
Hadoop MapReduce的Shuffle過程
一、概述
理解Hadoop的Shuffle過程是一個大資料工程師必須的,筆者自己將學習筆記記錄下來,以便以後方便複習檢視。
二、
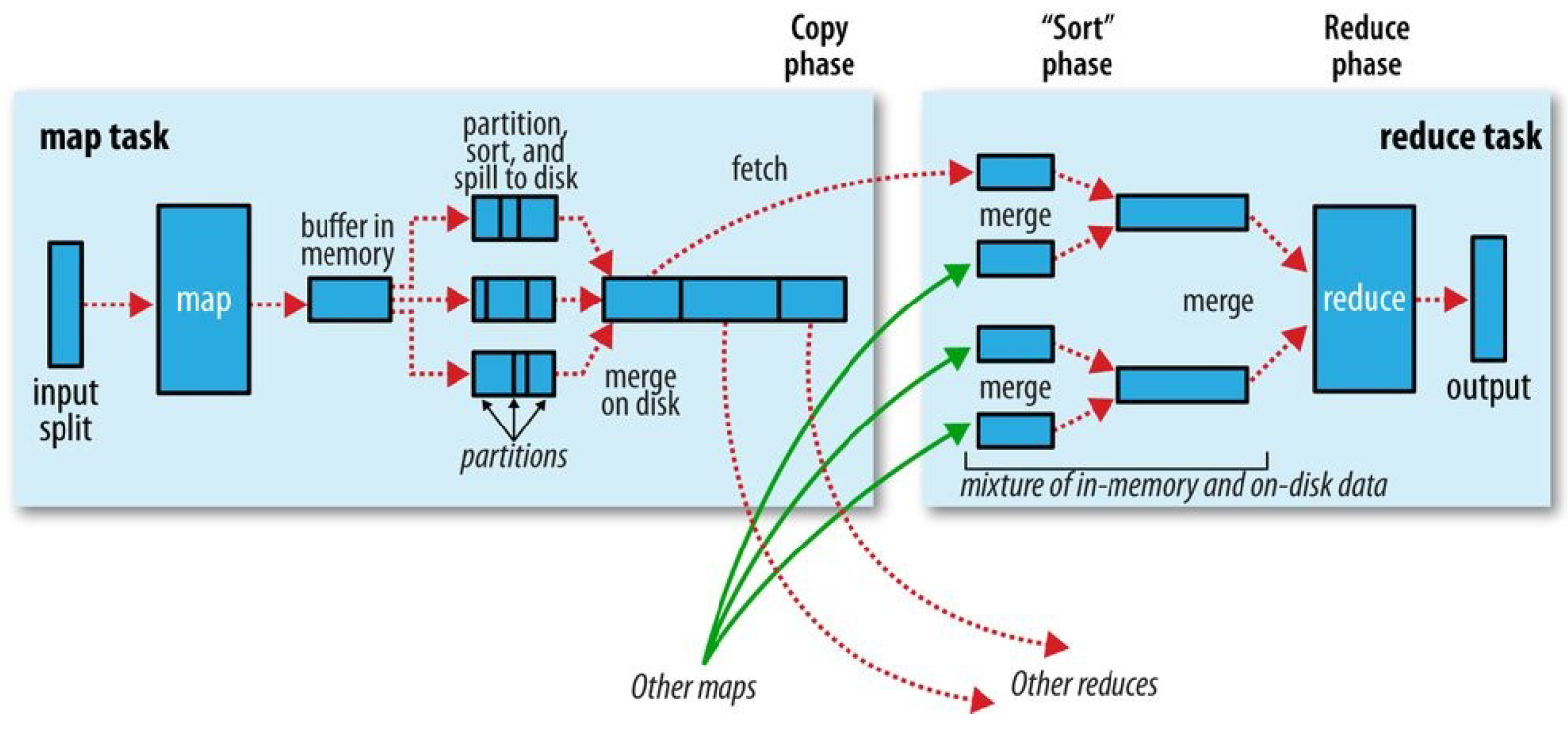
MapReduce確保每個reducer的輸入都是按鍵排序的。系統執行排序、將map輸出作為輸入傳給reducer的過程稱為Shuffle。
2.1 map端
map函式開始產生輸出時,利用緩衝的方式寫到記憶體並排序具體分一下幾個步驟。
1.map資料分片:把輸入資料來源進行分片,根據分片來決定有多少個map,每個map任務都有一個環形記憶體緩衝區用於儲存任務輸出,預設情況下緩衝區大小為100MB,可通過mapreduce.task.io.sort.mb來調整。
2.map排序:當map緩衝區大小達到閾值時(mapreduce.map.sort.spill.percent),就會將記憶體的資料溢寫到磁碟,根據reducer的來劃分成相應的partition,在記憶體中按鍵值進行排序,如果有combiner函式,在排序後就會應用,排序後寫入分割槽磁碟檔案中。溢寫的過程中,map會阻塞直到寫磁碟過程完成。每次記憶體緩衝區到達溢位閾值,就會新建一個溢位檔案件,在map寫完最後一個輸出記錄之後,會有幾個溢位檔案,在任務完成之前溢位檔案會被合併成一個已分割槽且已經排序的輸出檔案。mapreduce.task.io.sort.factor控制著一次最多能合併多少溜,預設10。mapreduce.map.output.compress進行壓縮,提高寫磁碟速度。
2.2reduce端
1.reduce複製:reducer通過http得到輸出檔案的分割槽,用於檔案分割槽的工作執行緒數量由任務的mapreduce.shuffle.max.threads屬性控制。每個map任務的完成時間不同,在每個任務完成時,reduce任務就開始複製其輸出,這就是reduce任務的複製階段,reduce的複製執行緒數量mapreduce.reduce.shuffle.parallelcopies決定。
複製詳解:如果map輸出很小,會被複制到reduce任務JVM的記憶體,否則輸出被複制到磁碟。如果記憶體緩衝區達到閾值大小(mapreduce.reduce.shuffle.merge.percent)或達到map輸出閾值(mapreduce.reduce.merge.inmem.threshold),則合併溢位寫到磁碟中,如果指定combiner,則在合併期間執行它。隨著磁碟上副本增多,後臺執行緒會將他們合併為更大的,排序的檔案。
2.reduce合併排序:這個階段合併map輸出,維持其順序排序,這是迴圈進行的,如果有50個map輸出,合併因子是10(mapreduce.task.io.sort.factor),合併將進行5次,最後有5箇中間檔案。
3.reduce:直接把資料輸入reduce函式,從而省略了一次磁碟的往返行程。
至此mapreduce過程完畢,具體參考Hadoop權威指南第四版。