
深度學習 --- 深度殘差網路(ResNet)變體介紹
先說明,本文不是本人所寫,是本人翻譯得來,目的是系統整理一下,供以後深入研究時引用,如有侵權請聯絡本人刪除。
ResNet變體
寬剩餘網路(WRN):從“寬度”入手做提升:
Wide Residual Network(WRN)由Sergey Zagoruyko和Nikos Komodakis提出。雖然網路不斷向更深層發展,但有時候為了少量的精度增加需要將網路層數翻倍,這樣減少了特徵的重用,也降低訓練速度。因此,作者從“寬度”的角度入手,提出了WRN,16層的WRN效能就比之前的ResNet效果要好。

上圖中a,b是何愷明等人提出的兩種方法,b計算更節省,但是WDN的作者想看寬度的影響,所以採用了a。作者提出增加殘餘塊的3種簡單途徑:
1.更多卷積層
2.加寬(更多特徵平面)
3.增加捲積層的濾波器大小(濾波器尺寸)

WRN結構如上,作者表示,小的濾波器更加高效,所以不準備使用超過3x3的卷積核,提出了寬度放大倍數k和卷積層數l。作者發現,引數隨著深度的增加呈線性增長,但隨著寬度卻是平方長大。雖然引數會增多,但卷積運算更適合GPU。引數的增多需要使用正則化(正則化)減少過擬合,何愷明等人使用了批量標準化,但由於這種方法需要重力增強,於是作者使用了輟學。

WRN 40-4與ResNet-1001結果相似,引數數量相似,但是前者訓練快8倍。作者總結認為:
1.寬度的增加提高了效能
2.增加深度和寬度都有好處,直到引數太大,正則化不夠
3.相同引數時,寬度比深度好訓練
ResNeXt:何愷明等人在Facebook升級ResNet,提出“深度”和“寬度”之外的神經網路新維度
2017年2月,已經加入Facebook的何愷明和S.謝等人在“殘差變換聚合深度網路”(深度神經網路的聚合殘差變換)提出一個名為ResNeXt的殘差網路變體,它的構建塊如下所示:

這個可能看起來很眼熟,因為它與GoogLeNet [4]的初始模組非常類似。它們都遵循“拆分 - 轉換 - 合併”的正規化,區別只在於ResNeXt這個變體中,不同路徑的輸出通過將相加在一起來合併,而在GoogLeNet [4]中不同路徑的輸出是深度連結的。另一個區別是,GoogLeNet [4]中,每個路徑彼此不同(1x1,3x3和5x5卷積),而在ResNeXt架構中,所有路徑共享相同的拓撲。
ResNeXt的作者引入了一個被稱為“基數”(cardinality)的超引數 - 即獨立路徑的數量,以提供一種新方式來調整模型容量。實驗表明,通過增加“基數”提高準確度相比讓網路加深或擴大來提高準確度更有效。作者表示,基數是衡量神經網路在深度(depth)和寬度(width)之外的另一個重要因素。作者還指出,與Inception相比,這種新的架構更容易適應新的資料集/任務,因為它有一個簡單的正規化,而且需要微調的超引數只有一個,而Inception有許多超引數(如每個路徑的卷積層核的大小)需要微調。
這一新的構建塊有如下三種對等形式:

在實際中,這個“分割 - 轉換 - 合併”範例通常是通過“逐點分組卷積層”實現的,這個卷積層會將它獲得的特徵圖輸入分成幾組,然後分別執行正常的卷積操作;最終的輸出是depth concatenated的,並且會被輸入至一個1 * 1的卷積層中。在ImageNet-1K資料集上,作者表明,即使在保持複雜性的限制條件下,增加基數也能夠提高分類精度。此外,當增加容量時,增加基數比更深或更寬有效.ResNeXt在2016年的ImageNet競賽中獲得了第二名。
DenseNet:將輸出從相加改為“相併聯”
也是在2016年,康奈爾大學的高黃和清華大學的莊劉等人在論文密集連線的卷積網路[9]中,提出一種稱為DenseNet的新架構。不同於ResNet將輸出與輸入相加,形成一個殘差結構,DenseNet將輸出與輸入相併聯,實現每一層都能直接得到之前所有層的輸出 .DenseNet進一步利用快捷連線的好處 - 將所有層都直接連線在一起。在這個新架構中,每層的輸入由所有前面的層的特徵對映(feature maps)組成,其輸出傳遞給每個後續的層。特徵對映與depth-concatenation聚合。

ResNet將輸出與輸入相加,形成一個殘差結構;而DenseNet卻是將輸出與輸入相併聯,實現每一層都能直接得到之前所有層的輸出。
深度神經網路的聚合殘差變換[8]的作者除了應對梯度消失問題外,還認為這種架構可以鼓勵特徵重新利用,從而使得網路具有高度的引數效率。一個簡單的解釋是,在深度殘留學習影象識別[2]和深度殘留網路中的身份對映[7]中,身份對映的輸出被新增到下一個塊,如果兩個層的特徵對映具有非常不同的分佈,這可能會阻礙資訊流。因此,級聯特徵對映可以保留所有特徵對映並增加輸出的方差,從而鼓勵特徵重新利用。

根據這種範例,我們知道第l層輸入特徵圖的數量會有k *(l-1)+ k_o個,其中的k_0是輸入影象中的通道數目。作者們使用一個叫做“增長率”(k )的超引數防止網路變得過寬,他們還用了一個1×1的卷積瓶頸層在3×3的卷積前減少特徵對映的數量整體架構如下表所示:

谷歌MobileNet:視覺模型往移動端輕量級發展
說道ResNet(ResNeXt)的變體,還有一個模型不得不提,那就是谷歌的 MobileNet,這是一種用於移動和嵌入式裝置的視覺應用高效模型,在同樣的效果下,計算量可以壓縮至1/30 .MobileNet基於一個流線型的架構,該架構使用deepwise separable convolution來構建輕量級的深度神經網路。作者引入了兩個簡單的全域性超引數,有效權衡延遲和準確度。這些超引數能讓模型搭建者根據問題的限制為其應用選擇適當規模的模型。

“MobileNet一個很大的亮點是對deepwise卷積的大規模使用。將一個二維的depthwise卷積和1x1的對映卷積組合起來可以很好的逼近普通的三維卷積。對於常用的3x3三維卷積來說,利用depthwise和1x1對映來取代可以將計算量壓縮8-9倍,所用到的引數量也大大減少,但仍然保持相類似的精確度。這樣的想法來自於矩陣分解,一般如果一個矩陣是低等級(低秩)的話,可以有很多辦法將其分解成為兩個或者多個矩陣。另外一個啟發是大部分的計算會產生於早期的卷積層,所以MobileNet更早的採用步幅2而大大減少了計算量.MobileNet在ImageNet分類的任務上能達到類似VGG的效果,但是引數和計算量都少了都超過一個數量級(約1/30)。“
深度隨機的神經網路
RESNET的強大效能在很多應用中已經得到了證實,儘管如此,RESNET還是有一個不可忽視的缺陷 - 更深層的網路通常需要進行數週的訓練 - 因此,把它應用在實際場景下的成本非常高。為了解決這個問題,[10]的作者們引入了一個“反直覺”的方法,即在我們可以在訓練過程中任意地丟棄一些層,並在測試過程中使用完整的網路。
作者們用了殘差塊作為他們網路的構件,因此,在訓練中,如果一個特定的殘差塊被啟用了,那麼它的輸入就會同時流經恆等表換捷徑(identity shortcut)和權重層;否則輸入就只會流經恆等變換快捷在訓練的過程中,每一個層都有一個“生存概率”,並且都會被任意丟棄在測試過程中,所有的塊都將保持被啟用。狀態,而且塊都將根據其在訓練中的生存概率進行調整。
從形式上來看,H_L是第升個殘差塊的輸出結果,f_l是由升第升個殘差塊的權重對映所決定的對映,B_L是一個伯努利隨機變數(此變數的值只有1或0 ,反映出一個塊是否是被啟用的)具體訓練過程如下:
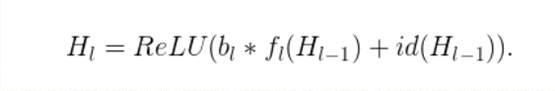
當B_L = 1時,這個塊就是一個正常的殘差塊;當B_L = 0時,上面的公式就變成了這樣
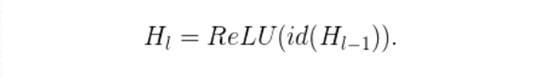
既然我們已經知道了H_(L-1)是一個RELU的輸出結果,而且這個輸出結果已經是非負的了,那麼上面的方程式就會減少到只剩下一個恆等層:
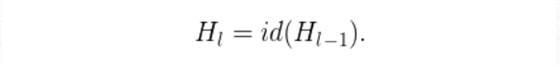
如果P_L表示的是第升層在訓練中的生存概率,那麼在測試過程中,我們就能得到以下的方程式:
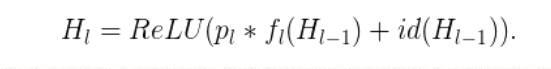
作者們將一個“線性衰減規律”應用於每一層的生存概率,他們表示,由於較早的層會提取低階特徵,而這些低階特徵會被後面的層所利用,所以這些層不應該頻繁地被丟棄這樣,最終生成的規則就變成了這樣:
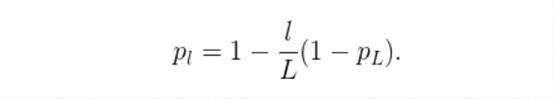
上面公式中的大號表示塊的總數量,因此P_L就是最後一個殘差塊的生存機率,這個機率在整個實驗中一直都保持著0.5的水平。一定要注意的是,在這個情境中的輸入被視為第一個層(L = 0),所以這個第一層永遠不會被丟棄隨機深度訓練的整體框架如下圖所示:

與差[11]類似,用任意的深度來訓練一個深度網路可以看作是訓練一個小型RESNET集合,兩種訓練的區別在於上面的方法是任意地丟棄一整個層的,而差在訓練中僅丟棄一個層的部分隱藏單元。
實驗表明,同樣是訓練一個110層的RESNET,以任意深度進行訓練的效能,比以固定深度進行訓練的效能要好。這就意味著RESNET中的一些層(路徑)可能是冗餘的。
作為小型網路集合的RESNET
[10]一文的作者們提出了一個訓練一個深度網路的“反直覺”方法,即在訓練中任意地丟棄網路的層,並在測試中使用整個網路.Veit等人[12]介紹了一個更加“反直覺”的發現:我們可以刪除經過訓練後的RESNET中的部分層,同時保持相當不錯的網路效能這樣一來RESNET架構就變得更加有趣了,因為在維特等人的論文中,作者對VGG網路做了同樣的操作,移除了一個VGG網路的部分層,而VGG網路的效能出現了顯著的退化。
為了使訓練過程更清晰易懂,維特等人首先介紹了一個RESNET的分解圖。當展開這個網路架構以後,我們就能很清楚地發現,一個有著我個殘差塊的RESNET架構有2 **我個不同的路徑(因為每一殘差塊會提供兩個獨立的路徑)。
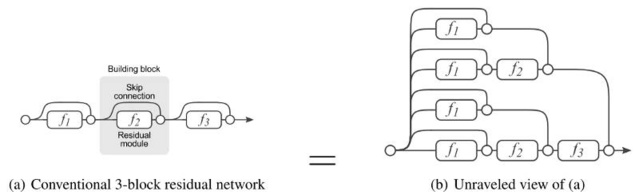
根據以上的分解圖,我們就能清晰地理解為什麼移除RESNET架構中的部分層不會降低其太多效能,這是因為RESNET架構有很多獨立有效路徑,而且大部分路徑在移除了部分層之後會保持完整無損。相反,VGG網路只有一個有效路徑,因此移除一個層都會對它的唯一路徑的效能產生極大的影響。
通過實驗,作者們還發現了RESNET中的路徑有著多模型整合的行為傾向。他們在測試時刪除不同數量的層,檢查網路效能與刪除層的數量是否相關。結果顯示,網路的表現確實有著整體聚集的傾向,具體如下圖所示:

最後,作者們研究了RESNET中路徑的特徵:
很明顯,所有可能路徑長度的分佈都與一個二項式分佈相關,如下圖的(a)中所示。大部分的路徑都流經了19到35個殘差塊。
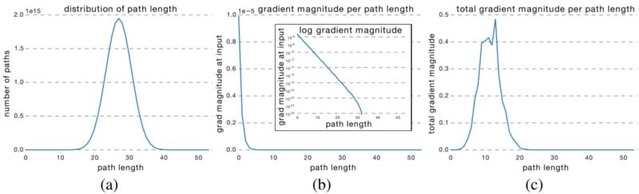
為了得到路徑長度ķ的梯度幅度,作者們首先向網路輸入了一批資料,然後任意取樣了ķ個殘差塊。當反向傳遞梯度時,他們僅將取樣的殘差塊通過權重層進行傳遞(b)中圖表示隨著路徑長度的增加,梯度幅度會迅速下降。
我們現在可以將每一路徑長度與其期望的梯度大小相乘,看每一路徑長度在訓練中起到多大的作用,就像(c)中圖。令人驚訝的是,大多分佈都來自於9到18的路徑長度,但它們都只包含少量的總路徑,如(a)中圖。這是一個非常有趣的發現,因為這暗示著RESNET無法解決過長路徑的梯度消失問題,RESNET的成功實際上源自於它縮短了它的有效路徑(effective path)的長度。
參考文獻
[1]. A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems,pages1097–1105,2012.
[2]. K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385,2015.
[3]. K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556,2014.
[4]. C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 1–9,2015.
[5]. R. Srivastava, K. Greff and J. Schmidhuber. Training Very Deep Networks. arXiv preprint arXiv:1507.06228v2,2015.
[6]. S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, Nov. 1997.
[7]. K. He, X. Zhang, S. Ren, and J. Sun. Identity Mappings in Deep Residual Networks. arXiv preprint arXiv:1603.05027v3,2016.
[8]. S. Xie, R. Girshick, P. Dollar, Z. Tu and K. He. Aggregated Residual Transformations for Deep Neural Networks. arXiv preprint arXiv:1611.05431v1,2016.
[9]. G. Huang, Z. Liu, K. Q. Weinberger and L. Maaten. Densely Connected Convolutional Networks. arXiv:1608.06993v3,2016.
[10]. G. Huang, Y. Sun, Z. Liu, D. Sedra and K. Q. Weinberger. Deep Networks with Stochastic Depth. arXiv:1603.09382v3,2016.
[11]. N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever and R. Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. The Journal of Machine Learning Research 15(1) (2014) 1929–1958.
[12]. A. Veit, M. Wilber and S. Belongie. Residual Networks Behave Like Ensembles of Relatively Shallow Networks. arXiv:1605.06431v2,2016.
原部落格為:https://towardsdatascience.com/an-overview-of-resnet-and-its-variants-5281e2f56035