Spark學習筆記(1)—— Spark 介紹,叢集安裝
1 Spark 介紹
Spark是一種快速、通用、可擴充套件的大資料分析引擎,2009年誕生於加州大學伯克利分校AMPLab,2010年開源,2013年6月成為Apache孵化專案,2014年2月成為Apache頂級專案。目前,Spark生態系統已經發展成為一個包含多個子專案的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子專案,Spark是基於記憶體計算的大資料平行計算框架。Spark基於記憶體計算,提高了在大資料環境下資料處理的實時性,同時保證了高容錯性和高可伸縮性,允許使用者將Spark部署在大量廉價硬體之上,形成叢集。Spark得到了眾多大資料公司的支援,這些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、騰訊、京東、攜程、優酷土豆。當前百度的Spark已應用於鳳巢、大搜索、直達號、百度大資料等業務;阿里利用GraphX構建了大規模的圖計算和圖挖掘系統,實現了很多生產系統的推薦演算法;騰訊Spark叢集達到8000臺的規模,是當前已知的世界上最大的Spark叢集。
1.1 學習 Spark 的原因
中間結果輸出:基於MapReduce的計算引擎通常會將中間結果輸出到磁碟上,進行儲存和容錯。出於任務管道承接的,考慮,當一些查詢翻譯到MapReduce任務時,往往會產生多個Stage,而這些串聯的Stage又依賴於底層檔案系統(如HDFS)來儲存每一個Stage的輸出結果。 Spark是MapReduce的替代方案,而且相容HDFS、Hive,可融入Hadoop的生態系統,以彌補MapReduce的不足。
1.2 Spark 的特點
1.2.1 快
與Hadoop的MapReduce相比,Spark基於記憶體的運算要快100倍以上,基於硬碟的運算也要快10倍以上。Spark實現了高效的DAG執行引擎,可以通過基於記憶體來高效處理資料流。
1.2.2 易用
Spark支援Java、Python和Scala的API,還支援超過80種高階演算法,使使用者可以快速構建不同的應用。而且Spark支援互動式的Python和Scala的shell,可以非常方便地在這些shell中使用Spark叢集來驗證解決問題的方法。
1.2.3 通用
Spark提供了統一的解決方案。Spark可以用於批處理、互動式查詢(Spark SQL)、實時流處理(Spark Streaming)、機器學習(Spark MLlib)和圖計算(GraphX)。這些不同型別的處理都可以在同一個應用中無縫使用。Spark統一的解決方案非常具有吸引力,畢竟任何公司都想用統一的平臺去處理遇到的問題,減少開發和維護的人力成本和部署平臺的物力成本。
1.2.4 相容性
Spark可以非常方便地與其他的開源產品進行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作為它的資源管理和排程器器,並且可以處理所有Hadoop支援的資料,包括HDFS、HBase和Cassandra等。這對於已經部署Hadoop叢集的使用者特別重要,因為不需要做任何資料遷移就可以使用Spark的強大處理能力。Spark也可以不依賴於第三方的資源管理和排程器,它實現了Standalone作為其內建的資源管理和排程框架,這樣進一步降低了Spark的使用門檻,使得所有人都可以非常容易地部署和使用Spark。此外,Spark還提供了在EC2上部署Standalone的Spark叢集的工具。
2 Spark 叢集安裝
下載地址https://spark.apache.org/downloads.html
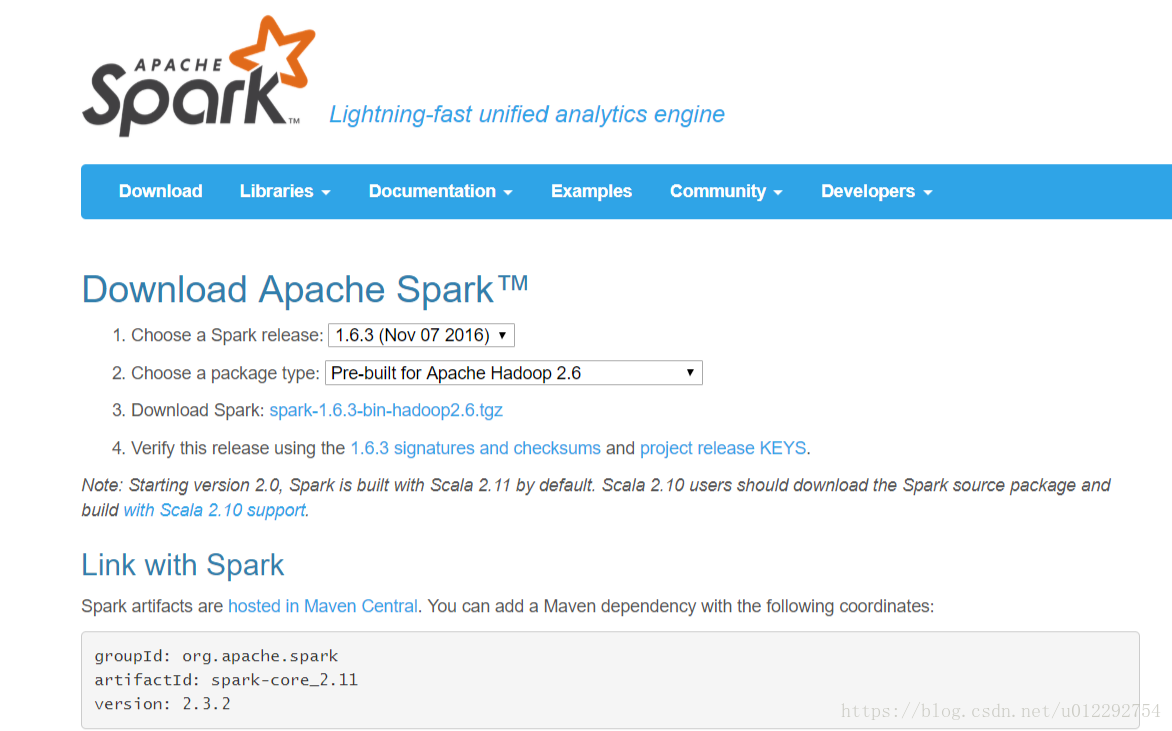
2.1 原始碼上傳到叢集
解壓
2.2 修改配置檔案
2.2.1 spark-env.sh
[[email protected] ~]$ cd /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/
[[email protected] spark-1.6.3-bin-hadoop2.6]$ ll
total 1380
drwxr-xr-x. 2 hadoop hadoop 4096 Nov 3 2016 bin
-rw-r--r--. 1 hadoop hadoop 1343562 Nov 3 2016 CHANGES.txt
drwxr-xr-x. 2 hadoop hadoop 230 Nov 3 2016 conf
drwxr-xr-x. 3 hadoop hadoop 19 Nov 3 2016 data
drwxr-xr-x. 3 hadoop hadoop 79 Nov 3 2016 ec2
drwxr-xr-x. 3 hadoop hadoop 17 Nov 3 2016 examples
drwxr-xr-x. 2 hadoop hadoop 237 Nov 3 2016 lib
-rw-r--r--. 1 hadoop hadoop 17352 Nov 3 2016 LICENSE
drwxr-xr-x. 2 hadoop hadoop 4096 Nov 3 2016 licenses
-rw-r--r--. 1 hadoop hadoop 23529 Nov 3 2016 NOTICE
drwxr-xr-x. 6 hadoop hadoop 119 Nov 3 2016 python
drwxr-xr-x. 3 hadoop hadoop 17 Nov 3 2016 R
-rw-r--r--. 1 hadoop hadoop 3359 Nov 3 2016 README.md
-rw-r--r--. 1 hadoop hadoop 120 Nov 3 2016 RELEASE
drwxr-xr-x. 2 hadoop hadoop 4096 Nov 3 2016 sbin
[[email protected] spark-1.6.3-bin-hadoop2.6]$ cd conf
[[email protected] conf]$ ll
total 36
-rw-r--r--. 1 hadoop hadoop 987 Nov 3 2016 docker.properties.template
-rw-r--r--. 1 hadoop hadoop 1105 Nov 3 2016 fairscheduler.xml.template
-rw-r--r--. 1 hadoop hadoop 1734 Nov 3 2016 log4j.properties.template
-rw-r--r--. 1 hadoop hadoop 6671 Nov 3 2016 metrics.properties.template
-rw-r--r--. 1 hadoop hadoop 865 Nov 3 2016 slaves.template
-rw-r--r--. 1 hadoop hadoop 1292 Nov 3 2016 spark-defaults.conf.template
-rwxr-xr-x. 1 hadoop hadoop 4209 Nov 3 2016 spark-env.sh.template
[[email protected] conf]$ mv spark-env.sh.template spark-env.sh
在配置檔案中新增如下配置
export JAVA_HOME=/usr/apps/jdk1.8.0_181-amd64
export SPARK_MASTER_IP=node1
export SPARK_MASTER_PORT=7077
2.2.2 slaves
[[email protected] conf]$ mv slaves.template slaves
新增內容
node2
node3
2.3 將配置好的Spark拷貝到其他節點上
[[email protected] ~]$ scp -r /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/ node2:/home/hadoop/apps
[[email protected] ~]$ scp -r /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/ node3:/home/hadoop/apps
2.4 修改配置檔案
/etc/profile
export SPARK_HOME=/home/hadoop/apps/spark-1.6.3-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
將配置檔案傳送到 node2,node3
[[email protected] ~]$ sudo scp /etc/profile node2:/etc
[sudo] password for hadoop:
[email protected]'s password:
profile 100% 2427 1.7MB/s 00:00
[[email protected] ~]$ sudo scp /etc/profile node3:/etc
[email protected]'s password:
profile
在三個節點同時 重新整理配置檔案
source /etc/profile
2.5 啟動
[[email protected] ~]$ /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node1.out
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
node3: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node3.out
node2: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node2.out
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node1.out
[[email protected] ~]$
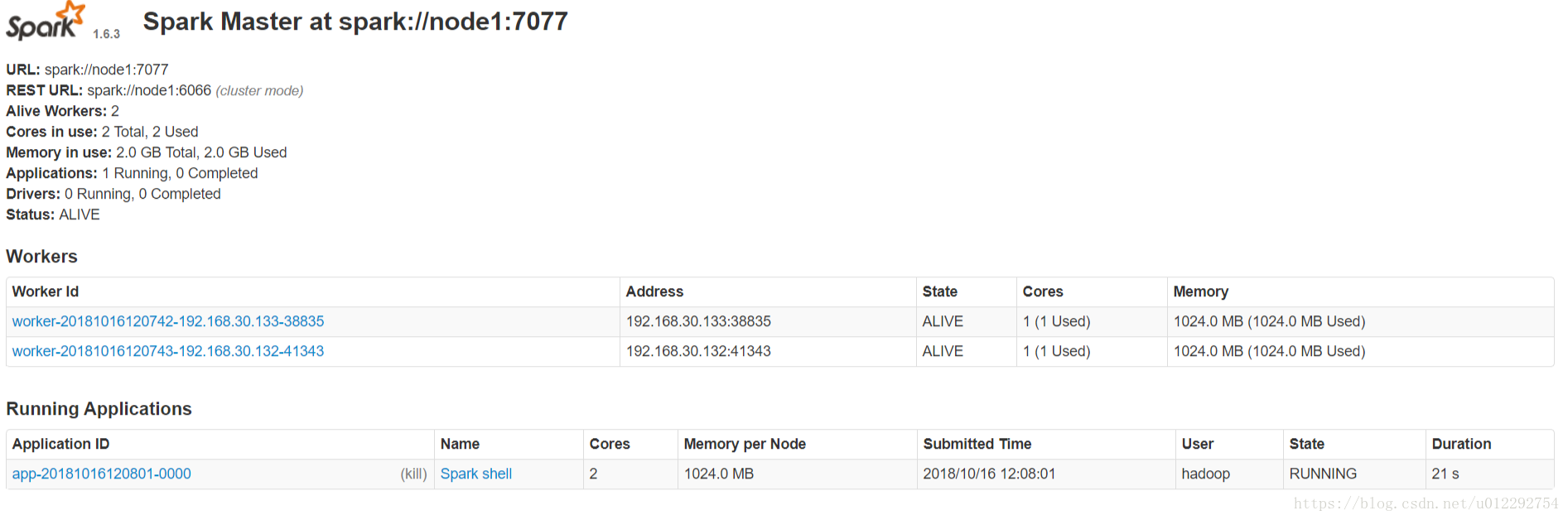
2.5.1 http://node1:8080/
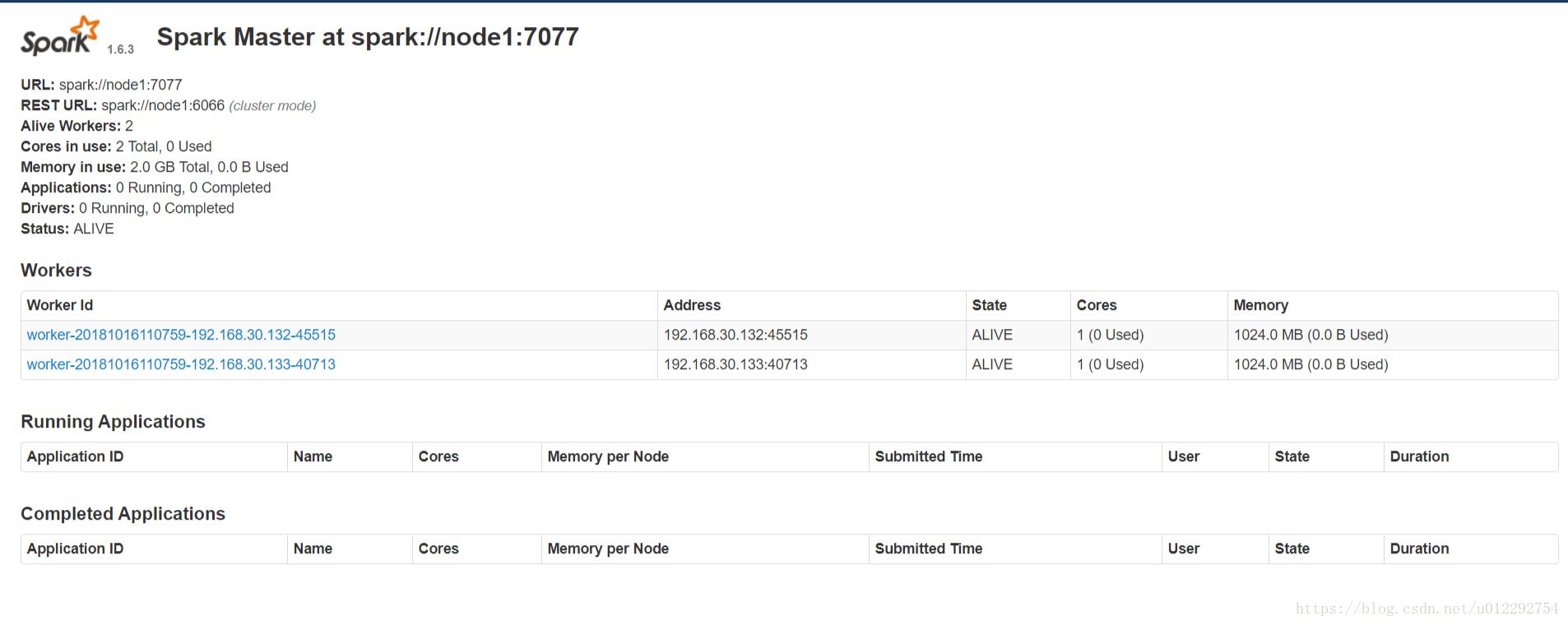
3 Spark Shell
/home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/bin/spark-shell --master spark://node1:7077 --total-executor-cores 4 --executor-memory 1g
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.3
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
18/10/16 12:04:49 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/16 12:04:50 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/16 12:04:54 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
18/10/16 12:04:54 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
18/10/16 12:04:57 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/16 12:04:57 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/16 12:05:02 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
18/10/16 12:05:02 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
SQL context available as sqlContext.
scala>
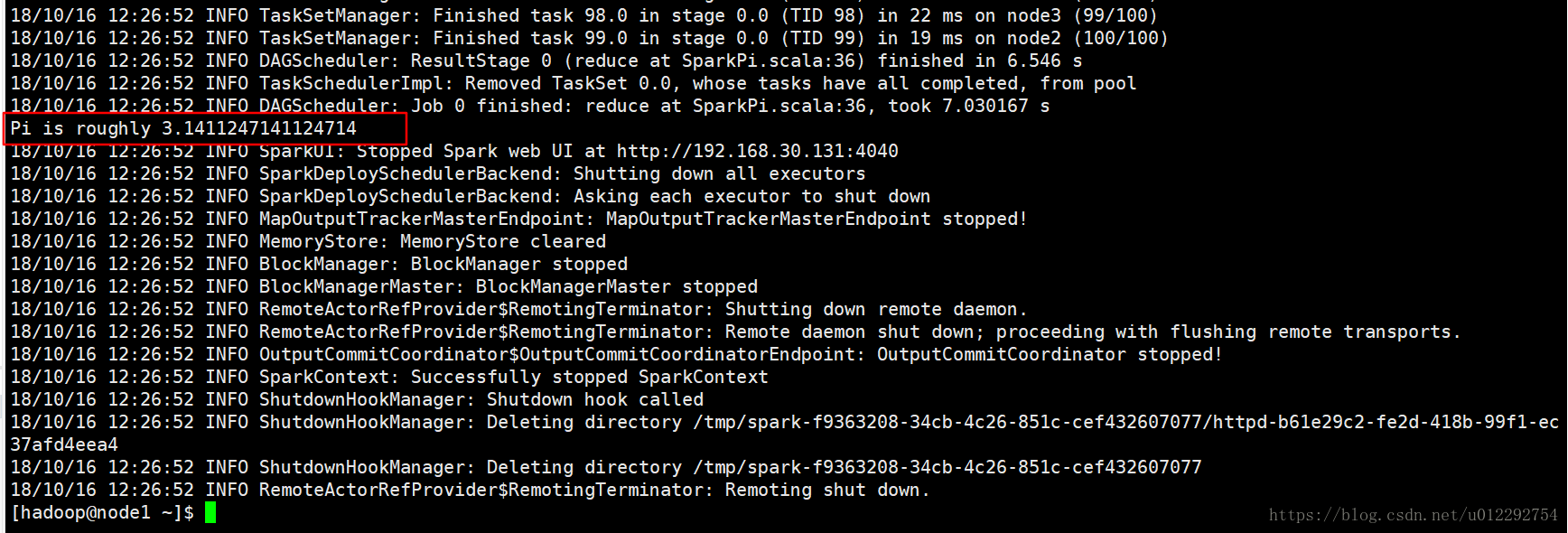
4 執行第一個 Spark 程式
利用蒙特·卡羅演算法求PI
scala> [[email protected] ~]$
[[email protected] ~]$ /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master spark://node1:7077 \
> --executor-memory 1G \
> --total-executor-cores 2 \
> /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/lib/spark-examples-1.6.3-hadoop2.6.0.jar 100