
spark學習筆記(3)spark核心資料結構RDD
一個簡單的例子
這個程式只是簡單的對輸入檔案README.md包含’a’和’b’的行分別計數。當然如果你想執行這個程式,需要YOUR_SPARK_HOME替換為Spark的安裝目錄。程式中定義了一個RDD:logData,並呼叫cache,把RDD資料快取在記憶體中,這樣能防止重複載入檔案。filter是RDD提供的一種操作,它能過濾出符合條件的資料,count是RDD提供的另一個操作,它能返回RDD資料集中的記錄條數。 上述例子介紹了兩種RDD的操作:filter與count;事實上,RDD還提供了許多操作方法,如map,groupByKey,reduce等操作。RDD的操作型別分為兩類,轉換(transformations),它將根據原有的RDD建立一個新的RDD;行動(actions),對RDD操作後把結果返回給driver。例如,map是一個轉換,它把資料集中的每個元素經過一個方法處理後返回一個新的RDD;而reduce則是一個action,它收集RDD的所有資料後經過一些方法的處理,最後把結果返回給driver。/* SimpleApp.scala */ import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object SimpleApp { def main(args: Array[String]) { val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system val conf = new SparkConf().setAppName("Simple Application") //設定程式名字 val sc = new SparkContext(conf) val logData = sc.textFile(logFile, 2).cache() //載入檔案為RDD,並快取 val numAs = logData.filter(line => line.contains("a")).count()//包含a的行數 val numBs = logData.filter(line => line.contains("b")).count()//包含b的行數 println("Lines with a: %s, Lines with b: %s".format(numAs, numBs)) } }
RDD的所有轉換操作都是lazy模式,即Spark不會立刻計算結果,而只是簡單的記住所有對資料集的轉換操作。這些轉換隻有遇到action操作的時候才會開始計算。這樣的設計使得Spark更加的高效,例如,對一個輸入資料做一次map操作後進行reduce操作,只有reduce的結果返回給driver,而不是把資料量更大的map操作後的資料集傳遞給driver。
RDD是什麼
RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一個只讀的,可分割槽的分散式資料集,這個資料集的全部或部分可以快取在記憶體中,在多次計算間重用。那為什麼RDD的效率這麼高呢:(1)RDD資料只讀,不可修改。如果需要修改資料,必須從父RDD轉換(transformation)到子RDD。所以,在容錯策略中,RDD沒有資料冗餘,而是通過RDD父子依賴(血緣)關係進行重算實現容錯。
(2)多個RDD操作之間,資料不用落地到磁碟上,避免不必要的I/O操作。
(3)RDD中存放的資料可以是java物件,所以避免的不必要的物件序列化和反序列化。
總而言之,RDD高效的主要因素是儘量避免不必要的操作和犧牲資料的操作精度,用來提高計算效率。
(1)傳統的MapReduce雖然具有自動容錯、平衡負載和可拓展性的優點,但是其最大缺點是採用非迴圈式的資料流模型,使得在迭代計算式要進行大量的磁碟IO操作。RDD正是解決這一缺點的抽象方法
(2)RDD(彈性資料集)是Spark提供的最重要的抽象的概念,它是一種有容錯機制的特殊集合,可以分佈在叢集的節點上,以函式式操作集合的方式,進行各種並行操作。可以將RDD理解為一個具有容錯機制的特殊集合,它提供了一種只讀、只能有已存在的RDD變換而來的共享記憶體,然後將所有資料都載入到記憶體中,方便進行多次重用。
a.它是分散式的,可以分佈在多臺機器上,進行計算。
b.它是彈性的,計算過程中記憶體不夠時它會和磁碟進行資料交換。
c.這些限制可以極大的降低自動容錯開銷(自動容錯有哪些開銷)
d.實質是一種更為通用的迭代的平行計算框架,使用者可以顯示的控制計算的中間結果,然後將其自由運用於之後的計算。
(3)RDD的容錯機制實現分散式資料集容錯方法有兩種:資料檢查點和記錄更新RDD採用記錄更新的方式:記錄所有更新點的成本很高。所以,RDD只支援粗顆粒變換,即只記錄單個塊上執行的單個操作,然後建立某個RDD的變換序列(血統)儲存下來;變換序列指,每個RDD都包含了他是如何由其他RDD變換過來的以及如何重建某一塊資料的資訊。因此RDD的容錯機制又稱“血統”容錯。 要實現這種“血統”容錯機制,最大的難題就是如何表達父RDD和子RDD之間的依賴關係。實際上依賴關係可以分兩種,窄依賴和寬依賴:窄依賴:子RDD中的每個資料塊只依賴於父RDD中對應的有限個固定的資料塊;寬依賴:子RDD中的一個數據塊可以依賴於父RDD中的所有資料塊。例如:map變換,子RDD中的資料塊只依賴於父RDD中對應的一個數據塊;groupByKey變換,子RDD中的資料塊會依賴於多有父RDD中的資料塊,因為一個key可能錯在於父RDD的任何一個數據塊中 將依賴關係分類的兩個特性:第一,窄依賴可以在某個計算節點上直接通過計算父RDD的某塊資料計算得到子RDD對應的某塊資料;寬依賴則要等到父RDD所有資料都計算完成之後,並且父RDD的計算結果進行hash並傳到對應節點上之後才能計運算元RDD。第二,資料丟失時,對於窄依賴只需要重新計算丟失的那一塊資料來恢復;對於寬依賴則要將祖先RDD中的所有資料塊全部重新計算來恢復。所以在長“血統”鏈特別是有寬依賴的時候,需要在適當的時機設定資料檢查點。也是這兩個特性要求對於不同依賴關係要採取不同的任務排程機制和容錯恢復機制。
(4)每個RDD都需要包含以下四個部分:
a.源資料分割後的資料塊,原始碼中的splits變數
b.關於“血統”的資訊,原始碼中的dependencies變數
c.一個計算函式(該RDD如何通過父RDD計算得到),原始碼中的iterator(split)和compute函式
d.一些關於如何分塊和資料存放位置的元資訊,如原始碼中的partitioner和preferredLocations
例如:a.一個從分散式檔案系統中的檔案得到的RDD具有的資料塊通過切分各個檔案得到的,它是沒有父RDD的,它的計算函式知識讀取檔案的每一行並作為一個元素返回給RDD;b.對與一個通過map函式得到的RDD,它會具有和父RDD相同的資料塊,它的計算函式式對每個父RDD中的元素所執行的一個函式
RDD在Spark中的地位及作用
(1)為什麼會有Spark?因為傳統的平行計算模型無法有效的解決迭代計算(iterative)和互動式計算(interactive);而Spark的使命便是解決這兩個問題,這也是他存在的價值和理由。
(2)Spark如何解決迭代計算?其主要實現思想就是RDD,把所有計算的資料儲存在分散式的記憶體中。迭代計算通常情況下都是對同一個資料集做反覆的迭代計算,資料在記憶體中將大大提升IO操作。這也是Spark涉及的核心:記憶體計算。
(3)Spark如何實現互動式計算?因為Spark是用scala語言實現的,Spark和scala能夠緊密的整合,所以Spark可以完美的運用scala的直譯器,使得其中的scala可以向操作本地集合物件一樣輕鬆操作分散式資料集。
(4)Spark和RDD的關係?可以理解為:RDD是一種具有容錯性基於記憶體的叢集計算抽象方法,Spark則是這個抽象方法的實現。RDD原理
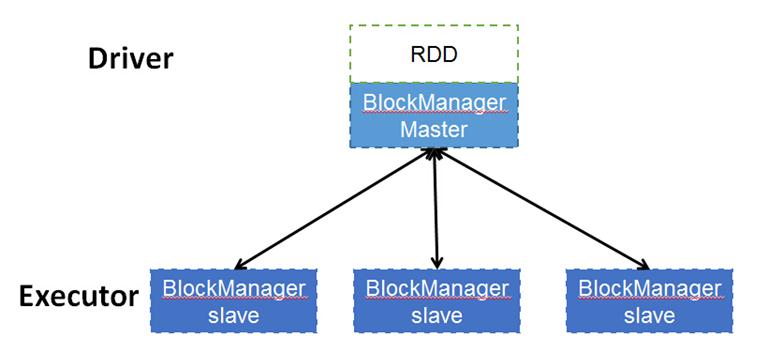
RDD cache的原理
RDD的轉換過程中,並不是每個RDD都會儲存,如果某個RDD會被重複使用,或者計算其代價很高,那麼可以通過顯示呼叫RDD提供的cache()方法,把該RDD儲存下來。那RDD的cache是如何實現的呢?RDD中提供的cache()方法只是簡單的把該RDD放到cache列表中。當RDD的iterator被呼叫時,通過CacheManager把RDD計算出來,並存儲到BlockManager中,下次獲取該RDD的資料時便可直接通過CacheManager從BlockManager讀出。
RDD dependency與DAG
RDD提供了許多轉換操作,每個轉換操作都會生成新的RDD,這是新的RDD便依賴於原有的RDD,這種RDD之間的依賴關係最終形成了DAG(Directed Acyclic Graph)。
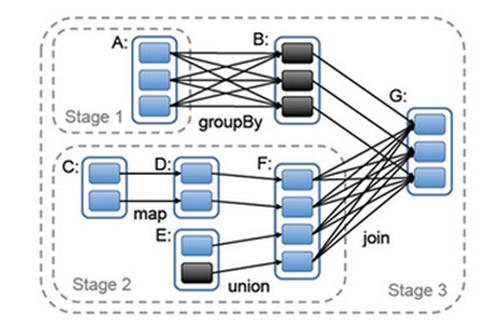
RDD之間的依賴關係分為兩種,分別是NarrowDependency與ShuffleDependency,其中ShuffleDependency為子RDD的每個Partition都依賴於父RDD的所有Partition,而NarrowDependency則只依賴一個或部分的Partition。下圖的groupBy與join操作是ShuffleDependency,map和union是NarrowDependency。
這裡寫圖片描述
RDD partitioner與並行度
每個RDD都有Partitioner屬性,它決定了該RDD如何分割槽,當然Partition的個數還將決定每個Stage的Task個數。當前Spark需要應用設定Stage的並行Task個數(配置項為:spark.default.parallelism),在未設定的情況下,子RDD會根據父RDD的Partition決定,如map操作下子RDD的Partition與父Partition完全一致,Union操作時子RDD的Partition個數為父Partition個數之和。
如何設定spark.default.parallelism對使用者是一個挑戰,它會很大程度上決定Spark程式的效能。
(http://blog.csdn.net/stark_summer/article/details/50218641)
在hadoop中一個獨立的計算,例如在一個迭代過程中,除可複製的檔案系統(HDFS)外沒有提供其他儲存的概念,這就導致在網路上進行資料複製而增加了大量的消耗,而對於兩個的MapReduce作業之間資料共享只有一個辦法,就是將其寫到一個穩定的外部儲存系統,如分散式檔案系統。這會引入資料備份、磁碟I/O以及序列化,這些都會引起大量的開銷,從而佔據大部分的應用執行時間。所以我們發現如果在計算過程中如能共享資料,那將會降低叢集開銷同時還能減少任務執行時間。
2.而 spark中的RDDs讓使用者可以直接控制資料的共享。RDD具有可容錯和並行資料結構特徵,可以指定資料儲存到硬碟還是記憶體、控制資料的分割槽方法並在資料集上進行種類豐富的操作。
3.目前提出的基於叢集的記憶體儲存抽象,比如分散式共享記憶體(Distributed Shared Memory|DSM),鍵-值儲存(Key-Value|Nosql),資料庫(RDBMS)等提供了一個對內部狀態基於細粒度更新的介面(例如,表格裡面的單元)。而這樣設計,提供容錯性的方法:在主機之間複製資料,或者對各主機的更新情況做日誌記錄。但這兩種方法對於資料密集型的任務來說代價很高,因為它們需要在頻寬遠低於記憶體的叢集網路間拷貝大量的資料,同時還將產生大量的儲存開銷。但RDD提供一種基於粗粒度變換(如 map,filter,join)的介面,該介面會將相同的操作應用到多個數據集上。這使得他們可以通過記錄用來建立資料集的變換(lineage),而不需儲存真正的資料,進而達到高效的容錯性。當一個RDD的某個分割槽丟失的時候,RDD記錄有足夠的資訊記錄其如何通過其他的RDD進行計算,且只需重新計算該分割槽。因此,丟失的資料可以被很快的恢復,而不需要昂貴的複製代價。
主角
首先我們來思考一個問題吧:Spark的計算模型是如何做到並行的呢?如果你有一箱香蕉,讓三個人拿回家吃完(好吧,我承認我愛吃香蕉,哈哈),如果不拆箱子就會很麻煩對吧,哈哈,一個箱子嘛,當然只有一個人才能抱走了。這時候智商正常的人都知道要把箱子開啟,倒出來香蕉,分別拿三個小箱子重新裝起來,然後,各自抱回家去啃吧。
Spark和很多其他分散式計算系統都借用了這種思想來實現並行:把一個超大的資料集,切分成N個小堆,找M個執行器(M < N),各自拿一塊或多塊資料慢慢玩,玩出結果了再收集在一起,這就算執行完啦。那麼Spark做了一項工作就是:凡是能夠被我算的,都是要符合我的要求的,所以spark無論處理什麼資料先整成一個擁有多個分塊的資料集再說,這個資料集就叫RDD。
好了,那現在就詳細介紹下RDD吧
1.概念
RDD(Resilient Distributed Datasets,彈性分散式資料集)是一個分割槽的只讀記錄的集合。RDD只能通過在穩定的儲存器或其他RDD的資料上的確定性操作來建立。我們把這些操作稱作變換以區別其他型別的操作。例如 map,filter和join。
RDD在任何時候都不需要被”物化”(進行實際的變換並最終寫入穩定的儲存器上)。實際上,一個RDD有足夠的資訊描述著其如何從其他穩定的儲存器上的資料生成。它有一個強大的特性:從本質上說,若RDD失效且不能重建,程式將不能引用該RDD。而使用者可以控制RDD的其他兩個方面:持久化和分割槽。使用者可以選擇重用哪個RDD,併為其制定儲存策略(比如,記憶體儲存)。也可以讓RDD中的資料根據記錄的key分佈到叢集的多個機器。 這對位置優化來說是有用的,比如可用來保證兩個要jion的資料集都使用了相同的雜湊分割槽方式。
2.spark 程式設計介面
對程式設計人員通過對穩定儲存上的資料進行變換操作(如map和filter).而得到一個或多個RDD。然後可以呼叫這些RDD的actions(動作)類的操作。這類操作的目是返回一個值或是將資料匯入到儲存系統中。動作類的操作如count(返回資料集的元素數),collect(返回元素本身的集合)和save(輸出資料集到儲存系統)。spark直到RDD第一次呼叫一個動作時才真正計算RDD。
還可以呼叫RDD的persist(持久化)方法來表明該RDD在後續操作中還會用到。預設情況下,spark會將呼叫過persist的RDD存在記憶體中。但若記憶體不足,也可以將其寫入到硬碟上。通過指定persist函式中的引數,使用者也可以請求其他持久化策略(如Tachyon)並通過標記來進行persist,比如僅儲存到硬碟上或是在各機器之間複製一份。最後,使用者可以在每個RDD上設定一個持久化的優先順序來指定記憶體中的哪些資料應該被優先寫入到磁碟。
PS:
快取有個快取管理器,spark裡被稱作blockmanager。注意,這裡還有一個誤區是,很多初學的同學認為呼叫了cache或者persist的那一刻就是在快取了,這是完全不對的,真正的快取執行指揮在action被觸發。
說了一大堆枯燥的理論,我用一個例子來解釋下吧:
現在資料儲存在hdfs上,而資料格式以“;”作為每行資料的分割:
"age";"job";"marital";"education";"default";"balance";"housing";"loan"30;"unemployed";"married";"primary";"no";1787;"no";"no"33;"services";"married";"secondary";"no";4789;"yes";"yes"
scala程式碼如下:
//1.定義了以一個HDFS檔案(由數行文字組成)為基礎的RDD
val lines = sc.textFile("/data/spark/bank/bank.csv") //2.因為首行是檔案的標題,我們想把首行去掉,返回新RDD是withoutTitleLines
val withoutTitleLines = lines.filter(!_.contains("age")) //3.將每行資料以;分割下,返回名字是lineOfData的新RDD
val lineOfData = withoutTitleLines.map(_.split(";")) //4.將lineOfData快取到記憶體到,並設定快取名稱是lineOfData
lineOfData.setName("lineOfData")
lineOfData.persist //5.獲取大於30歲的資料,返回新RDD是gtThirtyYearsData
val gtThirtyYearsData = lineOfData.filter(line => line(0).toInt > 30) //到此,叢集上還沒有工作被執行。但是,使用者現在已經可以在動作(action)中使用RDD。 //計算大於30歲的有多少人
gtThirtyYearsData.count //返回結果是3027
OK,我現在要解釋兩個概念NO.1 什麼是lineage?,NO.2 transformations 和 actions是什麼?
lineage:
在上面查詢大於30歲人查詢裡,我們最開始得出去掉標題行所對應的RDD lines,即為withTitleLines,接著對withTitleLines進行map操作分割每行資料內容,之後再次進行過濾age大於30歲的人、最後進行count(統計所有記錄)。Spark的排程器會對最後的那個兩個變換操作流水線化,併發送一組任務給那些儲存了lineOfData對應的快取分割槽的節點。另外,如果lineOfData的某個分割槽丟失,Spark將只在該分割槽對應的那些行上執行原來的split操作即可恢復該分割槽。 所以在spark計算時,當前RDD不可用時,可以根據父RDD重新計算當前RDD資料,但如果父RDD不可用時,可以可以父RDD的父RDD重新計算父RDD。
transformations 和 actions
transformations操作理解成一種惰性操作,它只是定義了一個新的RDD,而不是立即計算它。相反,actions操作則是立即計算,並返回結果給程式,或者將結果寫入到外儲存中。
下面我以示例解釋下:
先簡單介紹這些吧,稍後文章我會詳細介紹每個方法的使用,感興趣可以看spark官方文件
3.RDDs介面5個特性
簡單概括為:一組分割槽,他們是資料集的最小分片;一組 依賴關係,指向其父RDD;一個函式,基於父RDD進行計算;以及劃分策略和資料位置的元資料。例如:一個表現HDFS檔案的RDD將檔案的每個檔案塊表示為一個分割槽,並且知道每個檔案塊的位置資訊。同時,對RDD進行map操作後具有相同的劃分。當計算其元素時,將map函式應用於父RDD的資料。
4.RDDs依賴關係
1. 在spark中如何表示RDD之間的依賴關係分為兩類: 窄依賴:每個父RDD的分割槽都至多被一個子RDD的分割槽使用,即為OneToOneDependecies; 寬依賴:多個子RDD的分割槽依賴一個父RDD的分割槽,即為OneToManyDependecies。 例如,map操作是一種窄依賴,而join操作是一種寬依賴(除非父RDD已經基於Hash策略被劃分過了)
2. 詳細介紹: 首先,窄依賴允許在單個叢集節點上流水線式執行,這個節點可以計算所有父級分割槽。例如,可以逐個元素地依次執行filter操作和map操作。相反,寬依賴需要所有的父RDD資料可用並且資料已經通過類MapReduce的操作shuffle完成。 其次,在窄依賴中,節點失敗後的恢復更加高效。因為只有丟失的父級分割槽需要重新計算,並且這些丟失的父級分割槽可以並行地在不同節點上重新計算。與此相反,在寬依賴的繼承關係中,單個失敗的節點可能導致一個RDD的所有先祖RDD中的一些分割槽丟失,導致計算的重新執行。 對於hdfs:HDFS檔案作為輸入RDD。對於這些RDD,partitions代表檔案中每個檔案塊的分割槽(包含檔案塊在每個分割槽物件中的偏移量),preferredLocations表示檔案塊所在的節點,而iterator讀取這些檔案塊。 對於map:在任何一個RDD上呼叫map操作將返回一個MappedRDD物件。這個物件與其父物件具有相同的分割槽以及首選地點(preferredLocations),但在其迭代方法(iterator)中,傳遞給map的函式會應用到父物件記錄。 再一個經典的RDDs依賴圖吧
5.作業排程
當用戶對一個RDD執行action(如count 或save)操作時, 排程器會根據該RDD的lineage,來構建一個由若干階段(stage) 組成的一個DAG(有向無環圖)以執行程式,如下圖所示。 每個stage都包含儘可能多的連續的窄依賴型轉換。各個階段之間的分界則是寬依賴所需的shuffle操作,或者是DAG中一個經由該分割槽能更快到達父RDD的已計算分割槽。之後,排程器執行多個任務來計算各個階段所缺失的分割槽,直到最終得出目標RDD。 排程器向各機器的任務分配採用延時排程機制並根據資料儲存位置(本地性)來確定。若一個任務需要處理的某個分割槽剛好儲存在某個節點的記憶體中,則該任務會分配給那個節點。否則,如果一個任務處理的某個分割槽,該分割槽含有的RDD提供較佳的位置(例如,一個HDFS檔案),我們把該任務分配到這些位置。 “對應寬依賴類的操作 {比如 shuffle依賴),會將中間記錄物理化到儲存父分割槽的節點上。這和MapReduce物化Map的輸出類似,能簡化資料的故障恢復過程。 對於執行失敗的任務,只要它對應stage的父類資訊仍然可用,它便會在其他節點上重新執行。如果某些stage變為不可用(例如,因為shuffle在map階段的某個輸出丟失了),則重新提交相應的任務以平行計算丟失的分割槽。 若某個任務執行緩慢 (即”落後者”straggler),系統則會在其他節點上執行該任務的拷貝,這與MapReduce做法類似,並取最先得到的結果作為最終的結果。 實線圓角方框標識的是RDD。陰影背景的矩形是分割槽,若已存於記憶體中則用黑色背景標識。RDD G 上一個action的執行將會以寬依賴為分割槽來構建各個stage,對各stage內部的窄依賴則前後連線構成流水線。在本例中,stage 1 的輸出已經存在RAM中,所以直接執行 stage 2 ,然後stage 3。
6.記憶體管理
Spark提供了三種對持久化RDD的儲存策略:未序列化Java物件存於記憶體中、序列化後的資料存於記憶體及磁碟儲存。第一個選項的效能表現是最優秀的,因為可以直接訪問在JAVA虛擬機器記憶體裡的RDD物件。在空間有限的情況下,第二種方式可以讓使用者採用比JAVA物件圖更有效的記憶體組織方式,代價是降低了效能。第三種策略適用於RDD太大難以儲存在記憶體的情形,但每次重新計算該RDD會帶來額外的資源開銷。
對於有限可用記憶體,Spark使用以RDD為物件的LRU回收演算法來進行管理。當計算得到一個新的RDD分割槽,但卻沒有足夠空間來儲存它時,系統會從最近最少使用的RDD中回收其一個分割槽的空間。除非該RDD便是新分割槽對應的RDD,這種情況下,Spark會將舊的分割槽繼續保留在記憶體,防止同一個RDD的分割槽被迴圈調入調出。因為大部分的操作會在一個RDD的所有分割槽上進行,那麼很有可能已經存在記憶體中的分割槽將會被再次使用。
7.檢查點支援(checkpoint) 雖然lineage可用於錯誤後RDD的恢復,但對於很長的lineage的RDD來說,這樣的恢復耗時較長。因此,將某些RDD進行檢查點操作(Checkpoint)儲存到穩定儲存上,是有幫助的。 通常情況下,對於包含寬依賴的長血統的RDD設定檢查點操作是非常有用的,在這種情況下,叢集中某個節點的故障會使得從各個父RDD得出某些資料丟失,這時就需要完全重算。相反,對於那些窄依賴於穩定儲存上資料的RDD來說,對其進行檢查點操作就不是有必要的。如果一個節點發生故障,RDD在該節點中丟失的分割槽資料可以通過並行的方式從其他節點中重新計算出來,計算成本只是複製整個RDD的很小一部分。 Spark當前提供了為RDD設定檢查點(用一個REPLICATE標誌來持久化)操作的API,讓使用者自行決定需要為哪些資料設定檢查點操作。 最後,由於RDD的只讀特性使得比常用的共享記憶體更容易做checkpoint,因為不需要關心一致性的問題,RDD的寫出可在後臺進行,而不需要程式暫停或進行分散式快照。
序幕
好了,講了一大堆RDD理論上概念,現在,問問自己什麼是RDD呢?我用最簡單幾句話概括下吧。 RDD是spark的核心,也是整個spark的架構基礎,RDD是彈性分散式集合(Resilient Distributed Datasets)的簡稱,是分散式只讀且已分割槽集合物件。這些集合是彈性的,如果資料集一部分丟失,則可以對它們進行重建。具有自動容錯、位置感知排程和可伸縮性,而容錯性是最難實現的,大多數分散式資料集的容錯性有兩種方式:資料檢查點和記錄資料的更新。對於大規模資料分析系統,資料檢查點操作成本高,主要原因是大規模資料在伺服器之間的傳輸帶來的各方面的問題,相比記錄資料的更新,RDD也只支援粗粒度的轉換,也就是記錄如何從其他RDD轉換而來(即lineage),以便恢復丟失的分割槽。 簡而言之,特性如下: 1. 資料結構不可變 2. 支援跨叢集的分散式資料操作 3. 可對資料記錄按key進行分割槽 4. 提供了粗粒度的轉換操作 5. 資料儲存在記憶體中,保證了低延遲性
由於篇幅有限,我就介紹這些吧~,下篇整體介紹下spark架構&spark環境搭建&測試
參考資料: