
SparkStreaming中reduceByKeyAndWindow運算元的使用
阿新 • • 發佈:2018-12-15
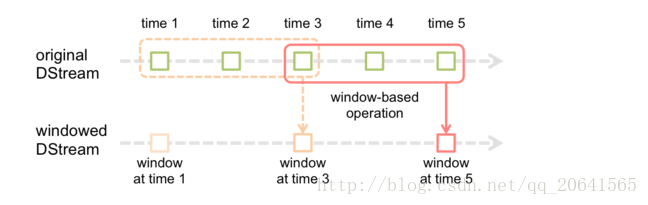
截圖自官網,例如每個方塊代表5秒鐘,上面的虛線框住的是3個視窗就是15秒鐘,這裡的15秒鐘就是視窗的長度,其中虛線到實線移動了2個方塊表示10秒鐘,這裡的10秒鐘就表示每隔10秒計算一次視窗長度的資料
舉個例子: 如下圖
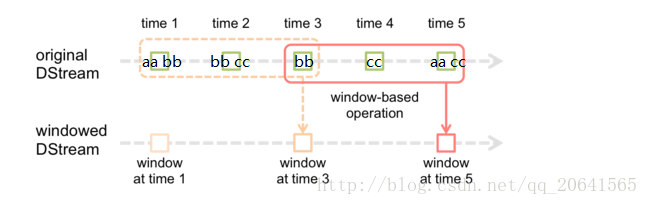
我是這樣理解的:如果這裡是使用視窗函式計算wordcount 在第一個視窗(虛線視窗)計算出來(aa, 1)(bb,3)(cc,1)當到達時間10秒後窗口移動到實線視窗,就會計算這個實線視窗中的單詞,這裡就為(bb,1)(cc,2)(aa,1)
附上程式:
注意:視窗滑動長度和視窗長度一定要是SparkStreaming微批處理時間的整數倍,不然會報錯.
package cn.lijie.kafka
import