 | Case 2 | Case 3 | Case 4 | |
| Train Error | 1% | 15% | 15% | 0.5% |
| Dev Error | 10% | 16% | 30% | 1% |
- Case 1 模型在Train Set上的擬合非常好,但是在Dev Set上面錯誤率卻比較大,泛化能力差。此為High Variance。
- Case 2 模型在Train Set上錯誤率較高,如果此時人工的錯誤率為0%,那麼說明模型並未把Train Set資料處理的比較好,但是它在Dev Set上的表現和Train Set差不多,處於可以接受的範圍。屬於High Bias。
- Case 3
模型在Train Set上面的錯誤率高,在Dev Set上更高,說明這是一個非常糟糕的模型。既有Hight Variance,也有High Bias。
這個比較難理解,舉一個圖例:
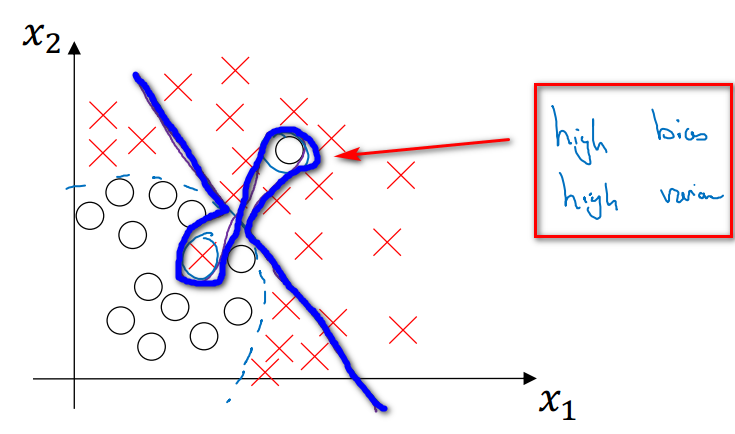
- Case 4 模型在Train上錯誤率很低,說明擬合地很好,在Dev Set上的錯誤率也才1%,說明泛化能力也很好。這是一個好的模型,屬於Low Variance,Low Bias。
Bayes Error(貝葉斯誤差) 簡單來說,在理想情況下的誤差也被稱為貝葉斯誤差。比如人工分類圖片的誤差為0%,那麼貝葉斯誤差也接近於0%。比如Case 2中,Bayes error為15%,那麼它就不再是一個High Bias的問題了,它應該說是一個非常好的模型。
總結
- 通過觀察訓練集的誤差,至少可以知道你的演算法是否可以很好的擬合訓練集資料,然後總結出是否屬於高偏差問題。
- 然後通過觀察同一個演算法在開發集上的誤差為多少,可以知道這個演算法是否有高方差問題。這樣你就能判斷訓練集上的演算法是否在開發集上同樣適用。這會讓你意識到方差問題,上述結果都基於貝葉斯誤差非常低並且你的訓練集和開發集都來自與同一個分佈,如果不滿足這些假設那麼你需要做一個更復雜的分析。

另外,通過學習曲線,也能夠很好的分析High Bias和High Variance的問題
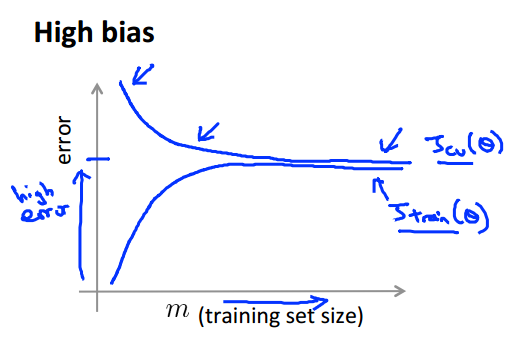 High Bias的學習曲線的特點是,Train Set和Dev Set的錯誤率都很高,而且兩者的錯誤率比較接近
High Bias的學習曲線的特點是,Train Set和Dev Set的錯誤率都很高,而且兩者的錯誤率比較接近
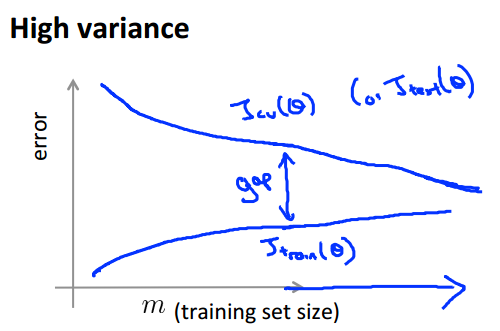 High Variance的學習曲線的特點是,Train Set的錯誤率比較低,而Dev Set的比較高,而且兩者的gap比較大
High Variance的學習曲線的特點是,Train Set的錯誤率比較低,而Dev Set的比較高,而且兩者的gap比較大
2.3 High Bias和High Variance處理原則
在深度學習中對於High Bias和High Variance的處理原則如下:
- 首先判斷是否為High Bias,如果是,那麼可以採用更大的深度神經網路,比如更多的層數,更多的單元數,或者更長的訓練時間
- 然後判斷是否為High Variance,如果是,則可以增大訓練資料或者採用正規化,比如Dropout,L1/L2正規化
在傳統的機器學習中,減少Bias可能引起增加variance,但是這個問題在DNN中可以避免,通過更多的訓練資料或者更復雜的神經網路,並輔以正規化,完全可單方消減bias或者variance
3.如何解決High Bias和High Variance—Regularization(正則化)
對於High Bias問題的解決,主要是通過調整網路結構或者訓練時間。 對於High Variance的問題,如果獲取更多資料的代價太大,我們應該採用Regularization,它能有效地防止過擬合。
3.1 邏輯迴歸中的Regularization
為什麼Regularization能夠防止過擬合,請參考機器學習之Regularization 邏輯迴歸中添加了Regularization的Cost函式為: ,其中 ,即向量w的歐幾里得範數的平方,也稱為L2正則化。 ,即向量w的歐幾里得範數,也稱為L1正則化。
L1和L2正則化的差別在於:L1正則化會使得w變得稀疏,即w中有很多的0,因為有一部分0,會佔用較少的記憶體,有些人認為它有助於壓縮模型(但效果並不好)。但是在實際應用中,L2使用的更頻繁。
注意:在Regularization過程中,並沒有對引數b正則化,主要因為b只是單個數字,幾乎所有的引數都集中在w中,它實際上起不到太大的作用,所以可以忽略。
3.2 神經網路中的Regularization
,其中 ,因為在神經網路中W為一個 x 的矩陣,所以這裡的Regularization需要計算每一層W矩陣的元素平方和。
注意:在這裡被稱為Frobenius norm而不是L2 norm。
由於多添加了一項Regularization,那麼它對於反向傳播會有什麼影響呢?如下:
和沒有Regularization時相比,比之前更小了,因此該L2正則化也被稱為weight decay(權重衰減)
3.3 為什麼Regularization能夠防止overfitting
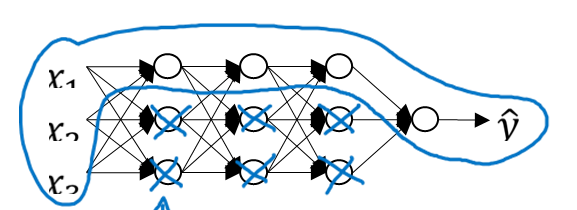
以上述的神經網路為例,當,那麼這就意味著神經網路中很多的隱藏單元都將處於disabled狀態,那麼這將使得神經網路變得非常非常簡單,趨於一個簡單的線性邏輯迴歸模型,避免了過擬合的問題。
還可以從另一個方面來解釋,如下圖的啟用函式所示:當z趨於0時,a是趨於線性的,當z趨於正負無窮大時,a是非線性的。
當時,,也會變小趨於0,那麼也將趨於線性。這就意味著整個神經網路都是趨於線性的,由此很好的避免了過擬合問題

3.4 Dropout Regularization
除了L2正則化,Dropout是在神經網路中另一個非常強大的正則化方法。 該方法即在每一層以一定的概率隨機刪除掉神經元,所謂的刪除實際上是將層中被刪除的神經元位置的賦值為0,,如下圖所示:
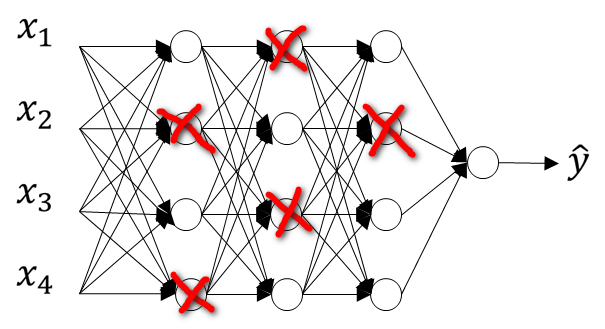
由此可以簡化神經網路結構,達到防止過擬合的目的。
以下為Inverted Dropout的實現原理:
-
以上圖第3層為例,設定保留率keep.prop = 0.8,即刪除率為0.2
-
按照保留率生成矩陣d3,通過下面的方法可以使得d3 80%的元素為1或者True,20%的元素為0或者False
<