
記憶體模型是怎麼解決快取一致性的
我們在文章中提到過,由於CPU和主存的處理速度上存在一定差別,為了匹配這種差距,提升計算機能力,人們在CPU和主存之間增加了多層快取記憶體。每個CPU會有L1、L2甚至L3快取,在多核計算機中會有多個CPU,那麼就會存在多套快取,那麼這多套快取之間的資料就可能出現不一致的現象。為了解決這個問題,有了記憶體模型。記憶體模型定義了共享記憶體系統中多執行緒程式讀寫操作行為的規範。通過這些規則來規範對記憶體的讀寫操作,從而保證指令執行的正確性。
不知道小夥伴們有沒有想過這樣的問題:記憶體模型到底是怎麼保證快取一致性的呢?
接下來我們試著回答這個問題。首先,快取一致性是由於引入快取而導致的問題,所以,這是很多CPU廠商必須解決的問題。為了解決前面提到的快取資料不一致的問題,人們提出過很多方案,通常來說有以下2種方案:
1、通過在匯流排加
LOCK#鎖的方式。2、通過快取一致性協議(Cache Coherence Protocol)。
在早期的CPU當中,是通過在總線上加LOCK#鎖的形式來解決快取不一致的問題。因為CPU和其他部件進行通訊都是通過匯流排來進行的,如果對匯流排加LOCK#鎖的話,也就是說阻塞了其他CPU對其他部件訪問(如記憶體),從而使得只能有一個CPU能使用這個變數的記憶體。在總線上發出了LCOK#鎖的訊號,那麼只有等待這段程式碼完全執行完畢之後,其他CPU才能從其記憶體讀取變數,然後進行相應的操作。這樣就解決了快取不一致的問題。
但是由於在鎖住匯流排期間,其他CPU無法訪問記憶體,會導致效率低下。因此出現了第二種解決方案,通過快取一致性協議來解決快取一致性問題。
快取一致性協議
快取一致性協議(Cache Coherence Protocol),最出名的就是Intel 的MESI協議,MESI協議保證了每個快取中使用的共享變數的副本是一致的。
MESI的核心的思想是:當CPU寫資料時,如果發現操作的變數是共享變數,即在其他CPU中也存在該變數的副本,會發出訊號通知其他CPU將該變數的快取行置為無效狀態,因此當其他CPU需要讀取這個變數時,發現自己快取中快取該變數的快取行是無效的,那麼它就會從記憶體重新讀取。
在MESI協議中,每個快取可能有有4個狀態,它們分別是:
M(Modified):這行資料有效,資料被修改了,和記憶體中的資料不一致,資料只存在於本Cache中。
E(Exclusive):這行資料有效,資料和記憶體中的資料一致,資料只存在於本Cache中。
S(Shared):這行資料有效,資料和記憶體中的資料一致,資料存在於很多Cache中。
I(Invalid):這行資料無效。
關於MESI的更多細節這裡就不詳細介紹了,讀者只要知道,MESI是一種比較常用的快取一致性協議,他可以用來解決快取之間的資料一致性問題就可以了。
但是,值得注意的是,傳統的MESI協議中有兩個行為的執行成本比較大。
一個是將某個Cache Line標記為Invalid狀態,另一個是當某Cache Line當前狀態為Invalid時寫入新的資料。所以CPU通過Store Buffer和Invalidate Queue元件來降低這類操作的延時。
如圖:
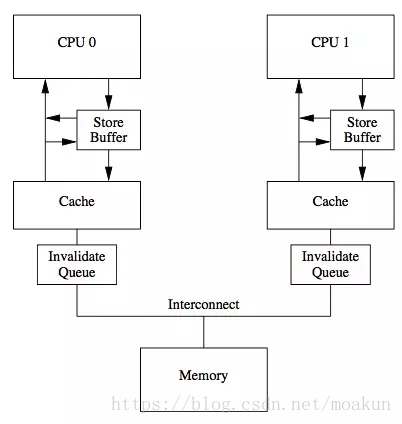
當一個CPU進行寫入時,首先會給其它CPU傳送Invalid訊息,然後把當前寫入的資料寫入到Store Buffer中。然後非同步在某個時刻真正的寫入到Cache中。
當前CPU核如果要讀Cache中的資料,需要先掃描Store Buffer之後再讀取Cache。
但是此時其它CPU核是看不到當前核的Store Buffer中的資料的,要等到Store Buffer中的資料被刷到了Cache之後才會觸發失效操作。
而當一個CPU核收到Invalid訊息時,會把訊息寫入自身的Invalidate Queue中,隨後非同步將其設為Invalid狀態。
和Store Buffer不同的是,當前CPU核心使用Cache時並不掃描Invalidate Queue部分,所以可能會有極短時間的髒讀問題。
所以,為了解決快取的一致性問題,比較典型的方案是MESI快取一致性協議。
MESI協議,可以保證快取的一致性,但是無法保證實時性。
記憶體模型
前面介紹過了快取一致性模型,接著我們再來看一下記憶體模型。我們說過記憶體模型定義一系列規範,來保證多執行緒訪問共享變數時的可見性、有序性和原子性。(更多內容請參考再有人問你Java記憶體模型是什麼,就把這篇文章發給他。)
記憶體模型(Memory Model)如果擴充套件開來說的話,通常指的是記憶體一致性模型(Memory Sequential Consistency Model)
前面我們提到過快取一致性,這裡又要說記憶體一致性,不是故意要把讀者搞蒙,而是希望通過對比讓讀者更加清楚。
快取一致性(Cache Coherence),解決是多個快取副本之間的資料的一致性問題。
記憶體一致性(Memory Consistency),保證的是多執行緒程式訪問記憶體時可以讀到什麼值。
我們首先看以下程式:
初始:x=0 y=0
Thread1:
S1:x=1
L1:r1=y
Thread2:
S2:y=2
L2:r2=x
其中,S1、S2、L1、L2是語句代號(S表示Store,L表示Load);r1和r2是兩個暫存器。x和y是兩個不同的記憶體變數。兩個執行緒執行完之後,r1和r2可能是什麼值?
注意到執行緒是併發、交替執行的,下面是可能的執行順序和相應結果:
S1 L1 S2 L2 那麼r1=0 r2=2
S1 S2 L1 L2 那麼r1=2 r2=1
S2 L2 S1 L1 那麼r1=2 r2=0
這些都是意料之內、情理之中的。但是在x86體系結構下,很可能得到r1=0 r2=0這樣的結果。
如果沒有Memory Consistency,程式設計師寫的程式程式碼的輸出結果是不確定的。
因此,Memory Consistency就是程式設計師(程式語言)、編譯器、CPU間的一種協議。這個協議保證了程式訪問記憶體時會得到什麼值。
簡單點說,記憶體一致性,就是保證併發場景下的程式執行結果和程式設計師預期是一樣的(當然,要通過加鎖等方式),包括的就是併發程式設計中的原子性、有序性和可見性。而快取一致性說的就是併發程式設計中的可見性。
在很多記憶體模型的實現中,關於快取一致性的保證都是通過硬體層面快取一致性協議來保證的。需要注意的是,這裡提到的記憶體模型,是計算機記憶體模型,而非Java記憶體模型。
總結
快取一致性問題。硬體層面的問題,指的是由於多核計算機中有多套快取,各個快取之間的資料不一致性問題。
PS:這裡還需要再重複一遍,Java多執行緒中,每個執行緒都有自己的工作記憶體,需要和主存進行互動。這裡的工作記憶體和計算機硬體的快取並不是一回事兒,只是可以相互類比。所以,併發程式設計的可見性問題,是因為各個執行緒之間的本地記憶體資料不一致導致的,和計算機快取並無關係。
快取一致性協議。用來解決快取一致性問題的,常用的是MESI協議。
記憶體一致性模型。遮蔽計算機硬體問題,主要來解決併發程式設計中的原子性、有序性和一致性問題。
實現記憶體一致性模型的時候可能會用到快取一致性模型。
思考
最後,再給大家留一道思考題:
既然在硬體層面,已經有了快取一致性協議,可以保證快取的一致性即併發程式設計中的可見性,那麼為什麼在寫多執行緒的程式碼的時候,程式設計師要自己使用volatile、synchronized等關鍵字來保證可見性?