
Unsupervised Single Image Deraining with Self-supervised Constraints論文閱讀
原文連結:https://arxiv.org/pdf/1811.08575.pdf
文中提到以往的無監督方法因為沒有對應的ground truth來計算mse約束生成影象,因此會產生一些artifacts,還有就是以往的影象轉換任務都是one to one 的transform,而雨的不確定性太多,有很多不同的視覺表現。因此文中提出了self-supervised的約束方法,如圖:
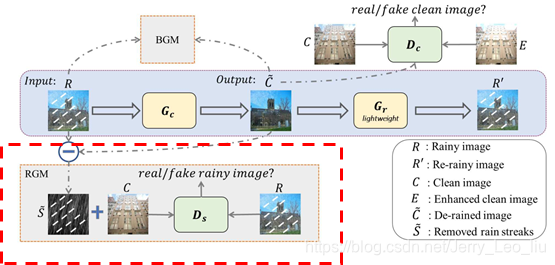
輸入帶雨的圖片R到生成網路Gc 中生成區域之後的圖片C’,再R-C’得到雨層S’,再將其與真實的乾淨影象結合,合成帶雨的圖片與真實的帶雨的圖片輸入到鑑別器Ds中讓它去鑑別哪個是真的雨,哪個是合成的雨。
![]()
![]()
BGM中將輸入影象R和生成圖C’ 分別加不同程度的高斯模糊之後來求平均梯度差(average gradient error)約束使得生成圖保留住背景內容。
![]()
同時也用了一個輕量級網路Gr來反向生成帶雨的圖片約束生成圖中保留住需要保留的資訊。
![]()
因為參考的不帶雨影象可能是晴天拍攝的,所以會生成雨天亮度相符的生成影象,因此文中又加了鑑別器Dc,使得生成圖與真實不帶雨的影象更接近的同時也約束了生成圖的亮度。C為真實的不帶雨的圖,E為對C做了亮度提升的圖。

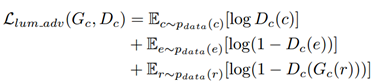
最後的總的loss:
![]()
w1,w2,w3,w4分別為1,5,1,0.5
相關推薦
Unsupervised Single Image Deraining with Self-supervised Constraints論文閱讀
原文連結:https://arxiv.org/pdf/1811.08575.pdf 文中提到以往的無監督方法因為沒有對應的ground truth來計算mse約束生成影象,因此會產生一些artifacts,還有就是以往的影象轉換任務都是one to one 的transform,而雨的不確定性太
《System Service Call-oriented Symbolic Execution of Android Framework with Applications to...》論文閱讀筆記
System Service Call-oriented Symbolic Execution of Android Framework with Applications to Vulnerability Discovery and Exploit Generation 用於Andro
acl2018---Aspect Based Sentiment Analysis with Gated Convolutional Networks論文閱讀筆記
Abstract 基於Aspect的情感分析(ABSA)能提供比一般情感分析更詳細的資訊,因為它旨在預測文字中給定的aspect或實體的情感極性。我們把以前的工作總結為兩類:aspect分類情感分析(aspect-category sentiment analysis (
Self-Supervised Learning for Stereo Matching with Self-Improving Ability
首先呢,這是一個非監督演算法,因此它約束的方式就是左右一致性檢測,用warp來處理左右圖,詳見3.1。作者聲情並茂的講述自己就是不要gt。。 網路結構 五部分組成 特徵提取 交叉特徵向量融合 3D特徵匹配 soft-argmin 最後通過影象warp來做約束。 特徵提取
文獻閱讀:SRFeat: Single Image Super-Resolution with Feature Discrimination
文章地址: http://openaccess.thecvf.com/content_ECCV_2018/html/Seong-Jin_Park_SRFeat_Single_Image_ECCV_2018_paper.html 作者的專案地址:SRFeat-Tensorlayer 1 簡
[CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks論文筆記
sed pooling was 技術分享 sco 評測 5.0 ict highest p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 15.0px "Helvetica Neue"; color: #323333 } p.p2
2018_CVPR_Interactive Image Segmentation with Latent Diversity
步驟 inter 設計 IE 表示 AR ack per ID 基本信息 CVPR 2018 作者主頁李著文 Interactive Image Segmentation with Latent Diversity 筆記 主要研究內容是交互式圖像分割。偏重於圖像編輯應用領
Note_Fast Image Processing with Fully-Convolutional Networks
ID 耗時 cal CQ 觀測 缺點 conf 有監督 tun 基本介紹 ICCV 2017 Fast Image Processing with Fully-Convolutional Networks 筆記 作者想建立一個神經網絡模型去近似一些圖像裏的操作,比如圖像風
論文閱讀計劃2(Deep Joint Rain Detection and Removal from a Single Image)
rem 領域 深度學習 conf mage 圖片 多任務 RoCE deep Deep Joint Rain Detection and Removal from a Single Image[1] 簡介:多任務全卷積從單張圖片中去除雨跡。本文在現有的模型上,開發了一種多
論文閱讀筆記《The Contextual Loss for Image Transformation with Non-Aligned Data》(ECCV2018 oral)
github 區域 偏移 org nbsp 修改 transfer style 但是 目錄: 相關鏈接 方法亮點 相關工作 方法細節 實驗結果 總結與收獲 相關鏈接 論文:https://arxiv.org/abs/1803.02077 代碼:https://
論文閱讀筆記 DeepLabv1:SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
bar pro 依賴性 後處理 主題 處理 分配 位置 平滑 論文鏈接:https://arxiv.org/abs/1412.7062 摘要 該文將DCNN與概率模型結合進行語義分割,並指出DCNN的最後一層feature map不足以進行準確的語義分割
論文閱讀1《AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networ》
paper連結https://arxiv.org/abs/1711.10485, code連結https://github.com/taoxugit/AttnGAN, 作者的homepage https://sites.google.com/view/taoxu 本文給出的是CVPR 2
【論文翻譯】中英對照翻譯--(Attentive Generative Adversarial Network for Raindrop Removal from A Single Image)
【開始時間】2018.10.08 【完成時間】2018.10.09 【論文翻譯】Attentive GAN論文中英對照翻譯--(Attentive Generative Adversarial Network for Raindrop Removal from A Single Imag
Single Image Reflection Removal
以下分析來源:Seeing Deeply and Bidirectionally: A Deep Learning Approach for Single Image Reflection Removal 這篇文章說它提出了級聯深度神經網路(cascade deep netural net
深度補全(Single-Image Depth Perception in the Wild)
Single-Image Depth Perception in the Wild arXiv:1604.03901v2 [cs.CV] 6 Jan 2017 Abstract 本文研究了戶外的深度感知,即從無約束設定下單個影象恢復深度。本文介紹了一種新的戶外資料集深度,由戶
Single Image Haze Removal 影象去霧 -CVPR 09 Best Paper
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
《Detecting Text in Natural Image with Connectionist Text Proposal Network》論文閱讀之CTPN
前言 2016年出了一篇很有名的文字檢測的論文:《Detecting Text in Natural Image with Connectionist Text Proposal Network》,這個深度神經網路叫做CTPN,直到今天這個網路框架一直是OCR系統中做文字檢測的一個常用網路,極大
Local Laplacian Filters : Edge-Aware Image Processing with a Laplacian Pyramid
Abstract 因為它是由空間不變的高斯核構造的,所以拉普拉斯金字塔被廣泛認為不適合表示邊緣,以及進行邊緣感知操作。 在本文中,我們展示了使用標準拉普拉斯金字塔的最先進的邊緣軟體處理。 我們使用畫素值上的簡單閾值來表徵邊緣,這使我們能夠區分大規模邊緣和小規模細節。 我們
How to detect and extract forest areas in a aerial image map with the knowledge of DIP
Signal processing is a common subject in electrical engineering, communication engineering and mathematics that deals with analysis and processing
image caption筆記(四):Image Captioning with Semantic Attention
文章來自cvpr2016 image caption常見的方法包括top-down和bottom-up。Top-down直接做影象到文字的端到端學習,而bottom-up先抽取出一些關鍵詞,