
[DeeplearningAI筆記]改善深層神經網路1.1_1.3深度學習實用層面_偏差/方差/欠擬合/過擬合/訓練集/驗證集/測試集
覺得有用的話,歡迎一起討論相互學習~Follow Me
1.1 訓練/開發/測試集
對於一個數據集而言,可以將一個數據集分為三個部分,一部分作為訓練集,一部分作為簡單交叉驗證集(dev)有時候也成為驗證集,最後一部分作為測試集(test).接下來我們開始對訓練集執行訓練演算法,通過驗證集或簡單交叉驗證集選擇最好的模型.經過驗證我們選擇最終的模型,然後就可以在測試集上進行評估了.在機器學習的小資料量時代常見的做法是將所有資料三七分,就是人們常說的70%訓練集集,30%測試集,如果設定有驗證集,我們可以使用60%訓練,20%驗證和20%測試集來劃分整個資料集.這是前幾年機器學習領域公認的最好的測試與訓練方式,如果我們只有100條/1000條/1W條資料,我們按照上面的比例進行劃分是非常合理的,但是在大資料時代,我們現在的資料量可能是百萬級,那麼驗證集和測試集佔資料總量的比例會趨向變得更小.因為驗證集的目的就是驗證不同的演算法檢驗那種演算法更加有效,在大資料時代我們可能不需要拿出20%的資料作為驗證集.比如我們有100W
那我們取1W條資料便足以找出其中表現最好的1-2種演算法.同樣地,根據最終選擇的分類器,測試集的主要目的是正確評估分類器的效能.所以,如果擁有百萬級資料我們只需要1000條資料,便足以評估單個分類器.準確評估分類器的效能
假設我們有100W條資料,其中1W條做驗證集,1W條做測試集,訓練集佔98%,驗證集和測試集各佔1%.對於資料量過百萬級別的資料我們可以使測試集佔0.5%,驗證集佔0.5%或者更少.測試集佔0.4%,驗證集佔0.1%.
經驗之談:要確保驗證集和測試集的資料來自同一分佈.
最後一點,就算沒有測試集也不要緊,測試集的目的是對最終選定的神經網路系統做出無偏評估,如果不需要無偏評估也可以不設定測試集所以如果只有驗證集沒有測試集.我們要做的就是在訓練集上訓練嘗試不同的模型框架,在驗證集上評估這些模型,然後迭代並選出適用的模型.因為驗證集已經包含有測試集的資料,故不在提供無偏效能評估.當然,如果你不需要無偏評估,那就再好不過了.在機器學習如果只有訓練集和驗證集但是沒有獨立的測試集,這種情況下,訓練集還是訓練集,而驗證集則被稱為測試集.不過在實際應用中,人們只是把測試集當做簡單交叉驗證集使用,並沒有完全實現該術語的功能.因為他們把驗證集資料過度擬合到了測試集中.如果某團隊跟你說他們只設置了一個訓練集和一個測試集我會很謹慎,心想他們是不是真的有訓練驗證集.因為他們把驗證集資料過渡擬合到了測試集中.讓這些團隊改變叫法,改稱其為”訓練驗證集”.
1.2 偏差/方差
偏差(Bias)方差(Variance)這兩個概念易學難精,在深度學習的領域對偏差 方差的權衡研究甚淺.但是深度學習的卻很少權衡的考慮這兩個概念,都是分別得考慮偏差和方差.
欠擬合
“欠擬合(underfitting)”當資料不能夠很好的擬合數據時,有較大的誤差.
以下面這個邏輯迴歸擬合的例子而言:
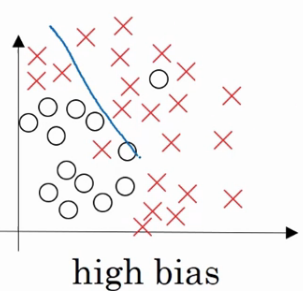
這就是high bias的情況.
過擬合
“過擬合(overfitting)”如果我們擬合一個非常複雜的分類器,比如深度神經網路或者含有隱藏神經的神經網路,可能就非常適用於這個資料集,但是這看起來不是一種很好的擬合方式,分類器方差較高,資料過度擬合
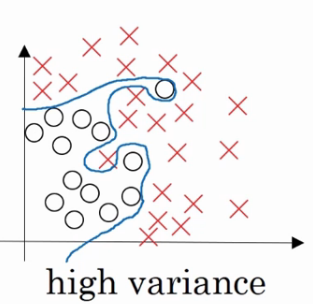
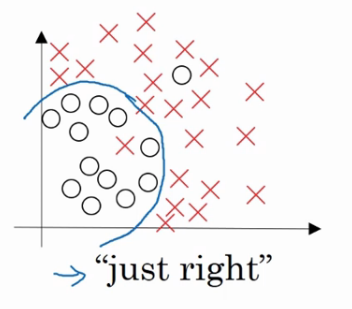
適度擬合
複雜程度市中,資料擬合適度的分類器,資料擬合程度相對合理,我們稱之為”適度擬合”是介於過擬合和欠擬閤中間的一類.
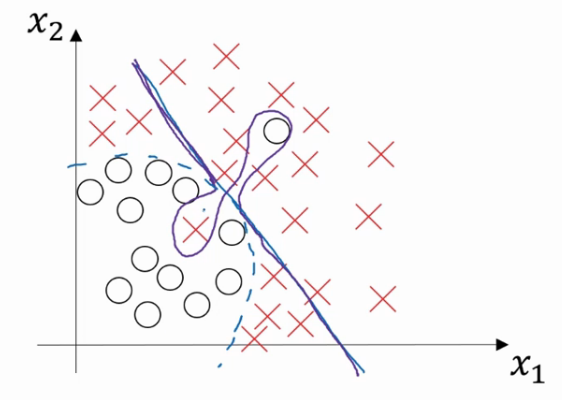
在這樣一個只有x1和x2兩個特徵的二維資料集中,我們可以繪製資料,將偏差和方差視覺化.但是在高維空間資料中,會直屬局和視覺化分割邊界無法實現.但我們可以通過幾個指標來研究偏差和方差.
高方差高偏差
高偏差指的是無法很好的擬合數據,高偏差指的是資料擬合靈活性過高,曲線過於靈活但是還包含有過度擬合的錯誤資料.
通過驗證集/訓練集判斷擬合
“過擬合”:訓練集中錯誤率很低,但是驗證集中錯誤率比驗證集中高很多.方差很大.
“欠擬合”:訓練集中錯誤率相對比較高,但是驗證集的錯誤率和訓練集中錯誤率差別不大.偏差很大.
偏差和方差都很大: 如果訓練集得到的錯誤率較大,表示不能很好的擬合數據,同時驗證集上的錯誤率甚至更高,表示不能很好的驗證演算法.這是偏差和方差都很大的情況.
較好的情況: 訓練集和驗證集上的錯誤率都很低,並且驗證集上的錯誤率和訓練集上的錯誤率十分接近.

以上分析的前提都是假設基本誤差很小,訓練集和驗證集資料來自相同分佈,如果沒有這些前提,分析結果會更加的複雜.
1.3 引數調節基本方法
初始訓練完成後,首先看演算法的偏差高不高,如果偏差過高,試著評估訓練集或訓練資料的效能.如果偏差真的很大,甚至無法擬合數據,現在就要選擇一個新的網路.比如有更多隱層或者隱藏單元的網路.或者花費更多時間訓練演算法或者嘗試更先進的優化演算法.(ps:一般來講,採用規模更大的網路通常會有幫助,延長訓練時間不一定有用,但是也沒有壞處,訓練學習演算法時,會不斷嘗試這些方法,知道解決掉偏差問題,這是最低標準,通常如果網路足夠大,一般可以很好的擬合訓練集)
一旦訓練集上的偏差降低到一定的水平,可以檢查一下方差有沒有問題.為了評估方差我們要檢視驗證集效能.如果驗證集和訓練集的錯誤率誤差較大即方差較大,最好的方法是採用更多資料.如果不能收集到更多的資料,我們可以採用正則化來減少過擬合.
我們需要選擇正確的方法,不斷迭代改進,如果是偏差本身比較大,準備更多的訓練資料也沒有什麼用,所以一定要看清是哪方面出了問題.一般來講選擇正確的方法,使用更大更深的網路,更多的資料可以得到很好的效果