
排序比較之歸併排序與快速排序
異同點:
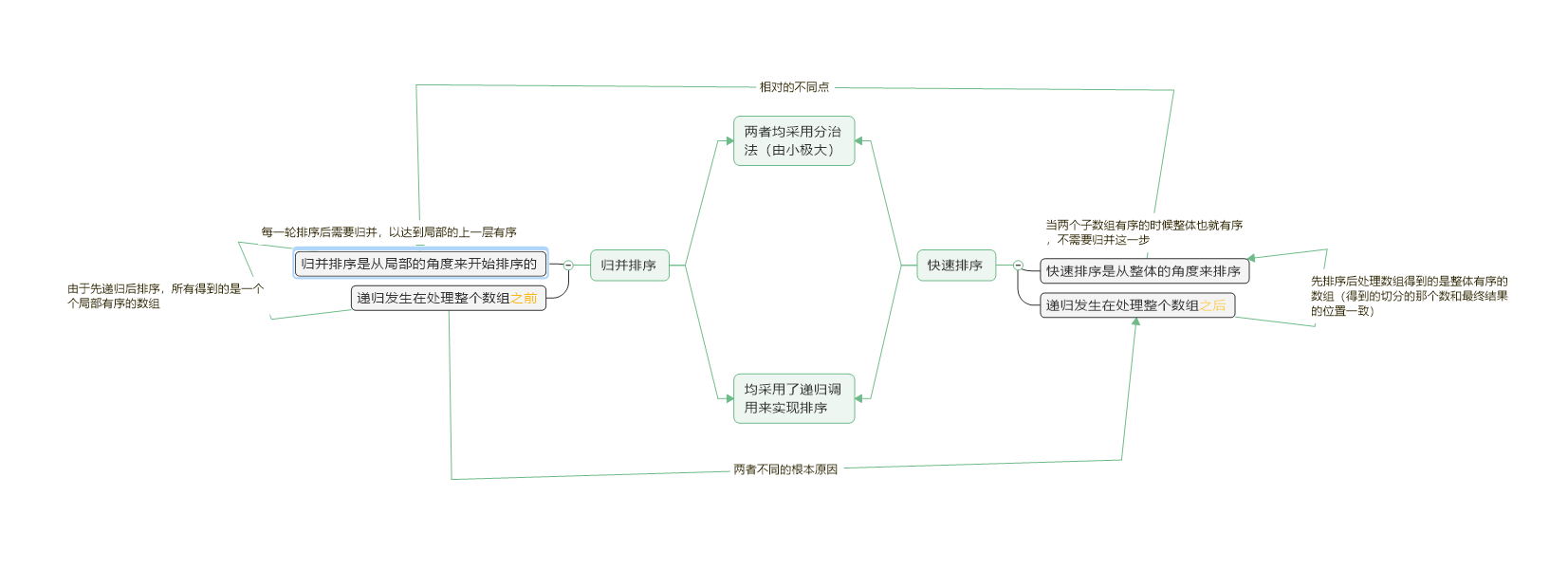
雖然在於演算法的區別主要在於遞迴實現的時機不同,在一些細節上也有著一些區別:
快速排序:
進行選擇排序的時候,如果一輪還沒有排序結束,會暫時將比中心值小的數放在緊挨著中心值的右邊,並設定一個遊標來控制這些數的下標,每找到一個小於的數就將遊標的值加一換到下一個,直到一輪排序結束後,再將中心值和此時的遊標交換位置,以達到左邊的數字小於遊標的值,此時再用遞迴的方法排序左邊的值或者右邊的值。
歸併排序:
對於歸併排序來說 會將陣列先劃分再排序,先會劃分一小段將一小段排序,當有序後會排序下一小段,兩個都為有序的時候,會將這兩個歸併,就是將兩個有序的數組合併為一個有序的陣列(注意,這種是自頂向下的排序方法) 而自底向上的方法則是分組後將每小組都排為有序的,再兩兩一排序,得到最後的整體有序
以上為個人觀點,歡迎討論批評··
相關推薦
排序比較之歸併排序與快速排序
異同點: 雖然在於演算法的區別主要在於遞迴實現的時機不同,在一些細節上也有著一些區別: 快速排序: 進行選擇排序的時候,如果一輪還沒有排序結束,會暫時將比中心值小的數放在緊挨著中心值的右邊,並設定一個遊標來控制這些數的下標,每找到一個小於的數就將遊標的值加一換到下一個,直到一輪排序結束後,再將中
歸併排序和快速排序比較【演算法設計與分析實驗報告】
下面的原始碼是修改的了時間差精確到了納秒級別的了,但是還是感覺很有誤差。無論怎麼測,總是快排比歸併快,即使是測試資料的陣列長度在10以內。 前面一樣的程式寫的是時間精確到微秒級的,陣列長度大概在一萬以內的,就是歸併排序快了,大於這個長度的快速排
C++ 歸併排序與快速排序
歸併排序: 【演算法邏輯】 歸併的思路(分治)是把一個大問題a拆解成兩個小問題b和c,解決了兩個子問題再整合一下,就解決了原問題。用遞迴的方法,先分解再合併(分治是一種解決問題的處理思想,遞迴是一種程式設計技巧,這兩者並不衝突): 【程式碼實現】 #include<io
python 歸併排序 與 快速排序 速度對比
import time def merge(list,first,mid,last): left = list[first:mid+1] right = list[mid+1:last+1] while left != [] and right !=[]:
歸併排序與快速排序
歸併排序 歸併的思想在於先分後排; “先分”:把整個序列劃分為一個一個單段(O(logn)) “後排”:將相鄰段內資料按照順序放入新的陣列,最後再將新陣列的資料放回原陣列(O(n)) 由此總的時間複雜度為二者乘積=O(n*logn) Code #include
氣泡排序與快速排序比較
} 例子為從小到大排序, 原始待排序陣列| 6 | 2 | 4 | 1 | 5 | 9 | 第一趟排序(外迴圈) 第一次兩兩比較6 > 2交換(內迴圈) 交換前狀態| 6 | 2 | 4 | 1 | 5 | 9 | 交換後狀態| 2 | 6 | 4 | 1 | 5 | 9 | 第二次兩
Java語言描述:遞迴與分治策略之合併排序與快速排序
合併排序: package DivideAndConquer; public class MergeSort { //一定要多傳入一個多餘的temp陣列用於存放排序的中間結果 public static<AnyType extends Comparable&l
十大經典排序之希爾排序與快速排序
希爾排序與插入排序的區別 1.希爾排序沒有插入排序穩定 eg: 當陣列為[5,4,6,7,4]時,希爾排序會將第二個4的排序到第一個4之前,所以不穩定,但插入排序不會 2.當希爾排序排到增量為1時,就和插入排序類似 個人理解:巨集觀上希爾排序和插入排序的思想類
php冒泡排序與快速排序實例詳解
lag ++ function 開始 ret light 記錄 php冒泡排序 php $a=array(‘3‘,‘8‘,‘1‘,‘4‘,‘11‘,‘7‘); print_r($a); $len = count($a); //從小到大 for($i=1;$i<$le
Java 冒泡排序與快速排序的實現
基於 amp 可能 ava 放置 jpg end images ati 冒泡排序 基本特點 (1)基於交換思想的排序算法 (2)從一端開始,逐個比較相鄰的兩個元素,發現倒序即交換。 (3)一次遍歷,一定能將其中
常見排序演算法之歸併排序
文章目錄 常見排序演算法之歸併排序 原地歸併方法 自頂向下的歸併排序 自底向上的歸併排序 特點 複雜度分析 參考資料 常見排序演算法之歸併排序 原地歸併方法 該方法將兩個不同的
c#程式碼實現排序演算法之歸併排序
歸併排序的平均時間複雜度為O(nlogn),最好時間複雜度為O(nlogn),最壞時間複雜度為O(nlogn),空間複雜度為O(n),是一種穩定的演算法。 1.將待排序序列r(1),r(2),…,r(n)劃分為兩個長度相等的子序列r(1),…r(n/2)和r(n/2+1),…,r
排序演算法之 歸併排序
這一篇要總結的是歸併排序,這也是七大排序的最後一種排序演算法。 首先來看一下歸併排序(Merge Sort) 的基本原理。它的原理是假設初始序列有n個元素,則可以看成是n個有序的子序列,每個子序列的長度為1,然後兩兩歸併,得到n/2個長度為2或1的有序子序列;再兩兩歸併,…
排序演算法之歸併排序(關鍵詞:資料結構/演算法/排序演算法/歸併排序)
假定:有 1 個亂序的數列 nums ,其中有 n 個數。 要求:排好序之後是 從小到大 的順序。 歸併排序演算法 程式碼 def merge(a, b): res = [] A = 0 B = 0 while A<len(a) and B<len(b
排序演算法之——歸併排序(兩種方法及其優化)
1 public class MergeX implements Comparable<Merge> {// 歸併排序(優化後) 2 private static Comparable[] aux; 3 4 private static boolean less(C
排序演算法之歸併排序MergeSort
排序演算法之歸併排序 歸併排序的主要思想為:分治法 即將問題分解為本質相同的若干個分問題,通過對分問題的求解,達到對總問題求解的目的。中間會用到程式設計中的一個重要思想—遞迴思想。 現在假設給定一個無序的長度為n的陣列 我們可以取陣列的中間值mid 然後我
排序演算法之歸併排序
歸併排序 歸併排序(MergeSort)是建立在歸併操作上的一種有效的排序演算法,該演算法是採用分治法(Divide and Conquer)的一個非常典型的應用。 分治法,也可以稱為分治策略:是將一個大規模的問題(原問題)劃分成n個規模
白話經典算法系列之七 堆與堆排序
堆排序與快速排序,歸併排序一樣都是時間複雜度為O(N*logN)的幾種常見排序方法。學習堆排序前,先講解下什麼是資料結構中的二叉堆。二叉堆的定義二叉堆是完全二叉樹或者是近似完全二叉樹。二叉堆滿足二個特
java實現排序演算法之歸併排序(2路歸併)
歸併排序:“歸併”的含義就是將兩個或兩個以上的有序表合併成一個新的有序表,假定待排序表含有n個記錄,則可以看成是n個有序的子表,每個子表的長度為1,然後兩兩歸併,得到n/2個長度為2或1的有序表,然後在兩兩歸併,如此重複,直到合併成一個長度為n的有序表為止,這就是2路歸併
資料結構排序演算法之歸併排序(c語言實現)
博主身為大二萌新,第一次學習資料結構,自學到排序的時候,對於書上各種各樣的排序演算法頓覺眼花繚亂,便花了很長的時間盡力把每一個演算法都看懂,但限於水平有限,可能還是理解較淺,於是便將它們逐個地整理實現出來,以便加深理解。 歸併排序就是通過將一個具有n個key記錄的線性表,看