
使用Ambari接管線上Hadoop遊戲資料叢集的避坑祕籍
本文首先將簡要介紹我們生產環境中 Hadoop 叢集現狀、Ambari 的關鍵技術,然後將重點闡述我們 Ambari 管理監控線上 Hadoop 叢集的技術方案,介紹線上接管過程中碰見的問題和解決方式。

公司在保持遊戲事業快速增長的同時也認識到資料的重要性,在大資料規劃層面,為了快速加強我司的遊戲資料整合能力、分析能力與行動能力,我們已經在 2014 年年底啟動,結合成本、效率等多種因素選用 Apache 開源的 Hadoop 技術。
在這裡我還是要推薦下我自己建的大資料學習交流qq裙: 957205962, 裙 裡都是學大資料開發的,如果你正在學習大資料 ,小編歡迎你加入,大家都是軟體開發黨,不定期分享乾貨(只有大資料開發相關的),包括我自己整理的一份2018最新的大資料進階資料和高階開發教程,歡迎進階中和進想深入大資料的小夥伴
最初以 Hadoop v2.2.0 社群版搭建以其為核心的叢集,結合自研的作業編排、資料排程等系統,打造了滿足遊戲業務中包括平臺運營、廣告投放等資料的收集、分析與挖掘需要的大資料平臺。
然而,隨著公司遊戲事業在國內、海外,頁遊、手遊佈局的擴大,支撐公司在遊戲發行與遊戲研發方面不斷增長的資料資源與服務的叢集規模也在不停增長。
Hadoop 遊戲資料叢集承載著遊戲發行與遊戲研發中主要包括使用者行為資料、平臺運營資料等資料的多方採集、處理與分析,為公司遊戲發行各環節提供有力的資料保障。
目前 Hadoop 遊戲資料叢集規模已經發展到上百節點,叢集的計算能力支撐著 TB 級別的日增資料量,以及上萬次作業的處理規模。
但無論是我們的日常叢集管理與監控,還是 2016 年對叢集從 v2.2.0 至 v2.7.3 的線上升級,我們發現對叢集的管理上都不夠系統與全面,叢集運維不夠簡便與智慧。
主要有以下不足:
-
叢集中資源的安裝、擴容、升級不方便,特別是資源元件間的依賴配置管理難。
-
叢集中各個 Service 缺少統一的叢集整體監控,往往只能通過查單 Host 機器效能指標輔助排查問題和效能調優,導致效率低下。
-
叢集資源各個 Component 的監控,無法充分利用其 Metrics 指標,基於時間序進行統一的健康觀察,排查穩定性難。
-
平臺整合現有叢集監控運維工具難,也缺乏直觀的使用者介面,不方便有效地查勘平臺的資訊和進行管理。
因此 2017 年我們經過調研與測試業界主流的一些統一的平臺管理方案,目標是提高叢集的穩定性、易管理性、安全性,在對 CDH、Ambari 等作競品分析後,我們選擇了 Ambari 這個 Hortonworks 貢獻給 Apache 的頂級開源專案。
選擇的原因總體來說主要有:
-
Ambari 是 Hortonworks 貢獻給 Apache 開源社群的頂級專案,屬於 Hadoop 生態中的重要組成部分,Hortonworks 本身也提供一些基於 ApacheHadoop 開發良好的商業應用元件,例如 HDP 資料平臺。
-
Ambari 不僅整合了常用的運維管理工具,更重要的本身專注於 Hadoop 叢集管理方案,所以它的優勢就在於 Hadoop 叢集的供應、管理和監控等,最能解決我們的需求痛點。
-
Ambari 基於 Web 的特點能夠直現給使用者直觀使用者介面,能夠極大提升管理效率和降低本身開發成本。
因此,我們基於 Ambari 摸索了一套接管線上 Hadoop 叢集(下文中 Hadoop 遊戲資料叢集將簡稱為 Hadoop 叢集)的技術方案併成功實踐之,如同 Ambari 從零供應一個叢集一樣,將基於 Web 的 Ambari 充分利用在了對叢集的管理與監控上。
生產環境中 Hadoop 叢集現狀
首先介紹我們生產環境中 Hadoop 叢集的現狀,Hadoop 叢集主要承擔了資料接入儲存、離線計算的職責,同時提供其上資料排程等自研系統的基礎服務。生產環境中 Hadoop 使用的版本是 v2.7.3,下面介紹其主要元件。
首先 HDFS 採用了 HA with QJM 的高可用架構,即採用 Standby Namenode 熱備、多節點協同同步 Active/Standby Namenodes(不同物理機器)之間元資料日誌的方式,降低之前單點 Namenode 因為故障而導致的叢集服務不可用的時間,提高叢集的可用性。
並且如下圖中,Active/StandBy Namenode 節點各自運行了基於 Zookeeper 叢集自動監控 Namenodes 狀態、自動選舉保證叢集 Namenode 只有一個處於 Active 狀態的 ZKFailoverController。

圖 1 HDFS HA with QJM
接著是用於叢集資源分配與作業排程的 Yarn 框架,我們採用了 Yarn 的 FairScheduler 公平排程策略,並且根據不同業務線叢集使用成本投入佔比,劃分了作業執行佇列以及佇列使用的資源池,各個資源池合理定義了最大同時執行作業數、Min/Max 可參與分配的資源(Vcore 數、mem 大小)、動態競爭其他空閒佇列資源池資源權重等引數。
除開業務線使用的各佇列之外,還定義了 Default 的共享作業佇列,分配其較小的資源用於保證其他一些例如叢集資料的共享查詢等應用。

圖 2 YARN FairScheduler 資源分配圖
叢集 ETL 離線作業處理與資料查詢我們主要基於 Hive,Hive 是 SQL on Hadoop 的資料倉庫工具,具備良好的類似以關係型資料庫的方式儲存管理接入資料、提供對外資料處理介面特性,以 Hive 為基礎我們打造了大資料中心,安全、簡潔、便捷地統一接入資料以及對外統一提供資料處理基礎服務。
在這裡我還是要推薦下我自己建的大資料學習交流qq裙: 957205962, 裙 裡都是學大資料開發的,如果你正在學習大資料 ,小編歡迎你加入,大家都是軟體開發黨,不定期分享乾貨(只有大資料開發相關的),包括我自己整理的一份2018最新的大資料進階資料和高階開發教程,歡迎進階中和進想深入大資料的小夥伴
並且在發展過程中,為了提高資料中心服務水平,我們將 Hive 版本升級至 v2.1,其 HiveServer2 服務能夠更好支援併發和身份認證以及開放 API 客戶端(如 ODBC 和 JDBC),且其更好支援記憶體計算(TEZ+LLAP)也為後續升級提供了基礎。

圖3 Hive 2.1 應用架構圖
除開上述主要介紹的 Hadoop 叢集中元件應用之外,我們還有包括 Flume+Kafka 分散式日誌採集與佇列資料分發的完整資料流架構,該架構使用 Zookeeper 叢集做協同服務和配置管理,在這裡不一一贅述。
最後是 Hadoop 叢集原有的監控和告警邏輯,在程序監控這塊我們採用 Crontab 週期性從主控節點 ssh 至叢集每個節點,輪詢檢查每個主要程序的執行狀況,一旦發現程序掛掉則告警且重新啟動;在效能監控這塊(例如 Yarn 任務堆積數)我們也是採用 Crontab 週期性的調元件監控介面獲取相關 Mertrics 數值,告警異常值的方式。
至此我們已經梳理完畢生產環境中 Hadoop 叢集現狀,其上支撐的業務之廣、使用人之多,就決定了我們 Ambari 線上接管叢集不容有失,且需要最大限度降低接管過程中對業務造成的影響。
Ambari 相關技術介紹
接下來我們將簡單介紹 Apache Ambari 相關技術,Ambari 是 Hortonworks 貢獻給 Apache 開源管理 Hadoop 叢集的頂級開源專案上文已提及,主要用於 Hadoop 叢集的部署、監控與告警,Ambari 整體架構如下圖,主要由 5 部分組成:

圖 4 Ambari 整體架構圖
-
Ambari Web: 使用者互動介面,通過 HTTP 傳送使用 Rest Api 與 Ambari Server 進行互動。
-
Ambari Server: Web 伺服器,用於和 Web、Agent 進行互動並且包含了 Agent 的所有控制邏輯,Server 產生的資料儲存在 DB 中。
-
Ambari Agent: 守護程序,主要包含節點狀態與執行結果資訊彙報 Server 以及接受 Server 操作命令的兩個訊息佇列。
-
Host: 安裝實際大資料服務元件的物理機器,每臺機器都有 Ambari Agent 服務與 Metrics Monitor 守護程序服務。
-
Metrcis Collector: 主要包括將 Metrics Monitor 彙報的監控資訊儲存到 Hbase,以及提供給 Ambari Server 的查詢介面。
Ambari 整體管理叢集方面以 Ambari Server 為核心,維護著一個 FSM 有限狀態機,包含平臺中所有部署 Agent 並註冊的節點、部署的服務與元件的狀態變化資訊、配置檔案並且持久化在 Ambari Server 端的 DB 中。
對外一方面通過 rest Api 介面方式與 Ambari Web 互動,一方面接受來自 Agent 的定時心跳請求,所有互動資訊中包含了節點狀態、事件資訊、動作命令中其中至少一種,由 Ambari Server 統一協調命令和維護狀態結果,然後給 Agent 下發的相關 command,Ambari Agent 接受命令執行相關邏輯並返回狀態結果。
Ambari 整體監控方面通過 Ambari Server 獲取 Ambari Metrics Collector 中聚集後的從各個節點 Ambari Metrics Monitor 上報的單節點監控指標資料,在 Ambari Web 中給出圖形化的展示。
Ambari 是 HDP 資料平臺套件的一部分,HDP 是 Ambari 管理叢集的技術棧基礎。HDP 即 Hortonworks Data Platform,是 Hortonworks 完全開源以 Yarn 為核心整合 Apache Hadoop 技術的一個安全的企業級資料平臺,HDP 涵蓋了幾乎所有 Hadoop 的資料離線處理技術,以及最新的實時處理技術滿足使用者需求,如下圖所示,其 2017 年開源的 HDP v2.6 正好支援 Hadoop v2.7.3。

圖 5 HDP 資料平臺技術涵蓋
Ambari 支援對 HDP 的供應或者說 Ambari 基於 HDP 資料平臺,下面是幾個核心概念:
-
Stack:Ambari 支援管理的 HDP 整個技術棧,本身技術棧也有版本區分,例如 HDP 2.6 就是 Hortonworks 基於 Apache Hadoop v2.7.3 與 Apache 協議的 2017 年發行版。
-
Service:Ambari 支援管理的某個具體服務,比如 HDP 中的 HDFS、Yarn 等,可以部署、管控的一個完整 Framework 技術方案。
-
Component:Ambari 支援管理的最小元件單位,由於 Service 服務大多數為分散式應用,Componet 即細分為 Master、Slave、Client 等元件。
Ambari 按照 Stack -> Service -> Component 的層次關係,管理著 HDP 之間各元件依賴關係,通過 Service Metainfo 的定義來管理元件的依賴管理配置。
例如 Yarn 的metainfo.xml 檔案中定義了 Yarn 需要 HDFS 和 MR2 的支援,配置檔案依賴 Hadoop 的主要配置檔案 core-site、hdfs-site 等。
其中 HDFS、MAPREDUCE2 為 Ambari 管理的 Service,而 HDFS 中每一個執行例項,例如 Namenode、DataNode 為 Ambari 管理的 Component。
Ambari 接管線上 Hadoop 叢集問題與思路
上文中已提及在 Ambari 接管線上 Hadoop 叢集時,需要主要考慮兩方面的問題:
-
Ambari 接管之後怎樣保證叢集依舊能夠支撐原先支撐的所有上層應用。
-
Ambari 接管動作怎樣降低對線上 Hadoop 叢集提供服務的影響。
問題描述
圍繞上述這兩方面,首先我們梳理了叢集上支撐系統的所有使用介面,包括排程系統中使用的 HDFS RestApi,資料中心使用的 Hive Jdbc、ThriftApi,實時採集和分發系統使用的 Zookeeper 服務。
其中涉及到的主要技術元件例如 HDFS、Hive、Zookeeper,HDP 中各元件的版本應該向下相容最好版本一致(Hadoop v2.7.3、Hive 2.1.0 等等),保證功能特性滿足。
根據 HDP 提供的元件資訊,我們選擇了 HDP v2.6.0.2,並且針對 HDP v2.6 對其包含的元件功能特性與社群版各元件功能特性進行對比,確保了 HDP v2.6.0.2 支援現有所有功能特性。
然後是支援 HDP v2.6.0.2 作為 Stack 的 Ambari v2.5.1.0,接下來是確定 Ambari v2.5.1.0 管理 HDP v2.6.0.2 下的各個 Service 可行性:

圖6 HDP-2.6.0.2 與 Hadoop - 2.7.3 各 Service 版本對比
從上面的對比圖中可以發現,Ambari 是支援管理大多數與線上叢集元件版本一致的元件的。
在這裡我還是要推薦下我自己建的大資料學習交流qq裙: 957205962, 裙 裡都是學大資料開發的,如果你正在學習大資料 ,小編歡迎你加入,大家都是軟體開發黨,不定期分享乾貨(只有大資料開發相關的),包括我自己整理的一份2018最新的大資料進階資料和高階開發教程,歡迎進階中和進想深入大資料的小夥伴
但是也有例外,例如 Hive,Ambari 支援管理的版本比線上叢集中的低,而我們生產環境中資料中心等上層應用都是基於 Hive 2.1.0 介面執行的。
所以 Ambari 接管線上叢集不得不解決Hive的相容性問題,才能最終達到 Ambari 管理為我們所用的生產叢集的目標。
接著需要考慮的是 Ambari 自動供應的 HDP 叢集怎樣與線上 Hadoop 叢集相容,就拿其中比較重要的一個必要條件來說:接管後的 HDP HDFS 能夠唯一管理線上已有叢集資料,而要能夠順利實現這一目標就得 Ambari 管理的 HDP 能夠代替原有 Hadoop 叢集。
所以 Ambari 接管線上叢集的問題就轉化成了叢集升級的問題,升級問題要考慮的是最小化停機的影響以及能夠回滾恢復,以及充分利用 Ambari 的特性。
解決思路
現在已經瞭解到了此次 Ambari 接管線上叢集的問題,我們來說說解決上述問題的思路。首先是 Ambari 管理元件相容性問題,以 Hive 元件為例,雖然 Ambari v2.5.1 在管理方面只支援 Hive v1.2.1,但是作為整個 HDP v2.6.0.2 提供的技術元件中包含了 Hive v2.1.0(見圖 5)。
Hive v2.1.0 元件的保留是為了相容 Hive2 包括 LLAP、CBO 等一系列新功能,在 Ambari 部署 Hive 元件時,會分為 Hive v1.2.1 與 Hive v2.1.0 兩個版本同時部署,下圖中通過主要 jar 包報名版本號可以看出,HDP 功能元件根目錄的 hive 與 hive2 子目錄分別為 Hive v1.2.1、Hive v2.1.0 元件根目錄。

圖 7 HDP 中 hive 與 hive2 功能版本對比
Ambari 部署 Hive 完畢後,接下來是生成配置與元件啟動邏輯,而 Ambari 預設是支援 Hive v1.2.1 即配置生成與啟動時針對的是 hive,那麼我們需要調整的目標是讓它針對 hive2。
回顧 Ambari 執行邏輯,完整的一次互動是使用者在 Ambari Web 介面操作 -> Ambari Server 請求處理&命令下發具體機器 -> 具體機器 Ambari Agent 執行相關操作,而在這裡 Ambari Agent 啟動 Hive(實際分為 HiveMetaStore、HiveServer、HiveClient 等 Component,每個 Component 啟動執行邏輯一致,故在這裡統一稱為啟動 hive)過程包括瞭解析下發命令、從 DB 拉取配置資訊、更新配置檔案、啟動 Hive。
因為配置檔案對於各個 Hive 中 Component 一致,所以更新配置檔案的執行邏輯也一致,並且 hive2 是能夠向下相容 hive 中的所有配置項的,因此在更新 hive 配置檔案的邏輯最後增加同步配置至 hive2 配置的功能,就實現了在 Ambari Web 頁面也能夠更新本不支援的 hive2 的配置了,並且因為 Ambari 有自定義配置項功能支援所以也不用擔心 hive2 配置項 hive 中不支援的問題。

圖 8 hive 更新配置增加同步至 hive2 功能
配置支援的問題解決了,然後是 Hive 啟動的問題,啟動邏輯更加簡單即預設以 hive/bin 目錄下啟動指令碼啟動相關元件之前會嘗試去獲取機器的 HIVE_HOME 系統環境變數,所以在節點提前配置 hive2 的相關係統環境變數,則啟動邏輯會以 hive2/bin 目錄下的啟動指令碼啟動相關元件,同樣的關閉、重啟等邏輯也會按照 hive2 的邏輯執行。
至此通過類似”移花接木”的方式實現了 Ambari 管理 Hive v2.1.0 的目標,即在 Ambari Web 頁面上的管理操作的生效物件為 HDP Hive2 即 Hive v2.1.0。
接著是 Ambari 接管線上叢集如何轉化成線上升級,叢集升級中的要點包括:舊版本元資料的備份(Namenode、Journalnodes 等),舊版本配置在新版本配置的覆蓋和調優,可能升級失敗的回滾方案准備,實施升級時段選在叢集使用空閒時間,升級前的演練等。
這些方案此次 Ambari 接管線上叢集升級同樣受用,但是同時也要考慮一些特殊的細節:第一,Ambari 支援的 Hadoop 叢集供應並沒有直接 HA with QJM 的方案,在 HDFS 部署時必須按照 SNN 冷備方案部署然後調整為 HA with QJM 的步驟。
第二,叢集中的 Zookeeper 服務支援的一些實時型業務就決定了 Zookeeper 服務不能與 Hadoop 升級那樣需要停機而造成服務不可用的空窗期。
第三,Ambari 管理的元件程式執行 role 與現有元件程式執行 role 的不同導致的主要包括檔案許可權等問題,以及由於此前 Hadoop 叢集經歷過節點擴容、節點配置個性化差異如何在 Ambari 統一配置管理中避免衝突的問題。
而且我們需要保證的目標包括了:
-
架構上與原有叢集一致,比如 nn 節點、dn 節點的分佈等,儘可能與原有叢集元件機器分配一致。
-
升級最重要的是我們的資料資產,資料不能丟,所以重要配置比如 hdfs 各儲存日誌檔案目錄、索引檔案目錄等等必須一致。
-
再就是各元件重要引數,比如服務名稱空間、檔案塊大小、資源排程策略等等,也要儘可能一致。
所以綜上所述,我們將 Ambari 接管線上叢集升級拆分為下面幾大步驟:
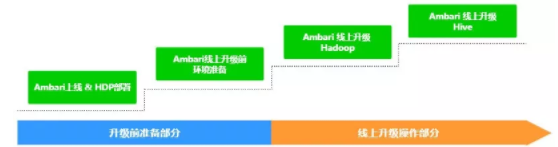
圖9 Ambari 接管線上叢集升級步驟
在升級前的準備部分中將把所有的相關資源提前部署以及配置好,線上升級操作部分中只操作 Ambari 啟動相關元件,完成線上叢集執行元件的替換,所以叢集停機影響時間縮短至 Hadoop、Hive 相關啟動的時間,最大化減小了停機的影響。
升級前準備工作主要分為兩個部分:第一,按照 Ambari 官網提供的部署方式部署並啟動 Ambari 各元件,然後在 Ambari Web 上按照 Ambari Cluster Install Wizard 並且根據線上現有叢集的元件分佈,選擇相應 HDP 元件的部署節點,確保將 HDP 各元件部署節點與線上叢集各元件執行節點保持一致後,Ambari 將會在各節點 Install HDP 的各元件,最後由於節點已有執行元件的埠衝突會導致 Start 失敗,不過不影響 Ambari 成功完成部署 HDP 各元件。
第二,Ambari 線上升級前環境準備首先最重要的是與現有叢集的配置同步,同樣在 Ambari Web 介面中操作,這裡需要注意的是現有叢集不同節點的差異化配置在 Ambari 中使用 Config Group 同樣進行差異化配置,比如叢集中 DataNode 機器節點在磁碟上的差異情況,在 Ambari 中配置不同節點組對應的配置如下圖:

圖10 不同 DataNode 節點組 Blocks 目錄差異化配置
依次對 Hadoop、Hive 等元件完成配置同步;接著是準備所有執行邏輯指令碼,包括剛才提到的涉及到功能修改的相關 Ambari Agent python 功能指令碼以及升級上線操作時的包括備份 NN、JN 元資料、統一修改系統環境變數等命令指令碼,至此升級前的所有準備工作全部完成。
線上升級操作部分也分為兩部分:
第一,Ambari 線上升級 Hadoop,首先是 Zookeeper 叢集的升級,採用從 Zookeeper 的 follower 機器開始一臺一臺停掉線上、Ambari 啟動相應節點,因為在配置同步過,所以 Ambari 啟動的 zk 是讀取原有 zk 的資料,待所有 follower 節點操作完畢之後操作 leader 節點。
然後是 Hadoop 的升級,Hadoop 升級前暫時關閉所有程式訪問入口(提前公告通知),Hadoop 升級中最重要的是 Hdfs 的升級。Hdfs 的升級分為 SNN 冷備方案 HDFS 啟動與 Enable HA with QJM 兩步:
在這裡我還是要推薦下我自己建的大資料學習交流qq裙: 957205962, 裙 裡都是學大資料開發的,如果你正在學習大資料 ,小編歡迎你加入,大家都是軟體開發黨,不定期分享乾貨(只有大資料開發相關的),包括我自己整理的一份2018最新的大資料進階資料和高階開發教程,歡迎進階中和進想深入大資料的小夥伴
-
第一步讓原有叢集進入安全模式確保沒有資料寫入時,備份所有 Namenode、Journalnode 節點元資料,執行關閉叢集指令碼在確保 Hadoop 元件全部關閉後執行修改所有節點系統環境變數指令碼(修改為新 HDP 叢集的系統環境變數)。
根據 Ambari 中提示啟動 HDFS,由於 Namenode 重啟需要一定時間(在這裡不介紹 Namenode 重啟優化了),等待叢集 check blocks 直至自動退出安全模式後至此 SNN 冷備方案的 HDFS 正式啟動成功。
-
第二步在 Ambari 中操作 Enbale HA with QJM,每一步的操作根據操作指南即可,需要注意的是過程當中可能會出現原有的 Stand By Namenode 元資料缺少因為第一步中單 Namenode 執行過程中產生的部分元資料,可以同步 Namenode 中 fsimage 與 editLog 檔案至 Stand By Namenode 並重新 initializeShareEdits。
正常情況下在 Enable HA 最後 Ambari 又會重啟一次 HDFS,重啟完成之後至此 HDFS 升級完畢,依次啟動 Mapreduce2、Yarn 服務,整體 Hadoop 升級完畢。
第二,Ambari 線上升級 Hive,在第一部分 Hadoop 成功升級後相對來說 Hive 的升級比較容易,在更新 Hive Metastore 中相關元資料資訊(DBSCHEMA)之前首先對資料庫進行備份,更新 HiveMetaStore Schema、執行啟動 Hive 即可,因為已經部署了修改邏輯後的程式碼部分,Hive 將以 Hive v2.1.0 在線上提供服務。
上面四大步驟順利完成之後,Ambari 就成功接管了線上叢集,叢集支撐的上層服務可以開放入口給使用者使用了。後續圍繞 Ambari 的監控功能,使用其 api 介面可以定製各種個性化的監控和告警服務,至此 Ambari 成功接管線上叢集。
Ambari 接管線上 Hadoop 叢集實踐
上文中想必讀者已經瞭解了我們 Ambari 實踐最終想要達到的目標,其中存在的主要問題以及問題解決的思路,現在我們介紹 Ambari 接管線上 Hadoop 叢集的實踐過程。
因為此次 Ambari 接管線上 Hadoop 叢集動的是我們叢集或者說是大資料平臺的最底層,影響範圍大所以每個步驟環節我們都謹小慎微確保無誤,防止一丁點的疏忽導致整體大資料平臺崩盤的”蝴蝶效應”出現。
所以我們從開發叢集開始,目標是在使用 Ambari 從零搭建叢集過程中,瞭解其核心特性和對機器執行環境的所有依賴;然後是在我們 Hadoop 測試叢集上,Hadoop 測試叢集不僅有與生產 Hadoop 叢集同樣的環境與配置,並且也支撐著同樣的用於測試目的的上層應用系統。
在灰度叢集上我們按照上文中四步驟完整演練了較多次,總結了一些其中碰見的問題和應急解決方案,除開節點規模和資料量比不上線上 Hadoop 叢集之外,升級方案方面已經確定。
最後是使用在測試叢集中的上線方案,選擇恰當的時機在線上環境完整執行了一遍,Ambari 線上操作部分整體耗時控制在了 2h 以內,Ambari 接管後集群整體執行正常,支撐的上層應用無報錯。
下面將把 Ambari 接管線上 Hadoop 叢集實踐過程中的關鍵點著重講述,讓讀者瞭解接管升級實踐過程中需要關注的部分。
配置同步
Ambari 接管的目標是對於叢集使用者來說感受不到叢集本身的變化,所以能否接管線上叢集的關鍵點之一在於叢集配置的同步,準確點是說 Ambari 使用的 HDP 中各個 Component 元件系統引數、應用引數、執行時環境變數等都需要保持一致,下面將介紹幾個主要配置檔案中的重要配置項。
以下圖中的 HDFS core-site.xml 配置為例,core-site.xml 配置檔案是 HDFS 重要配置檔案之一,可以看見黃色標註部分為我們在 Ambari 線上升級 Hadoop HDFS 時分階段 fs.defaultFS 的不同配置:
第一步單點啟動時配置保證了單 Namenode 啟動的順利進行,到第二步 Enable HA 時,修改為 HA 時候的必要配置。
然後對於 Hadoop 叢集使用者來說,增加了 root、hive 使用者與使用者組的訪問也是為了相容 Ambari 接管後的 HDFS 執行 role 為 hdfs 使用者的訪問相容,當然只有許可權級別比較高的 root 和 hive 使用者能夠享有這個許可權。
接著是 Namenode 執行的最大記憶體大小等引數,Ambari 預設的都比較小,這一點需要特別注意根據原有叢集的執行 Namenode 程序執行時記憶體引數來調節這些引數。
然後再來看看 Yarn 相關的配置項,我們以 yarn-site.xml 配置檔案中主要配置項為例:橙色標註的部分為需要根據原有叢集做調整的部分,其中包括需要根據具體節點記憶體大小情況來合理選擇 NodeManager 可用於分配的最大記憶體,增加 mapreduce_shuffle 選項以支援叢集中的 MapReduce 程式。
當然還有 Yarn 的排程策略,在生產叢集環境介紹中已提到使用的是根據業務劃分的 FairScheduler,而 Ambari 中預設使用的是 Capacity Scheduler,所以需要特別注意排程策略以及相關的配置與原有保持一致。
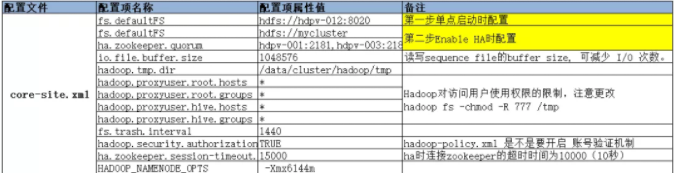
圖 11 HDFS core-site.xml 主要配置項

圖 12 Yarn yarn-site.xml 主要配置項
最後是一些元件的資料儲存路徑的配置,Ambari 能夠接管線上叢集,必須 HDP 各元件使用之前的資料來保證,所以資料儲存路徑的配置也是至關重要的。

圖13 主要元件的主要資料儲存路徑配置項
升級操作
在升級操作前,我們會關閉所有訪問叢集的應用入口,特別是叢集資料接入與定時作業這一塊,保證叢集沒有資料繼續寫入後,我們接著關閉所有之前的叢集程序運維監控指令碼,防止升級過程中原有叢集元件程序執行的恢復影響升級。
接著為了方便在 Namenode 統一執行關閉叢集操作,我們根據關停指令碼的邏輯即各節點會找到存放對應程序(Datanode、NodeManager)PID 檔案路徑,根據檔案記錄的 PID 執行 Kill 操作。
但是由於部分 PID 檔案存放在系統 tmp 資料夾下可能已經被刪除,所以我們提前在各個節點部署了檢查各自執行程序並還原可能缺失的 PID 檔案的指令碼,並且在正式關停前,統一執行還原程序 PID 檔案,NN、JN 節點元資料檔案資訊備份後才執行關停操作。
然後在 Ambari 升級 Hadoop 之前,我們通過 Hdfs 管理介面記錄系統的元資料資訊,並且在 Ambari 完成整體 Hadoop 升級後,我們詳細對比了 Hdfs 記錄的元資料資訊(下圖中選擇的為 Ambari 接管測試叢集的統計資料):

圖15 Ambari 接管測試叢集升級前後文件對比
在確定升級前後 Blocks 完全一致後,整體 Hadoop 升級確認完成。最後是 Ambari 升級 Hive,在步驟 2 叢集關停操作完成之後,我們同步進行了 Hive MetaStore DB 的備份,因為 HiveMetaStore DB 只儲存 Hive 相關元資料資訊,所以 hivemeta DB 本身不大,備份起來速度也較快。
在正式 Ambari Hive 升級之前,使用 SchemaTool 工具更新 hivemeta 庫,最後啟動 Hive。
在這裡我還是要推薦下我自己建的大資料學習交流qq裙: 957205962, 裙 裡都是學大資料開發的,如果你正在學習大資料 ,小編歡迎你加入,大家都是軟體開發黨,不定期分享乾貨(只有大資料開發相關的),包括我自己整理的一份2018最新的大資料進階資料和高階開發教程,歡迎進階中和進想深入大資料的小夥伴
我們在 Hadoop 與 Hive 升級啟動完畢之後,我們迅速使用命令指令碼模擬包括排程系統、資料中心等線上系統訪問叢集,測試新上線叢集對外介面的可用性,確保測試都通過後,我們正式開放了各個上層應用,至此整體的上線時間耗時控制在了 2h 以內,整體升級操作時間軸如下:

圖16 線上叢集升級各過程時間軸
後續運用
Ambari 接管線上集群后,在 Ambari Web 中可以對叢集中所有元件進行統一管理:

圖17 叢集元件操作介面
上圖中為叢集中元件列表,以 HDFS 為例,對於 HDFS 的操作列表中包括了對 NameNode、DataNode、JournalNode 等的常用操作,通過介面即可統一操作。

統一配置管理將不同的配置檔案分類給出,使用者根據相應的配置項屬性名填寫屬性值同步即可,使用者可自定義配置項,配置同步後有歷史版本概念,多版本之間可以對比。
Ambari Web 中將監控叢集捕獲到的關鍵操作指標值通過良好的 Widget 視覺化,幫助我們日常能夠快速排查和解決問題,在主動預防問題上面提高了不少效率。
例如我們通過觀察 Yarn Pending Apps 的個數,發現堆積比較嚴重的時段後,會合理去調整作業的執行時間;通過觀察叢集整體 CPU 與記憶體的利用率,可以快速定位叢集計算能力的瓶頸即 CPU 使用率較高但是記憶體使用率相對較低,然後我們會合理調整 Yarn 中 Container 對於 CPU 利用的策略等。

圖19 監控指標值視覺化
由於我們可以在統一的 Ambari Web 介面中對叢集元件進行操作、配置管理,基於 Ambari 叢集統一管理特性標準與規範化了叢集的運維管理操作,相應的操作例如增加刪除節點、元件遷移、配置修改等,都有明確的許可權範圍以及完整的操作歷史記錄,並且將 Ambari 所有使用者入口做統一管理,公司內部相關人員只能在許可權範圍內對叢集進行有跡可循的操作。

圖20 叢集管理者各角色許可權表
如上表將對於叢集的運維管理操作角色許可權分成四個 Level,最低的 Level 是能夠在 Ambari Web 中檢視叢集的執行狀態、配置、告警等資訊。
但是對於叢集沒有任何的操作許可權,此類許可權開放給所有需要對叢集執行健康狀態有關注的叢集使用者,例如可以在 Tez View 中檢視自己的作業執行情況,在 Yarn 管理介面中檢視負載等等。
然後在針對叢集可操作人群,同樣劃分了操作元件級別、叢集整體級別兩個 Level,一般的叢集運維人員可以去管理其中元件、進行調優,而上升到叢集統籌規劃這一層面,則需要對整體架構熟知的叢集架構人員去管理。
最後超級管理員除開上述所有許可權之外,多了一層 Ambari 本身系統級別的管理。
管理許可權按層級劃分,既能夠滿足不同叢集使用者的要求,同樣也保護了叢集的執行安全和穩定。
然後我們根據 Ambari 提供的監控功能開發了相應的配套處理程式,目的在於第一使用我們自己的告警系統去替代 Ambari 中不太友好的告警系統;第二充分利用 Ambari api 不僅實現告警而且能夠在故障出現時一定程度上嘗試自動恢復。提高我們在叢集監控、管理方面的效率。
在這裡我還是要推薦下我自己建的大資料學習交流qq裙: 957205962, 裙 裡都是學大資料開發的,如果你正在學習大資料 ,小編歡迎你加入,大家都是軟體開發黨,不定期分享乾貨(只有大資料開發相關的),包括我自己整理的一份2018最新的大資料進階資料和高階開發教程,歡迎進階中和進想深入大資料的小夥伴
首先 Ambari 提供了良好的 Restapi 用於與叢集的各種直接互動,下面我列舉一組 Restapi 示例:
http://ambari/api/v1/clusters/hdp/hosts/${host_name}/host_components/ZKFC
{
"RequestInfo": {
"context":"ReStart ZKFC",
"operation_level":{
"cluster_name":"hdp",
"host_name":"${host_name}",
"service_name":"HDFS"
}
},
"Body": {
"HostRoles": {
"state":"STARTED"
}
}
}
上述 URL 為典型的操作指定機器 ZKFC 程序的命令,如果 Http 動作是 GET 則返回該程序的狀態資訊,如果是 PUT 且增加 json 請求內容則是對 ZKFC 的一次具體操作,從 RequestInfo 中 context 的描述可以看出是對 ZKFC 的重啟操作,operation_level 描述了具體操作物件的資訊屬於哪個叢集哪個節點,以及 ZKFC 屬於 HDFS 服務的一個元件,最後 Body Host Roles 描述了 ZKFC 重啟操作後應該屬於啟動狀態。
介紹完了 Ambari 中的操作 API,我們利用 api 的特性設計了一套完整的自動發現元件疑似嚴重錯誤、確認錯誤並告警、嘗試恢復的功能配件。
完整邏輯圖如下:

定期掃描 dm_monitor_info,Ambari 中定義的告警項的週期掃描狀態,發現元件存在的最近一次的隱患,確認元件是否真正處於服務不可用的狀態(可能是叢集在維護即 maintainance_state=‘ON’)後,記錄該次告警資訊,週期性嘗試自動恢復正常之前告警系統報告訊息,直到恢復後最後一次向告警系統報告成功恢復訊息後,消除此次告警資訊。
根據上線後執行近半年的統計,累計自動恢復元件時間分佈如下圖,Ambari 中最小掃描週期為一分鐘,所以按照分鐘級別的掃描出疑似元件問題與自動恢復的平均時間在五分鐘之內,且絕大多數故障恢復在一分鐘,大大提高了元件的服務可用性。

後記
在 Ambari 接管線上集群后已經穩定運行了半年之久,它幫助我們大大提高了叢集管理、監控方面的效率,在幫助我們效能排查、科學調優方面給了很大的幫助。
當然 Ambari 管理與監控叢集只是大資料平臺基礎建設的第一步,在智慧化、企業級大資料平臺基礎建設過程中,我們會利用其提供的 HDP 平臺服務不斷提高大資料平臺基礎服務水平。