
DensePose:姿態轉換模型
DensePose 是 Facebook 研究員 Natalia Neverova、Iasonas Kokkinos 和法國 INRIA 的 Rıza Alp Guler 開發的一個令人驚歎的人體實時姿勢識別系統,它在 2D 影象和人體3D 模型之間建立對映,最終實現密集人群的實時姿態識別。
具體來說,DensePose 利用深度學習將 2D RPG 影象座標對映到 3D 人體表面,把一個人分割成許多 UV 貼圖(UV 座標),然後處理密集座標,實現動態人物的精確定位和姿態估計。

DensePose 模型以及資料集已經開源,傳送門:
最近,該團隊更進一步,釋出了基於 DensePose 的一個姿勢轉換系統:Dense Pose Transfer

在這項工作中,研究者希望僅依賴基於表面(surface-based)的物件表示(object representations),類似於在圖形引擎中使用的物件表示,來獲得對影象合成過程的更強把握。
研究者關注的重點是人體。模型建立在最近的 SMPL 模型和 DensePose 系統的基礎上,將這兩個系統結合在一起,從而能夠用完整的表面模型來說明一個人的影象。
下面的視訊展示了更多生成結果:

具體而言,這項技術是通過 surface-based 的神經合成,渲染同一個人的不同姿勢,從而執行影象生成。目標姿勢(target pose)是通過一個 “pose donor” 的影象表示的,也就是指導影象合成的另一個人。DensePose 系統用於將新的照片與公共表面座標相關聯,並複製預測的外觀。
我們在 DeepFashion 和 MVC 資料集進行了實驗,結果表明我們可以獲得比最新技術更好的定量結果。
除了姿勢轉換的特定問題外,所提出的神經合成與 surface-based 的表示相結合的方法也有希望解決虛擬現實和增強現實的更廣泛問題:由於 surface-based 的表示,合成的過程更加透明,也更容易與物理世界連線。未來,姿勢轉換任務可能對資料集增強、訓練偽造檢測器等應用很有用。
Dense Pose Transfer
研究人員以一種高效的、自下而上的方式,將每個人體畫素與其在人體引數化的座標關聯起來,開發了圍繞 DensePose 估計系統進行姿勢轉換的方法。
我們以兩種互補的方式利用 DensePose 輸出,對應於預測模組和變形模組(warping module),如圖 1 所示。
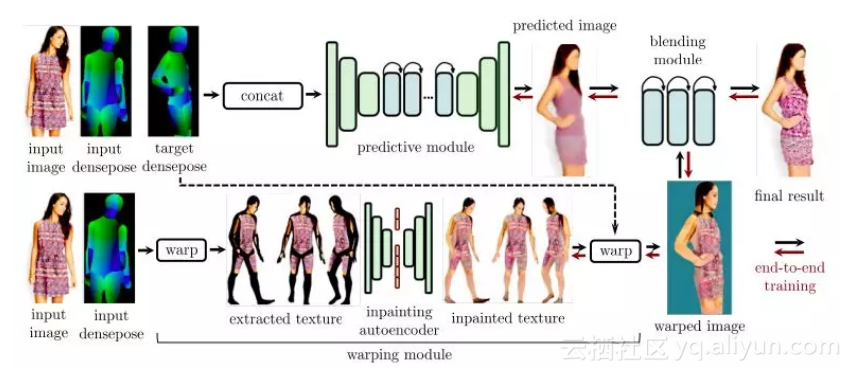
圖 1:pose transfer pipeline 的概覽:給定輸入影象和目標姿勢,使用 DensePose 來執行生成過程。
變形模組使用 DensePose 表面對應和影象修復(inpainting)來生成人物的新檢視,而預測模組是一個通用的黑盒生成模型,以輸入和目標的 DensePose 輸出作為條件。
這兩個模組具有互補的優點:預測模組成功地利用密集條件輸出來為熟悉的姿勢生成合理的影象;但它不能推廣的新的姿勢,或轉換紋理細節。
相比之下,變形模組可以保留高質量的細節和紋理,允許在一個統一的、規範的座標系中進行修復,並且可以自由地推廣到各種各樣的身體動作。但是,它是以身體為中心的,而不是以衣服為中心,因此沒有考慮頭髮、衣服和配飾。
將這兩個模組的輸出輸入到一個混合模組(blending module)可以得到最好的結果。這個混合模組通過在一個端到端可訓練的框架中使用重構、對抗和感知損失的組合,來融合和完善它們的預測。
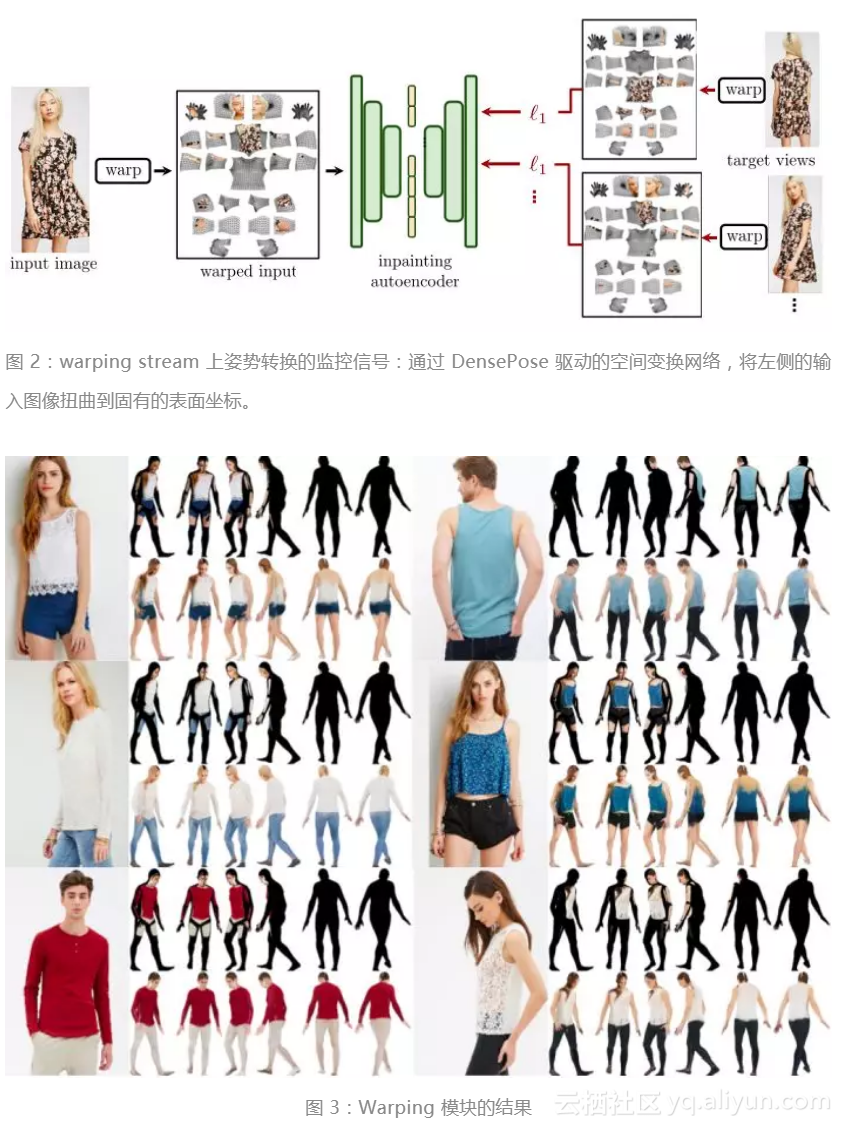
如圖 3 所示,在修復過程(inpainting process),可以觀察到一個均勻的表面,捕捉了面板和貼身衣服的外觀,但沒有考慮頭髮、裙子或外衣,因為這些不適合 DensePose的表面模型。
實驗和結果
我們在 DeepFashion 資料集上進行實驗,該資料集包含 52712 個時裝模特影象,13029 件不同姿勢的服裝。我們選擇了 12029 件衣服進行訓練,其餘 1000 件用於測試。
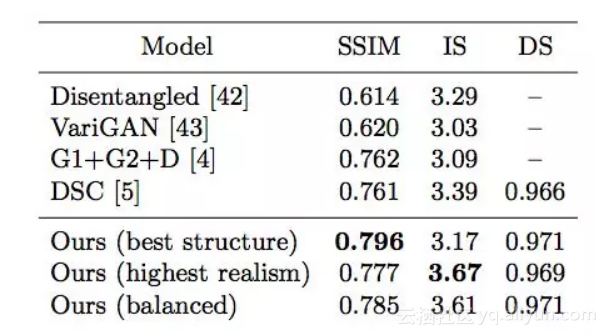
表1:根據結構相似度 (SSIM)、 Inception Score(IS)[41] 和 detection score(DS)指標,對DeepFashion 資料集的幾種 state-of-the-art 方法進行定量比較。
我們首先將我們的框架與最近一些基於關鍵點的影象生成或多檢視合成方法進行比較。
表 1 顯示,我們的 pipeline 在結構逼真度(structural fidelity)方面有顯著優勢。在以IS 作為指標的感知質量方面,我們模型的輸出生成具有更高的質量,或可與現有工作相媲美。
定性結果如圖 4 所示。

圖 4:與最先進的 Deformable GAN (DSC) 方法的定性比較。
密集人體姿態轉換應用
在這項工作中,我們介紹了一個利用密集人體姿態估計的 two-stream 姿態轉換架構。我們已經證明,密集姿勢估計對於資料驅動的人體姿勢估計而言是一種明顯優越的調節訊號,並且通過 inpainting 的方法在自然的體表引數化過程中建立姿勢轉換。在未來的工作中,我們打算進一步探索這種方法在照片級真實影象合成,以及處理更多類別方面的潛力。
作者:

● Rıza Alp Güler,INRIA, CentraleSupélec
● Natalia Neverova,Facebook AI Research
● Iasonas Kokkinos,Facebook AI Research