
現代C語言程式設計之資料儲存
C語言
2.1 計算機資訊資料儲存
2.1.1 計算機資訊資料儲存單位
在計算機最底層,資料都是以二進位制(01010)的方式儲存,而計算機中最小的儲存單位是位(bit),用來表示0或者1。計算機中最基本的儲存單位是位元組(Byte),1個位元組對應8個位(Bit)。 而日常應用中常使用的基本儲存單位包括KB,MB,GB,TB,PB,
- KB,MB:使用迅雷下載某些資源時的網速就是KB或者MB,它們之間的換算關係如下
1MB=1024KB
1KB=1024B
1B=8bit
但是網路運營提供商(例如長城寬頻、移)聲稱的百兆頻寬實際上是100Mb,但是網路下載速度是以位元組為單位的,因此真實的網速理論上只有100Mb/8=12.5MB
- GB:在買記憶體或者買行動硬碟時,通常使用的儲存單位就是GB
1GB=1024MB
1TB=1024GB
但是在買4T的行動硬碟時,實際的可用容量卻只有3T多,因為計算機的儲存單位是以2的10次方(即1024)換算,而硬碟廠商們是以1000為換算單位。
4T的硬碟換算成位如下所示
4T=4*1024GB*1024MB*1024KB*1024B*8bit
而硬碟廠商的實際容量
4T=1000*1000*1000*1000*8
因此實際的可用容量是
4*1000*1000*1000*1000/1024/1024/1024/1024≈3.63T
而在一些網際網路巨頭(例如國內的BAT,國外的亞馬遜、蘋果、微軟、谷歌)公司中,可能使用到比TB更大的海量資料,也就是PB或者EB。
1PB=1024TB
1EB=1024PB
2.1.2 計算機記憶體
為什麼說32位系統只能使用4G記憶體?下面是4G的記憶體換算
4G=2^2 * 2^10 * 2^10 * 2^10 =4*1024*1024*1024=2^32
因為4G只能夠定址到2^32,使用16進製表示就是0xFFFFFFFF,這裡可以藉助Visual Studio的除錯功能檢視記憶體的定址,如下圖所示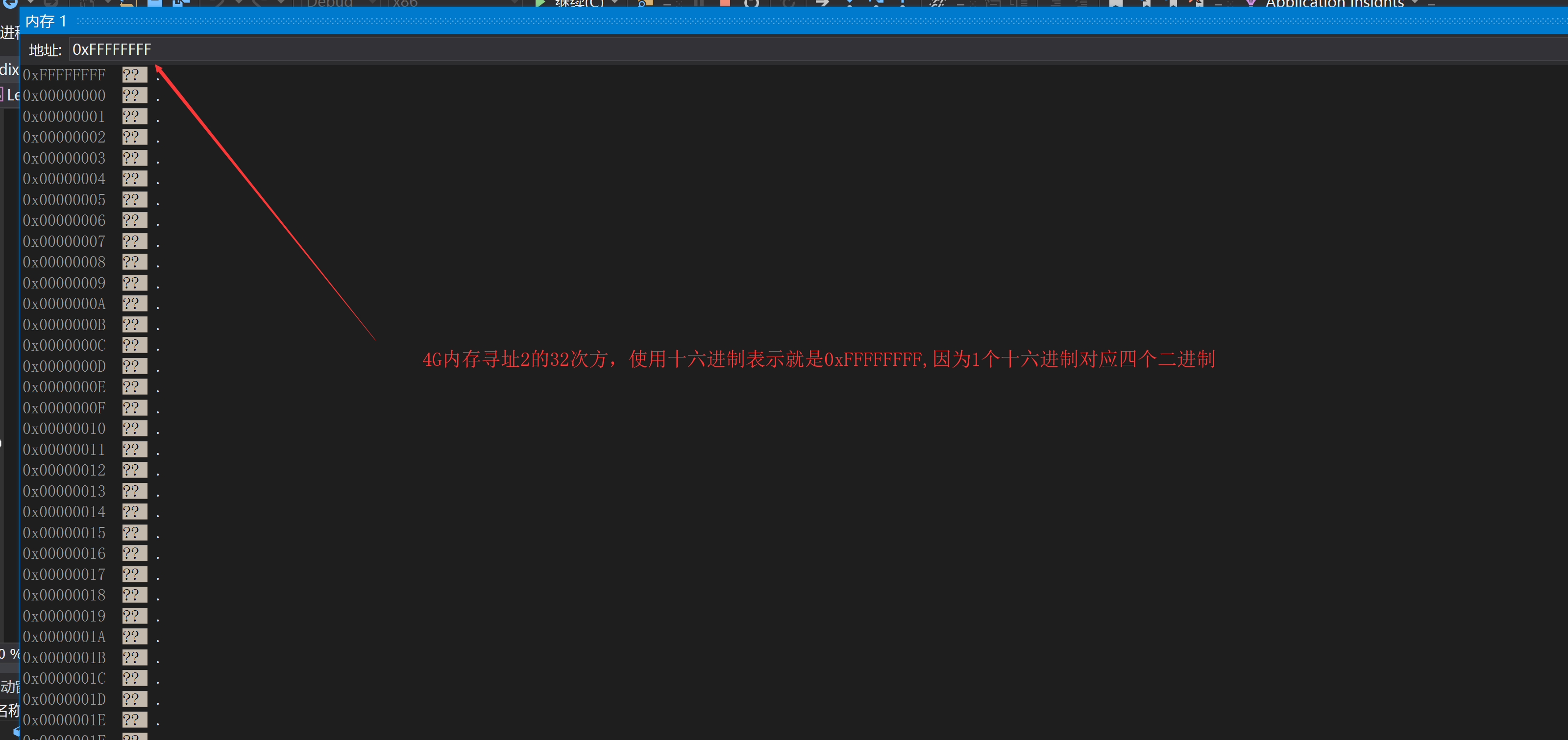
2.2 變數
2.2.1 變數概述
記憶體在程式看來就是有地址編號的一塊連續空間,當資料放到記憶體中後,為了方便的找到和操作這個資料,需要給這個位置起名字,程式語言通過變數來表示這個過程。
2.2.2 變數的宣告和初始化賦值
在使用變數前必須先要宣告變數並初始化賦值,並且要遵守變數的命名規範
- 變數名由字母數字下劃線組成,不能以數字開頭
- 變數名區分大小寫。
- 變數名不能是C語言的關鍵字(Visual Studio中的關鍵字都是藍色的)
- 考慮到軟體的可維護性,建議變數見名知意
如下應用案例所示展示了C語言的變數命名案例
#include <stdio.h>
#include <stdlib.h>
/*
變數的命名規範
*/
void main() {
//合法的識別符號
int number;
//見名知意
int age;
char ch;
double db;
//變數名不能是關鍵字
//int void;
//變數名不能以數字開頭
//int 1num;
/****************************************編譯器特性*******************************/
//VC支援中文變數,GCC不支援中文命名
int 年齡 = 29;
printf("年齡 =%d\n", 年齡);
//在老版(C++11之前)的編譯器中,變數宣告必須放在函式呼叫之前
/****************************************編譯器特性*******************************/
//宣告多個變數
int one, two, three;
system("pause");
}
在宣告變數後,一定要給變數賦初始值,否者無法編譯通過,如下應用案例所示
#include <stdio.h>
#include <stdlib.h>
/*
變數初始化賦值
在使用變數時必須手動初始化賦值,否則會得到一個隨機的垃圾值
*/
void main(){
int num;
//編譯錯誤錯誤 C4700 使用了未初始化的區域性變數“num”
printf("num =%d\n",num);
system("pause");
}
2.2.2 變數儲存
如下應用程式所示,通過"="可以給變數賦值,同時可以通過printf()函式傳遞%p引數來獲取變數在記憶體中的地址。
#include <stdio.h>
#include <stdlib.h>
/*
變數在記憶體中的儲存
*/
void main () {
int num = 20;
//檢視num的記憶體地址
printf("整數變數num的地址是%p\n", &num);
printf("整數變數num = %d\n", num);
num = 30;
printf("修改之後整數變數num的值是%d\n", num);
system("pause");
}
如下圖所示,還可以通過Visual Studio 提供的除錯功能通過斷點檢視變數在記憶體的儲存,通過輸入變數的記憶體地址便可以觀察變數對應的值。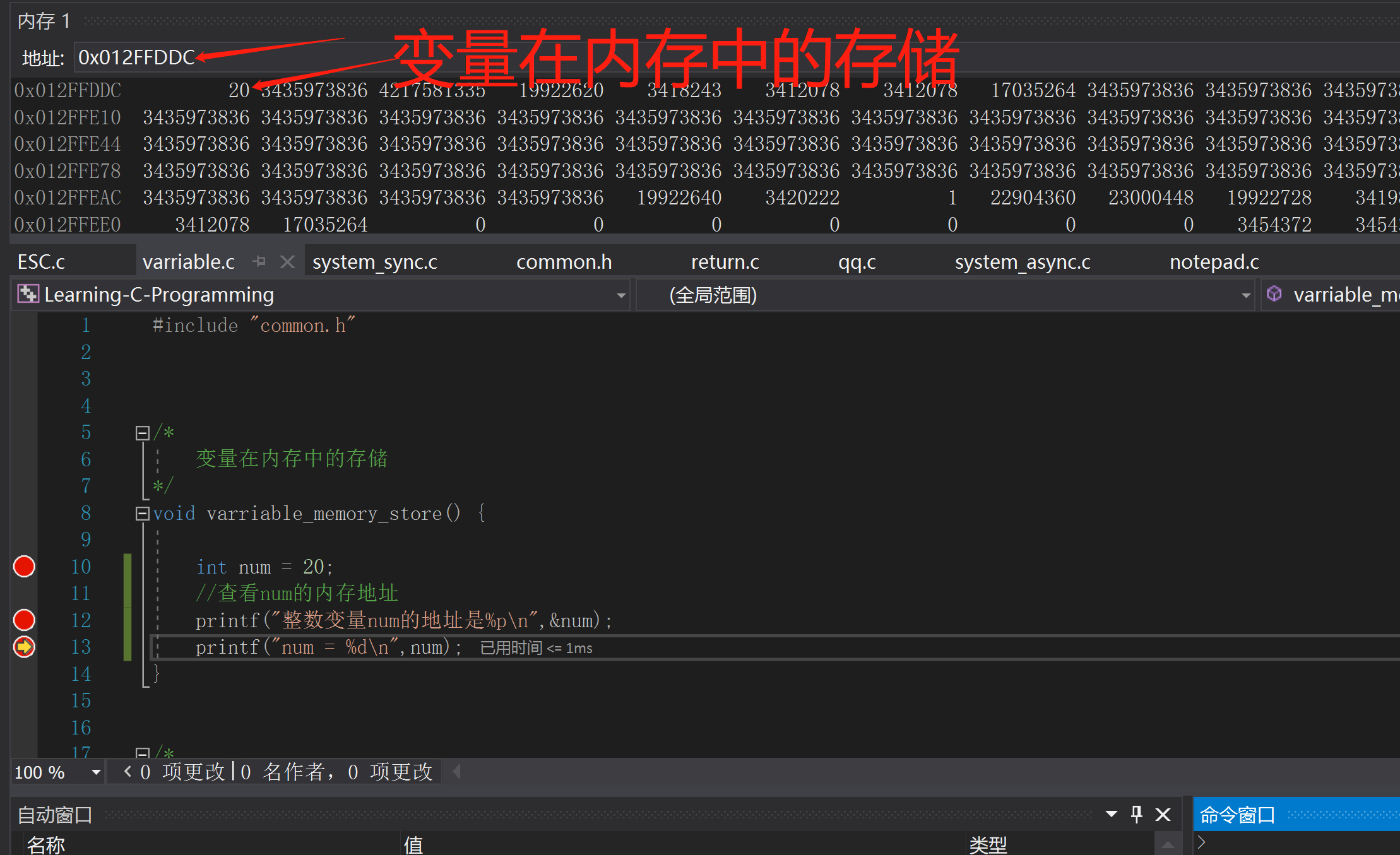 在同一時刻,記憶體地址對應的值只能儲存一份,如果修改地址對應的值,之前的值會被覆蓋,這個就是變數的特點,變數名是固定的,但是變數值在記憶體中是隨著業務邏輯在變化的,例如最常見的遊戲場景中,遊戲人物生命值的變化。
在同一時刻,記憶體地址對應的值只能儲存一份,如果修改地址對應的值,之前的值會被覆蓋,這個就是變數的特點,變數名是固定的,但是變數值在記憶體中是隨著業務邏輯在變化的,例如最常見的遊戲場景中,遊戲人物生命值的變化。
2.2.3 編譯器對變數的處理
當在程式中宣告變數並賦值時,編譯器會建立變量表維護變數的資訊,包括變數的地址,變數的型別以及變數的名稱。 而在記憶體中變數的記憶體地址和變數值是一一對應的,編譯器正是通過變量表的記憶體地址和記憶體中的變數地址關聯。因此在使用變數進行相關操作之前必須先宣告並賦值,否則程式會發生編譯錯誤,如下程式碼片段所示。
#include <stdio.h>
#include <stdlib.h>
/*
編譯器和記憶體對變數的處理
*/
void main(){
int a, b, c;
//不能使用未宣告的變數
printf(" %d\n",d);
system("pause");
}
2.2.4 變數運算的原理
當兩個變數在執行相關運算(例如加法)時,系統會將把兩個變數地址對應的變數值移動到CPU內部的暫存器中執行運算後將運算結果返回給記憶體,如下應用程式所示
#include <stdio.h>
#include <stdlib.h>
/*
變數運算的原理
*/
void main() {
int a = 1;
int b = 2;
//分配四個位元組的記憶體
int c;
printf("變數a的地址是%p\t,變數b的地址是%p\t,變數c的地址是%p\n",&a,&b,&c);
//資料的運算是在CPU的暫存器完成的
c = a + b;
c = b - a;
//對資料的操作是由CPU完成的
//a + 1 = 4;
printf("c=%d\n",c);
system("pause");
}
如下圖所示,可以藉助VisualStudio的除錯功能來觀察EAX暫存器的變化的值。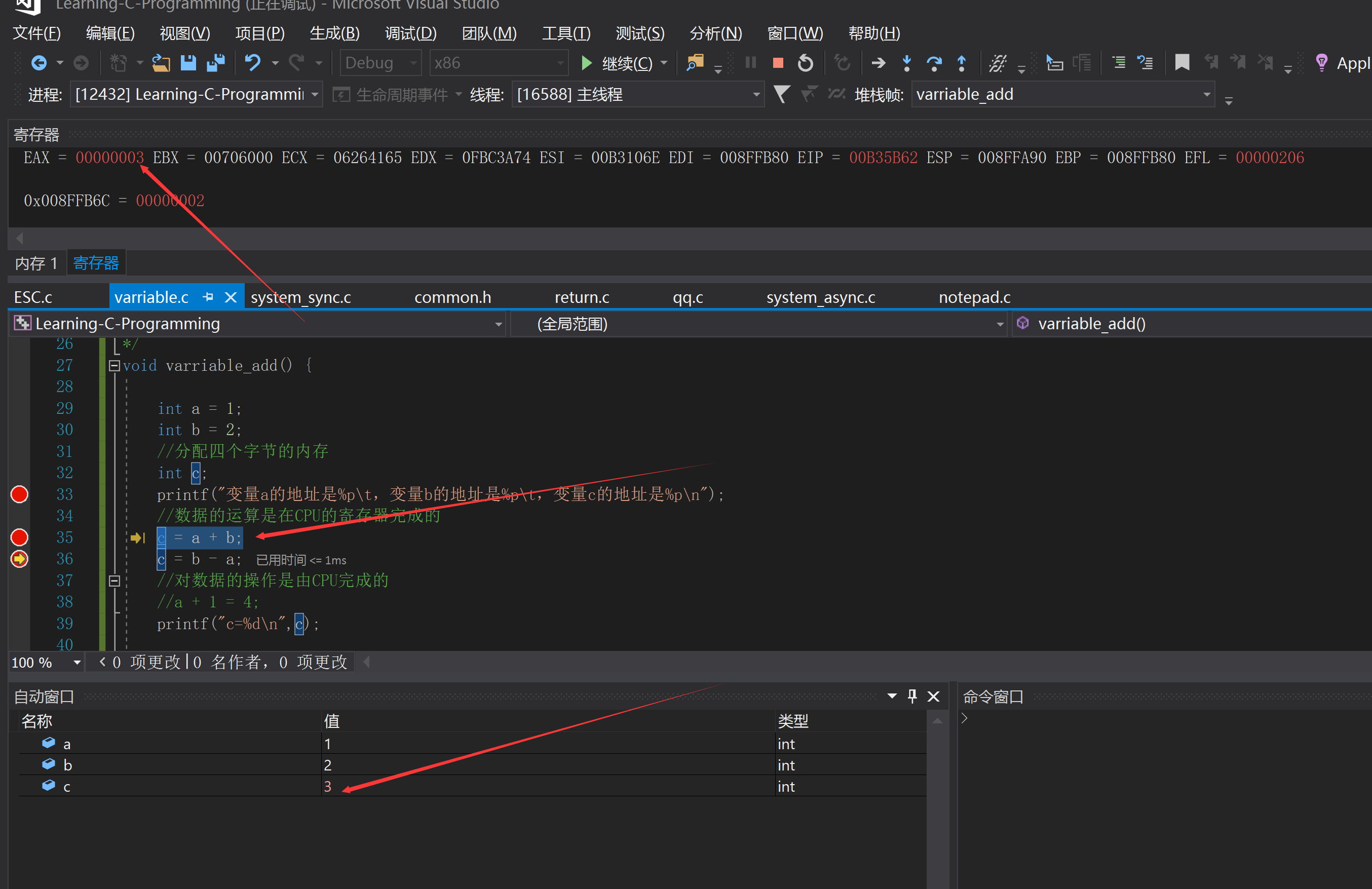
為了能夠更加直接的理解暫存器的作用,這裡使用C語言嵌套匯編語言來完成變數的賦值運算和加法運算。
#include <stdio.h>
#include <stdlib.h>
/*
使用匯編語言實現變數的賦值以及運算來理解資料的運算是在CPU內部的暫存器完成的
*/
void main() {
//申請四個位元組的記憶體
int a;
printf("整數變數a的地址是%p\n",&a);
//變數的賦值都是通過CPU的暫存器來完成的
//這裡藉助組合語言實現將10賦值給變數a
_asm {
mov eax, 10
mov a, eax
}
printf("整數變數a的值等於%d\n",a);
_asm {
//把變數a的值賦值給暫存器eax
mov eax,a
//將eax的值加5
add eax,5
//把eax的值賦值給a
mov a,eax
}
printf("變數a加5之後的結果是%d\n",a);
system("pause");
}
2.2.5 變數交換的實現
如下應用案例所示,實現了三種變數交換的演算法,同時也比較了每種演算法的時空複雜度,變數交換的應用場景主要在使用在排序演算法中。
1.通過使用中間變數實現交換
#include <stdio.h>
#include <stdlib.h>
/*
使用臨時變數實現變數交換
賦值運算三次
增加空間
*/
void varriable_swap_with_tmp(int left,int right) {
printf("使用臨時變數實現變數交換交換之前\t left=%d \t right=%d\n",left,right);
int middle = left;
left = right;
right = middle;
printf("使用臨時變數實現變數交換交換之後\t left=%d \t right=%d\n",left,right);
}
void main() {
int left = 5;
int right = 10;
varriable_swap_with_tmp(left,right);
system("pause");
}
- 使用算術運算實現變數交換
#include <stdio.h>
#include <stdlib.h>
/*
使用算術運算實現變數交換 考慮資料越界的問題
不需要開闢額外的空間
賦值運算三次,算術運算三次 總運算次數6次
*/
void varriable_swap_with_algorithm(int left,int right) {
printf("使用算術運算實現變數交換交換之前\t left=%d \t right=%d\n", left, right);
left = left + right; // 加號變成乘號
right = left - right;//減號變成除號
left = left - right; //減號變成除號
printf("使用算術運算實現變數交換交換之後\t left=%d \t right=%d\n", left, right);
}
void main() {
int left = 5;
int right = 10;
varriable_swap_with_algorithm(left,right);
system("pause");
}
- 使用異或運算實現變數交換
#include <stdio.h>
#include <stdlib.h>
/*
使用異或運算實現變數交換
不用考慮運算結果溢位的問題
*/
void varriable_swap_with_xor(int left, int right) {
printf("使用異或運算實現變數交換交換之前\t left=%d \t right=%d\n", left, right);
left = left ^ right;
right = left ^ right;
left = left ^ right;
printf("使用異或運算實現變數交換交換之後\t left=%d \t right=%d\n", left, right);
}
void main() {
int left = 5;
int right = 10;
varriable_swap_with_xor(left,right);
system("pause");
}
2.2.6 自動變數與靜態變數
在函式中的形式引數和程式碼塊中的區域性變數都是自動變數,它們的特點是隻有在定義的時候才會被建立(即系統自動開闢記憶體空間),在定義它們的函式返回時系統自動回收變數佔據的記憶體空間,為了考慮到程式碼的可讀性,通常使用auto關鍵字來修飾自動變數,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
自動變數:
只有定義它們的時候才建立,在定義它們的函式返回時系統回收變數所佔用的儲存空間,
對這些變數儲存空間的分配和回收由系統自動完成
一般情況下,不做專門說明的變數都是自動變數,自動變數也可以使用關鍵字auto說明
塊語句中的變數,函式的形式引數都是自動變數
*/
void auto_varriable(auto int num) { //num就是自動變數,函式呼叫的時候就存在,函式結束,變數會被作業系統自動回收,地址都是同一個地址,但是值在不斷髮生變化
printf("num的記憶體地址是%p\nnum的值是%d\n",&num,num);
auto int data = num;
printf("data的記憶體地址是%p\ndata的值是%d\n", &data, data);
}
/*
多次呼叫自動變數
*/
void invoke_auto_varriable() {
int num = 20;
auto_varriable(num);
printf("\n\n");
auto_varriable(80);
}
void main() {
invoke_auto_varriable();
system("pause");
}
可以通過下斷點來除錯該程式,觀察當執行auto_varriable()函式完成以後,區域性變數data將會被回收,如下圖所示 同時可以通過觀察記憶體地址,發現當呼叫auto_varriable()函式時,num=20
同時可以通過觀察記憶體地址,發現當呼叫auto_varriable()函式時,num=20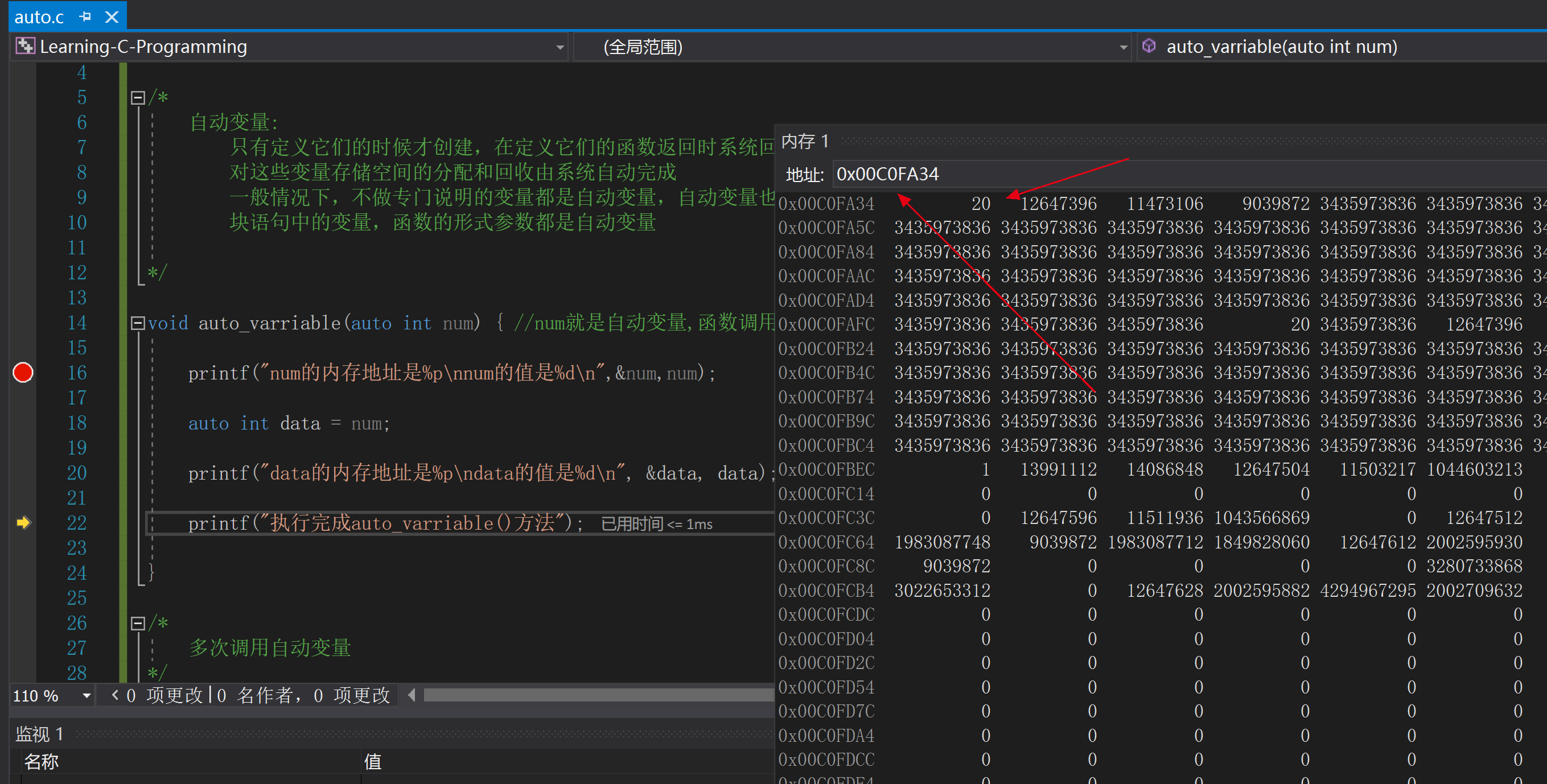 然後當執行完auto_varriable()函式後,num的值變數一個系統分配的垃圾值
然後當執行完auto_varriable()函式後,num的值變數一個系統分配的垃圾值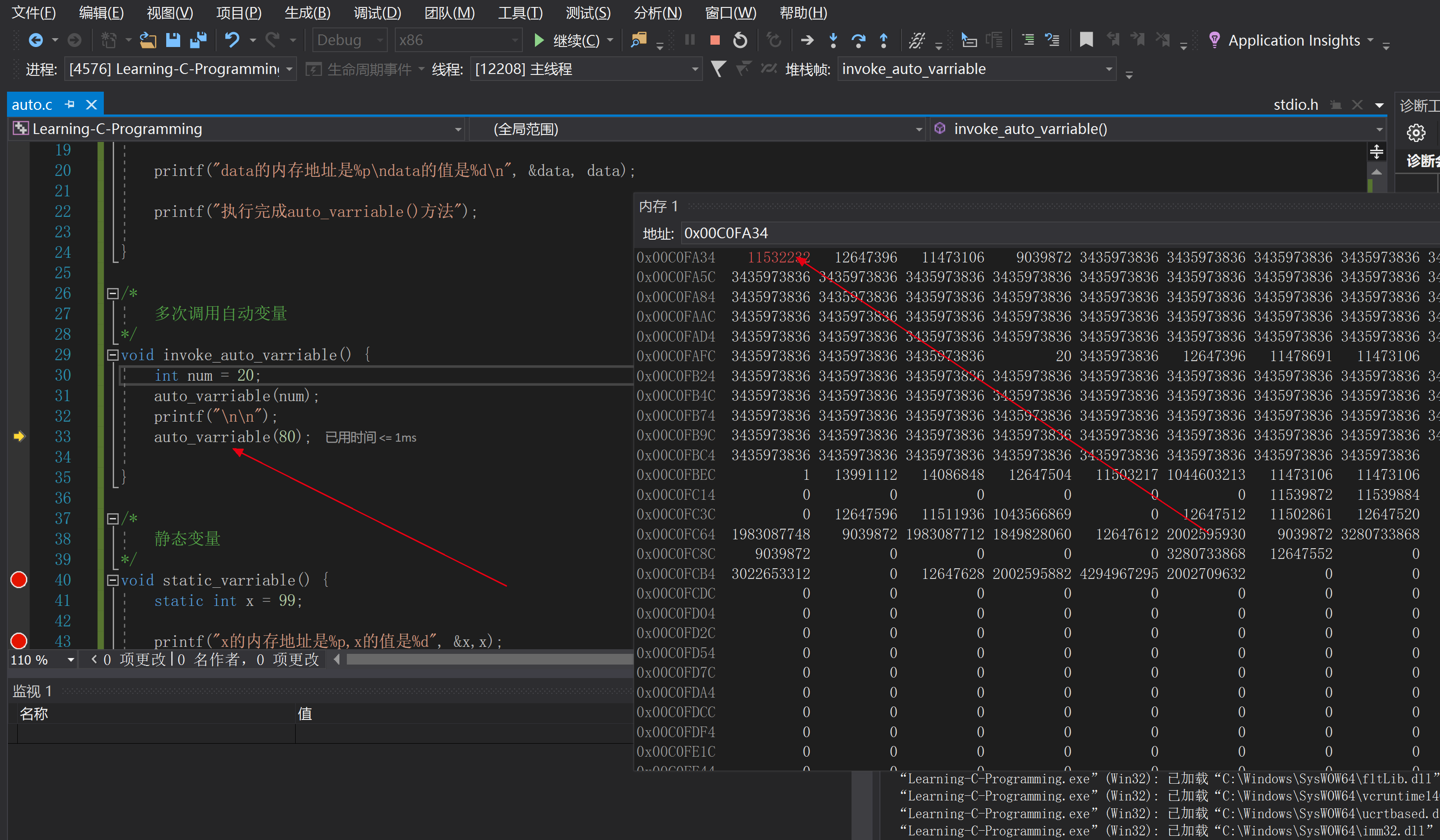
而靜態變數不會發生變化,即使函式執行完成也不會被作業系統回收,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
靜態變數
*/
void static_varriable() {
static int x = 99;
printf("x的記憶體地址是%p,x的值是%d", &x,x);
printf("\n\n");
}
/*
多次呼叫靜態變數
*/
void invoke_static_varriable() {
static_varriable();
printf("\n");
static_varriable();
}
void main() {
//invoke_auto_varriable();
invoke_static_varriable();
system("pause");
}
除錯以上應用程式,會發現直到main函式執行完成,靜態整數變數x都不會被作業系統回收。
2.3 常量
常量表示一旦初始化之後便不能再次直接改變的變數,例如人的身份證編號一旦確定之後就不會再次改變。C語言支援使用const關鍵字和#define CONST_NAME CONST_VALUE 兩種方式來定義和使用常量。
2.3.1 const常量
如果想要使一個變數變成常量,只需要在變數前面使用const關鍵字即可,const常量雖然不能直接修改,但是可以通過C語言的指標來修改,因此不是真正意義上的常量。,應用案例如下所示。
#include <stdio.h>
#include <stdlib.h>
/*
const常量不能直接修改值,但是可以通過指標修改值
*/
void main() {
//定義一個整數常量
const long id = 10000;
//不能直接修改常量
//id = 10001;
printf("常量id的地址是%p\n",&id);
printf("常量id=%d\n", id);
//通過指標修改
//* 根據地址取內容
//(int*) 型別轉換為非 常量型別
* (int*) (&id)= 10001;
printf("常量id=%d\n", id);
system("pause");
}
2.3.3 #define常量
在C語言中使用const定義的變數不能直接修改,但是可以通過指標來修改,因此不是真正意義上的常量。 如果想要使用真正意義上的常量,可以使用#define CONSTA_NAME VALUE 來實現,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
//#define語句不需要分號結尾,#define定義的常量值是在暫存器中產生,無法取記憶體地址,即無法通過C語言修改,
//因為C語言無法直接操作CPU的暫存器,只能操作記憶體。
#define CARD_NUMBER 88888888
void main() {
printf("CARD_NUMBER=%d\n",CARD_NUMBER);
system("pause");
}
使用#define定義常量的好處:
- 通過有意義的常量名,可以指定該常量的意思,使得開發人員在越多程式碼時減少迷惑
- 常量可以在多個方法中使用,如果需要修改常量,只需要修改一次便可實現批量修改,效率高而且準確。
#include <stdio.h>
#include <stdlib.h>
/*
在自定義方法中使用常量
*/
void use_card_number_const() {
printf("在自定義方法中使用CARD_NUMBER常量的值=%d\n", CARD_NUMBER);
}
void main(){
use_card_number_const();
system("pause");
}
#define的應用場景: 實現程式碼混淆
首先在define.h標頭檔案中定義如下常量
#define _ void
#define __ main()
#define ___ {
#define ____ system("notepad");
#define _____ system("pause");
#define ______ }
然後定義define.c原始檔,內容如下
#include "define.h"
_ __ ___ ____ _____ ______
執行程式後,可以開啟記事本。
2.4 資料型別
2.4.1 sizeof()運算子
資料型別即對資料進行分類,資料在計算機底層是二進位制的,不太方便操作,因此程式語言引入了資料型別將其進行分類處理。
不同的資料型別佔據不同的記憶體大小,這裡可以使用C語言提供的sizeof()運算子來獲取指定資料型別佔據的位元組數量,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
使用sizeof()關鍵字獲取指定資料型別的大小
*/
void main() {
printf("char佔據的位元組數量是%d\n", sizeof(char));
printf("short佔據的位元組數量是%d\n", sizeof(short));
printf("int佔據的位元組數量是%d\n", sizeof(int));
printf("double佔據的位元組數量是%d\n", sizeof(double));
system("pause");
}
當然sizeof()還可以求表示式的資料型別,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
使用sizeof求表示式的記憶體大小
*/
void main() {
int num = 10;
printf("字串str佔據的位元組數量是%d\n",sizeof("str"));//4個位元組 字串以\0結束
char ch = 'A';
printf("字元變數ch佔據的位元組數量是%d\n",sizeof(ch));
printf("字元常量A佔據的位元組數量是%d\n",sizeof('A'));
printf("整數變數num佔據的位元組數量是%d\n",sizeof(num));
system("pause");
}
3.4.2 資料的解析
同樣的資料,按照不同的解析方式會得到不同的結果,如下應用案例所示
#include <stdio.h>
#include <stdlib.h>
void main() {
//同樣的數使用不同的方式解析獲取不同的結果
int num = -1;
printf("num = %p\n",&num);
getchar();
system("pause");
}
啟動程式除錯,通過檢視控制檯輸出num變數的地址,然後在記憶體中分別以1位元組帶符號整數檢視結果為-1,8位元組整數檢視結果為14757395259826634751,1位元組不帶符號顯示(結果為255),如下圖所示,不同的方式檢視通過滑鼠右鍵獲取。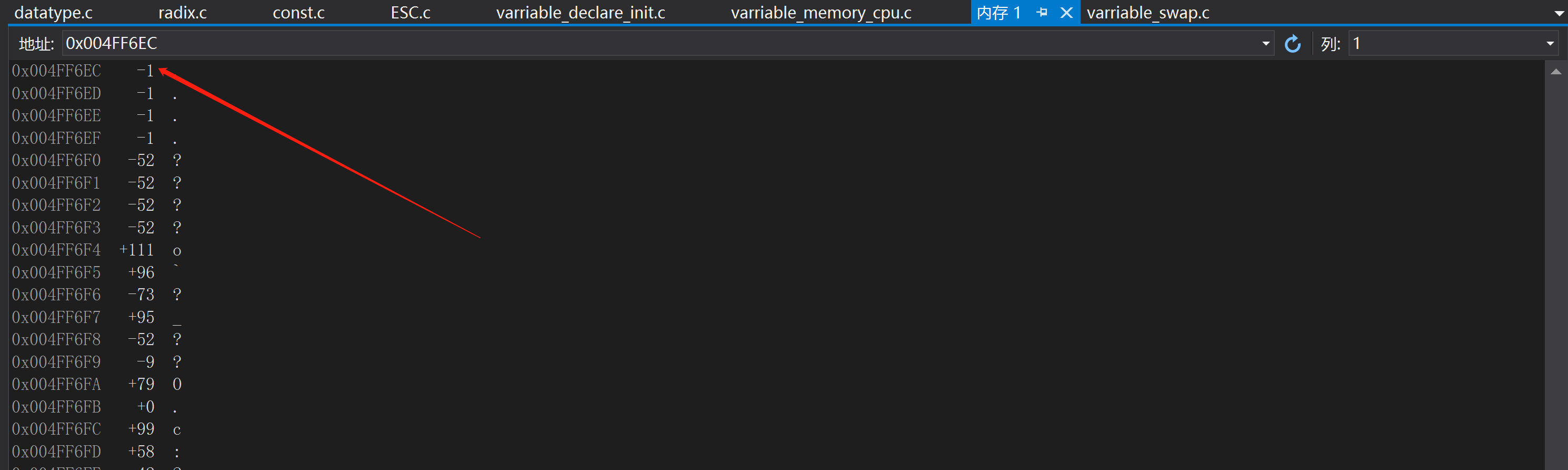
而如果資料使用了錯誤的解析方式,則結果也會發生錯誤,這裡以printf()函式為例子,應用案例如下所示。
#include <stdio.h>
#include <stdlib.h>
/*
printf解析資料型別
*/
void main() {
//printf函式不會進行型別轉換,當型別不匹配輸出就是錯誤的結果
int num = 10;
printf("num =%f\n",num);//如果想要獲取正確的結果需要收到強制型別轉換(float)num
//浮點數按照整數解析,結果會出錯
float fl = 10.9;
printf("fl=%d\n",fl);//如果想要獲取正確的結果需要收到強制型別轉換(int)fl
system("pause");
}
2.4.3 資料型別的極限
每種資料型別都有自己的極限值(即最大值和最小值),如果在參與運算時超過了極限值,則運算結果是錯誤的,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
/*
unsigned char
*/
void main() {
//為了保證結果運算正確,必須在極限範圍之內
unsigned char chnum = 255;
printf("無符號char所能儲存的最大值是%d\n", UCHAR_MAX);
printf("chnum=%d",chnum); //結果為0 因為chnum所能表示的最大值為255,這裡發生了越界,結果錯誤
system("pause");
}
整數的極限值定義在<limits.h> 標頭檔案中,
浮點數的極限值定義在<float.h>標頭檔案中,
如下應用案例所示展示了整數以及浮點數的極限值使用。
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <float.h>
/*
整數的極限
*/
void int_limt() {
printf("int所能儲存的最大值是%d,int所能儲存的最小值是%d\n", INT_MAX, INT_MIN);
}
/*
float的極限
*/
void float_limit() {
printf("float所能儲存的最大值是%e,float所能儲存的最小值是%e\n", FLT_MAX, FLT_MIN);
printf("double所能儲存的最大值是%e,float所能儲存的最小值是%e\n", DBL_MAX, DBL_MIN);
}
void main() {
int_limt();
float_limit();
system("pause");
}
2.4.4 資料的正負
在最底層,計算機的資料都是以二進位制的形式表示的,那麼如何區分正負數呢? 最高位(左邊第一位)是符號位,如果是1,則表示為負數,如果是0則表示正數。 如下應用案例所示
#include <stdio.h>
#include <stdlib.h>
/*
char型別二進位制表示方式
*/
void main() {
char ch = -1; //十六進位制表示為ff 轉換為二進位制 1111 1111 最高位(左邊第一個數字)為符號位,1表示負數
char chx = 3; //十六進位制為03 轉換為二進位制為 0000 0011 最高為(左邊第一個數字)為符號位,0表示整數
printf("字元變數ch的地址是%p,字元變數chx變數的地址是%p\n",&ch,&chx);
printf("ch=%d\tchx=%d\n",ch,chx);
system("pause");
}
如下圖所示,可以通過Visual Studio的除錯功能檢視兩個變數在記憶體中的儲存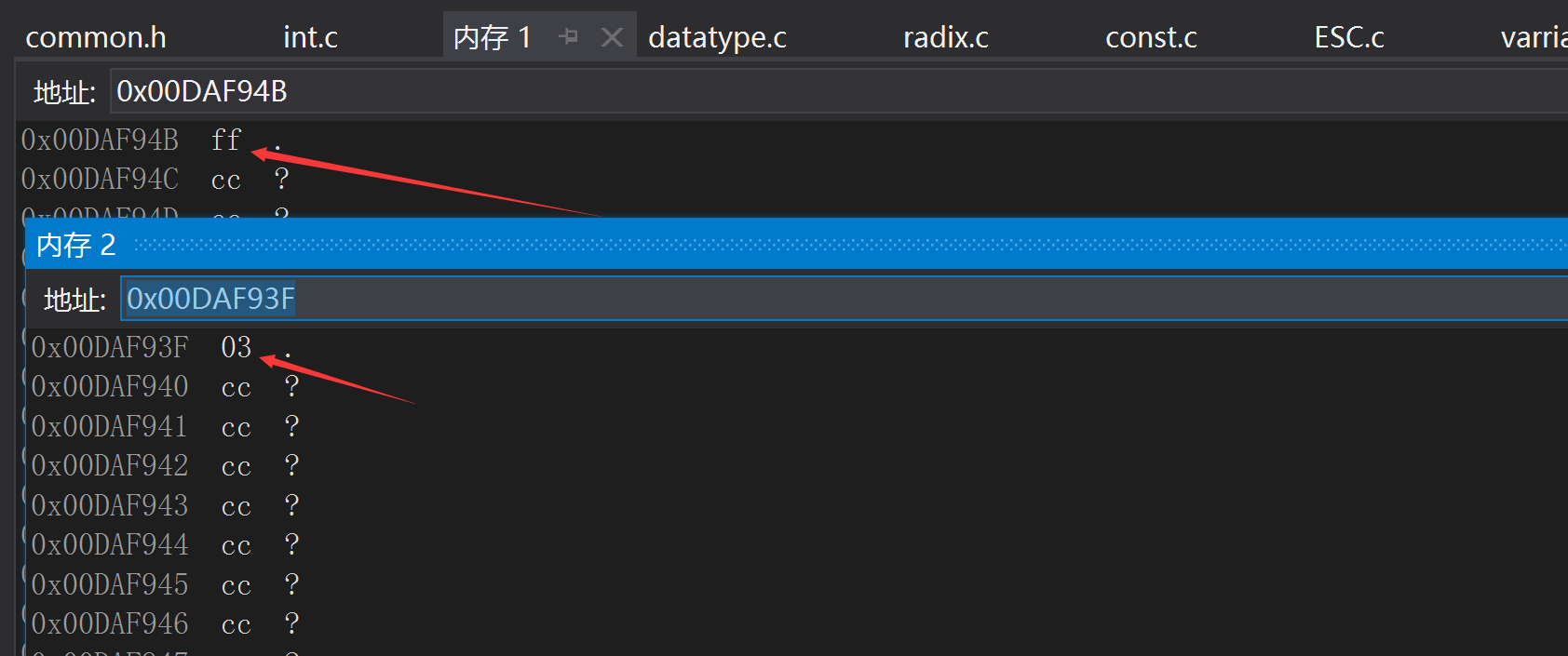
2.4.5 資料在記憶體中的排列
PC、手機的記憶體排列是低位在低位元組,高位在高位元組,節省定址時間。 如下應用程式所示
#include <stdio.h>
#include <stdlib.h>
/*資料在記憶體中的排列
低位在低位元組,高位在高位元組
*/
void main() {
// 四位元組二進位制方式 0000 0000 0000 0000 0000 0000 0000 0001
int num = 1;
printf("num的地址是%p\n",&num);
printf("num = %d\n",num);
system("pause");
}
可以通過Visual Studio 下斷點除錯程式,使用1位元組檢視整數1在記憶體中的排列,如下圖所示:

資料在記憶體中的排列
而Unix等大型伺服器的記憶體排列都是低位在高位元組。
2.5 原碼、反碼、補碼的計算
| 原碼 | 反碼 | 補碼 | |
|---|---|---|---|
| +7 | 00000111 | 00000111 | 00000111 |
| -7 | 10000111 | 11111000 | 11111001 |
| +0 | 00000000 | 00000000 | 00000000 |
| -0 | 10000000 | 11111111 | 00000000 |
| 數的取值範圍 | -127-127 | -127-127 | -128-127 |
從上面的表格可以看出,正數的原碼、反碼和補碼都相同,而負數的補碼就是原碼取反(最高位不變,其他位取反)後加1的結果。
而實際資料在計算機(手機、電腦、伺服器)的記憶體中也是以補碼的形式儲存資料的,如下應用案例所示
#include <stdio.h>
#include <stdlib.h>
/*
計算機最底層都是以補碼儲存資料的
*/
void main() {
//原碼 10000111
//反碼 11111000
//補碼 1111 1001 F9
char ch = -7;
printf("ch的地址是%p\n",&ch);
printf("ch=%d\n",ch);
system("pause");
}
首先需要計算出-7的補碼,然後轉換為16進位制的結果為F9,然後通過Visual Studio的除錯功能檢視記憶體的儲存結果,如下圖所示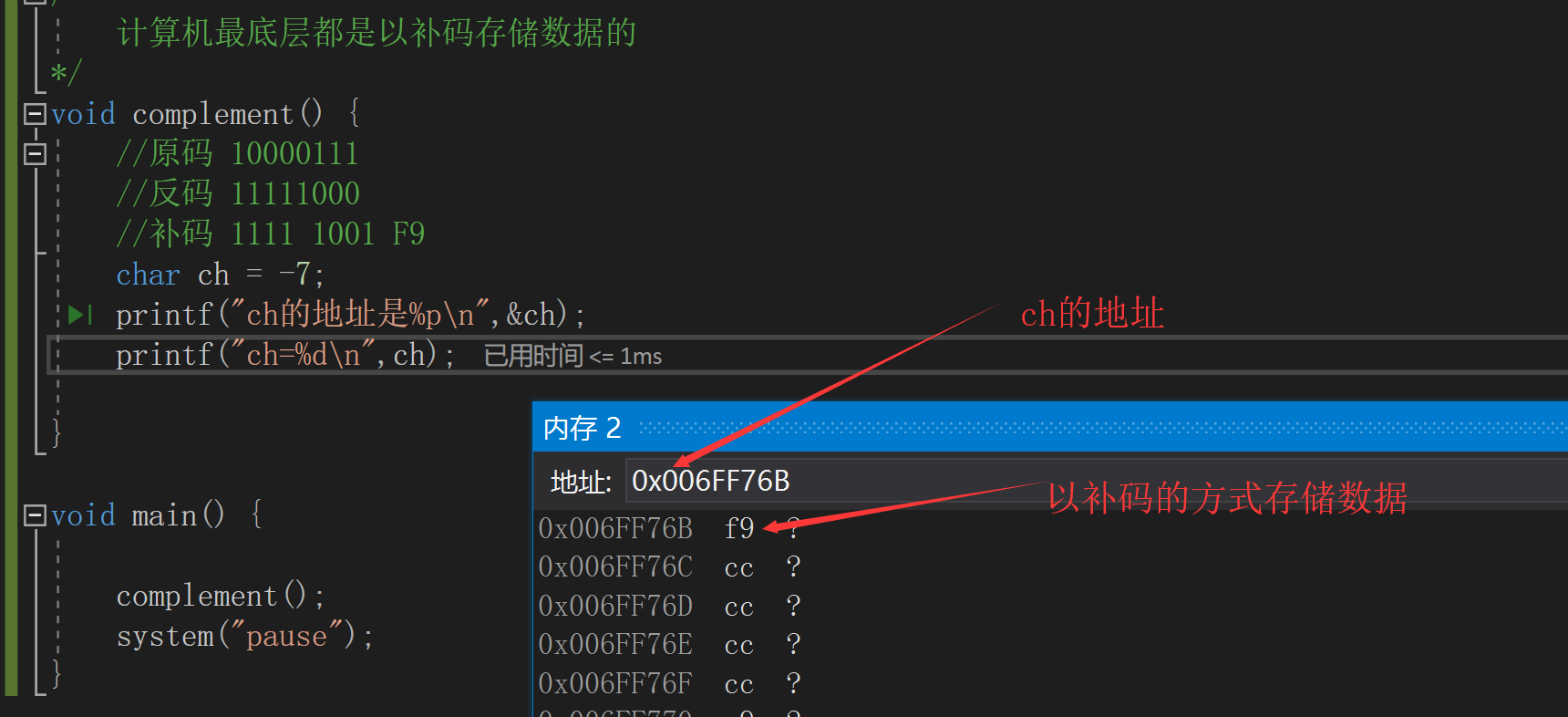
2.6 整數
2.6.1 整數常量
C語言整數常量可以使用八進位制,十進位制和十六進位制表示。它們在計算時遵循逢R進1,借1當R。如下表格所示展示了它們的組成部分和應用場景。
| 進位制型別 | 組成部分 | 應用場景 |
|---|---|---|
| 二進位制 | 0或者1 | 底層資料儲存 |
| 八進位制 | 0-7之間的8個整數 | Linux許可權系統 |
| 十進位制 | 0-9之間的10個整數 | 整數的預設進位制型別 |
| 十六進位制 | 0-9,a-f 之間的十個整數加上六個字母 | 記憶體地址 |
同時可以使用u字尾表示位無符號整數,使用l字尾表示long型別的整數,使用ll字尾表示為long long型別的整數,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
整數的三種進位制型別
整數的三種字尾 無符號,長整數,長長整數
*/
void main() {
int a1 = 10;
int a2 = 010;
int a3 = 0x10;
int a4 = 101u; //無符號
int a5 = 102l;//long
int a6 = 103ll;//long long
printf("a1 = %d\ta2 = %d\ta3 = %d\ta4 = %d\ta5 = %d\ta6 = %d\t",a1,a2,a3,a4,a5,a6);
system("pause");
}
2.6.2 整數極限
而且整數按照佔據不同的位元組大小可以分為short,int,long和long long 四種類型,它們預設是有符號(signed)型別用於儲存正負數,而對應的無符號型別則用來儲存非負數的整數,關於它們能夠儲存資料的極限以及佔據記憶體的大小如下應用程式所示。
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
/*
C語言不同型別整數的極限
佔據不同位元組大小的整數極限也不一樣
*/
void main() {
//16位(嵌入式系統) int和short是等價的
printf("short能儲存的最大值是%d\tshort能儲存的最小值是%d,佔據的位元組數量是%d\n", SHRT_MAX, SHRT_MIN,sizeof(short));
printf("unsigned short能儲存的最大值是%d\n", USHRT_MAX);
//32位和64位系統 int和long是等價的
printf("int能儲存的最大值是%d\tint能儲存的最小值是%d,佔據的位元組數量是%d\n", INT_MAX, INT_MIN,sizeof(int));
printf("unsigned int能儲存的最大值是%d\n", UINT_MAX);
//無符號的整數 最小值都是0 即不能表示負數
printf("long能儲存的最大值是%d\tlong能儲存的最小值是%d,佔據的位元組數量是%d\n", LONG_MAX, LONG_MIN,sizeof(long));
printf("long long能儲存的最大值是%lld\tlong long能儲存的最小值是%lld,佔據的位元組數量是%d\n", LLONG_MAX, LLONG_MIN,sizeof(long long));
printf("unsigned long long 能儲存的最大值是%llu\n", ULLONG_MAX);
system("pause");
}
2.6.3 long long型別的整數
在應用開發時需要主要使用資料型別的極限,如果超越資料儲存範圍的極限,程式會出現Bug,例如想要儲存QQ或者手機號就應該使用無符號的long long 型別,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
long long 的應用場景
*/
void main() {
unsigned long long mobilePhone = 18601767221;
printf("mobilePhone=%llu\n",mobilePhone);
unsigned long long qq = 1079351401;
printf(" qq = %llu",qq);
system("pause");
}
2.6.4 整數的越界
在使用整數參與運算時,需要考慮到資料範圍對應的極限,否則會發生錯誤的結果,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
unsigned short
*/
void main() {
//為了保證結果運算正確,必須在極限範圍之內
unsigned short int shortnum = 65536;
printf("無符號short int所能儲存的最大值是%d\n", USHRT_MAX);
printf("shortnum=%d", shortnum); //結果為0 因為chnum所能表示的最大值為255,這裡發生了越界,結果錯誤
system("pause");
}
2.6.5 跨平臺的整數
C語言是在使用標準庫的前提下是可移植的,但是C語言的整數在不同的平臺上,同樣的資料型別佔用的位元組大小是不一樣的。例如int在16位系統佔據2個位元組,在32位及其以上系統佔據四個位元組,long在Windows平臺上,無論是32位還是64位都是佔四個位元組,而在64位ubuntu下卻佔據8個位元組,應用案例如下所示
Linux版
#include <stdio.h>
int main(){
long num=100;
int size=sizeof(num);
printf("ubuntu 64位系統中 long佔據的位元組數量是%d",size);
return 0;
}
Windows版
#include <stdio.h>
void main() {
long val = 100;
printf("windows下long佔據的位元組數量是%d\n", sizeof(val));
getchar();
}
為了解決不同平臺,相同的型別佔據的大小不一致的問題,C語言標準委員會在C99標準中提出了跨平臺的整數,在<stdint.h>標頭檔案中定義,意味著同樣的型別在不同的系統下的大小是一致的,應用案例如下所示
linux版
#include <stdio.h>
#include <stdint.h>
int main(){
long num=100;
int int_size=sizeof(num);
printf("ubuntu 64位系統中 long佔據的位元組數量是%d",int_size);
//在不同的平臺下佔據都是32位元組
int32_t int_32_MAX_VALUE = INT32_MAX;
int int32_size=sizeof(int32_t);
printf("sizeof(int_32_MAX_VALUE ) = %d\n",int32_size);
printf("int_32_MAX_VALUE = %d\n", int_32_MAX_VALUE);
//在不同的平臺下佔據都是64位元組
int64_t int_64_MAX_VALUE = INT64_MAX;
int int64_size=sizeof(int64_t);
printf("sizeof(int_64_MAX_VALUE ) = %d\n", int64_size);
printf("int_64_MAX_VALUE = %ld\n", int_64_MAX_VALUE);
return 0;
}
windows版
#include <stdio.h>
#include <stdint.h>
/*
不同的平臺,不同的編譯器,同樣的資料型別大小不一樣。
例如int 16位的情況下是2個位元組,32位系統是4個位元組
long型別在windows上無論是32位還是64位都是4個位元組,而在64位linux上long佔據的是8個位元組
為了解決這個問題,C語言標準組織在C99標準中提出了跨平臺的整數,也就是著不同平臺的整數佔用的位元組數量是一樣的,VS2013+,GCC都支援該標準
*/
void main() {
long val = 100;
printf("windows下long佔據的位元組數量是%d\n", sizeof(val));
//在不同的平臺下佔據都是32位元組
int32_t int_32_MAX_VALUE = INT32_MAX;
printf("sizeof(int_32_MAX_VALUE ) = %d\n",sizeof(int_32_MAX_VALUE));
printf("int_32_MAX_VALUE = %d\n", int_32_MAX_VALUE);
//在不同的平臺下佔據都是64位元組
int64_t int_64_MAX_VALUE = INT64_MAX;
printf("sizeof(int_64_MAX_VALUE ) = %d\n", sizeof(int_64_MAX_VALUE));
printf("int_64_MAX_VALUE = %lld\n", int_64_MAX_VALUE);
getchar();
}
2.7 浮點數
2.7.1 浮點數常量
浮點數就是數學意義上的小數,C語言中分別使用float,double和long double表示,預設型別是double,浮點數的常量可以使用十進位制的小數和科學計數法表示,科學計數法可以儲存特大或者特小的數字,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
浮點數兩種常量表示方法
*/
void main() {
//十進位制
float flt = 12.0f; //小數後面加f表示float型別
double dbl = 12.0; //小數預設是double型別
//科學計數法
double db1 = 0.12e3;
//e之前必須有數字,指數必須為整數
double db2 = 12000.124e5; //e5表示10的5次方
//%f預設輸出小數點後六位
printf("flt = %f \n",flt);
printf("db1 = %f \t db2 = %f\n",db1,db2);
getchar();
}
2.7.2 浮點數極限
C語言在limits.h的標頭檔案中使用常量定義了float和double的極限值,我們可以嘗試使用printf函式輸出該結果,分別保留 800和1500位小數。
#include <stdio.h>
#include <float.h>
/*
浮點數極限
*/
void main() {
//float佔據四個位元組,double佔據8個位元組long double 大於等於double
printf("float佔據的位元組數量是%d\tdouble佔據的位元組數量是%d long double佔據的位元組數量是%d\n\n\n\n\n",sizeof(float),sizeof(double),sizeof(long double));
printf("float能儲存的最大值是%.100f\tfloat能儲存的最小值是%.100",FLT_MAX,FLT_MIN);
printf("\n\n\n\n\n\n\n\n");
printf("double能儲存的最大值是%.1500f\n\n\n\n double能儲存的最小值是%.1500f\n",DBL_MAX,DBL_MIN);
getchar();
}
2.7.3 賦值時自動型別轉換
在進行賦值運算時會發生自動型別轉換,例如把一個double型別的常量10.5賦值給float型別的變數,它們佔據的位元組數量不同,但是能夠賦值成功,因為發生了自動型別轉換,應用案例如下所示。
#include <stdio.h>
#include <stdlib.h>
/*
賦值運算會發生自動型別轉換
*/
void main() {
float flt = 10.5;
//程式輸出結果顯示flt和10.5佔據的位元組數量不同,因為這裡發生了資料型別轉換
printf("flt佔據的位元組數量為%d\t 10.5佔據的位元組數量為%d", sizeof(flt), sizeof(10.5));
int num = 5 / 3;
printf(" num = %d\n",num);
int val = 3.2;
printf(" val =%d",val);
getchar();
}
2.7.4 浮點數相等性判斷
float佔據四個位元組,提供的有效位是6-7位,而double佔據八個位元組,提供的有效位數是15-16位,如果在使用float或者double表示實數時超過有效數字,若拿來進行關係運算(例如等於)的話,會得到一個錯誤的結果,應用案例如下所示
/*
浮點數的相等性判斷
如果實數超過有效範圍,使用==判斷會出錯
*/
void float_equals() {
float flt1 = 1.00000000001;
float flt2 = 1.00000000000000000001;
//因為float的有效數字是6-7位 這裡超出有效數字 計算不準確
printf(" flt1 == flt2 ? %d\n", (flt1 == flt2)); // 輸出結果1表示相等 0則表示不相等
//double精確的有效位數是15-16位,這裡也超出了有效數字,計算不夠正確
double db1 = 1.00000000000000000000000000000001;
double db2 = 1.000000000000000000000000000000000000000000000000000000000000000000000000000000001;
printf(" db1 == db2 ? %d\n", (db1 == db2)); // 輸出結果1表示相等 0則表示不相等
}
void main() {
float_equals();
getchar();
}
2.7.5 浮點數記憶體儲存原理
int和float同樣佔據四個位元組的記憶體,但是float所能表示的最大值比int大得多,其根本原因是浮點數在記憶體中是以指數的方式儲存。 我們都知道在記憶體中,一個float型別的實數變數是佔據32位,即32個二進位制的0或者1組成
高位 低位
0000 0000 0000 0000 0000 0000 0000 0000
如上程式碼片段所示,從低位依次到高位叫第0位和第31位,這32位可以由三部分組成:
- 符號位:第31位數表示符號位,如果為0表示整數,如果為1表示負數
- 階碼:第23位到第30位,這8個二進位制表示該實數轉化為規格化的二進位制實數後的指數與127(127即所謂的偏移量)之和所謂階碼,規格化的二進位制實數只能在-127-127之間。
- 尾數:第0位到第22位,最多可以表示23位二進位制小數,否則超過了就會產生誤差。
應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
浮點數在記憶體中的儲存
*/
void main() {
//符號位(31位) 階碼(第30位-23位) 尾數(第22位-第0位)
float flt1 = 10.0; //4位元組十六進位制 41200000 二進位制 0 100 00001 010 0000 0000 0000 0000 0000
float flt2 = -10.0;//4位元組十六進位制 c1200000 二進位制 1 100 00010 010 0000 0000 0000 0000 0000
printf(" flt1的記憶體地址是%p\tflt2的記憶體地址是%p\n", &flt1, &flt2);
float flt3 = 20.0; // 位元組十六進位制 41a00000 二進位制 0 100 0001 1010 0000 0000 0000 0000 0000
printf("變數flt3的地址是%p", &flt3);
getchar();
}
2.7.6 浮點數應用案例
使用math.h標頭檔案中的sqrt函式實現給定三角形三邊的面積計算
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
/*
根據給出的邊長求面積
使用math.h檔案中提供的開平方根函式
*/
void main() {
int a = 6;
int b = 8;
int c = 10;
int p = (a + b + c) / 2;
//sqrt返回float,這裡使用賦值運算完成了型別轉換
int s =sqrt( p * (p - a)*(p - b)*(p - c));
printf("s = %d",s);
printf("三角形的面積是%d",s);
printf("三角形的面積是%f", sqrt(p * (p - a)*(p - b)*(p - c)));
getchar();
}
使用math.h的pow函式實現中美GDP計算,並計算出中國GDP超過美國GDP的年份
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
/*
使用math.h的pow函式實現中美GDP計算,並計算出中國GDP超過美國GDP的年份
*/
void main() {
double ch_current_gdp = 12.0;
double us_current_gdp = 19.70;
double ch_rate = 1.06;
double us_rate = 1.04;
double ch_gdp;
double us_gdp;
int year;
for (int i = 1; i <= 100;i++) {
ch_gdp = ch_current_gdp * pow(ch_rate, i);
us_gdp = us_current_gdp * pow(us_rate, i);
year = 2017 + i;
printf("%d年中國的GDP是%f\n",year,ch_gdp);
printf("%d年美國的GDP是%f\n",year, us_gdp);
if (ch_gdp>us_gdp) {
printf("在%d年,中國的GDP超越了美國的GDP",year);
break;
}
}
getchar();
}
2.8 字元與字串
2.8.1 字元
字元和字串是日常開發中經常打交道的資料型別,使用一對單引號('')包含起來的內容就是字元,C語言提供了putchar()和printf()函式輸出字元(英文),應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
輸出字元的兩種方式
putchar()
printf("%c",char);
*/
void char_io() {
putchar('A');
//輸出中文亂碼。
putchar('劉');
printf("%c",'A');
}
void main() {
char_io();
getchar();
}
而字元常量通常為了考慮相容和擴充套件寬字元(即中文),通常會佔據4個位元組,英文佔據一個位元組,中文佔據兩個位元組,應用案例如下所示。
#include <stdio.h>
#include <stdlib.h>
/*
字元的大小
字元常量為了相容擴充套件寬字元,佔據的位元組數量都是4個位元組
而英文字元佔據一個位元組,中文字元(寬字元)佔據兩個位元組
*/
void main() {
char chinese = '劉';
//char 佔據一個位元組,沒辦法儲存中文
printf("chinese =%c ", chinese);
char ch = 'A';
// sizeof()運算子求字元A的大小,這裡為了相容擴充套件寬字元,一般佔據四個位元組
printf(" ch佔據的位元組數量為%d\t 'A'佔據的位元組數量為%d\n",sizeof(ch),sizeof('A'));
//寬字元 佔據兩個位元組,可以儲存中文
wchar_t wch =L'我';
printf("寬字元佔據的位元組數量是%d\n",sizeof(wchar_t));
printf("字元常量我佔據的位元組數量是%d\n",sizeof('我'));
}
如果要想輸出中文字元,可以參考以下方式
//引入本地化的標頭檔案
#include <locale.h>
#include <stdio.h>
#include <stdlib.h>
/*
寬字元用於儲存中文,但是如何輸出中文呢?
參考以下內容
*/
void main() {
//設定本地化
setlocale(LC_ALL, "chs");
//寬字元 佔據兩個位元組,可以儲存中文
wchar_t wch = L'我';
//使用wprintf()函式輸出中文
wprintf(L"%c\n", wch);
getchar();
}
字元在記憶體中是以數字的方式儲存,而ASC||碼錶規定了字元對應的數字編號,當使用printf()函式以數字的輸出方式列印字元時,便輸出了字元對應的ASC||碼錶的數字編號,應用案例如下所示
字元1和整數1的區別:
#include <stdio.h>
#include <stdlib.h>
}
/*
字元型資料儲存
字元在記憶體中是以數字儲存的,ASC||表規定了字元對應的數字編號
*/
void char_asc() {
char ch = '1';
int num = 1;
//字元1和數字1的區別:佔據的位元組數量不一樣
printf("字元1佔據的位元組數量是%d\t數字1佔據的位元組數量是%d\n",sizeof(ch),sizeof(num));
//字元1對應的數字是49,即求ASC碼值
printf("字元1對應的ASC||碼錶的編號是%d\n", ch);
printf("ch=%c\n",ch);
printf("整數1對應的ASC||碼錶的字元是%c",num);
system("pause");
}
字元0,'\0'和整數0的區別
#include <stdio.h>
#include <stdlib.h>
/*
字元0 對應的整數是48
整數0 對應的字元是空字元
\0對應的也是空字元,和整數0的效果一樣
*/
void main() {
char ch_zero = '0';
char ch_num_zero = 0;
int num_zero = 0;
char ch = '\0';
printf("ch_zero佔據的位元組數量是%d\tnum_zero佔據的位元組數量是%d\tch佔據的位元組數量是%d\n",sizeof(ch_zero),sizeof(num_zero),sizeof(ch));
printf("字元0對應的整數編號是%d\n",ch_zero);//48
printf("整數0對應的字元是[%c]\n", num_zero);
printf("\\0對應的整數編號是[%d]\n", ch);//0
printf("\\0的意義是[%c]\n", ch);//空字元
getchar();
}
字元應用:實現大寫轉小寫
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
/*
通過ASC||碼的規律實現大小寫轉換
*/
void main() {
char input='\0';
printf("請輸入一個字母\n");
scanf("%c",&input);
if (input>='A'&& input <='Z') {
printf("你輸入的是大寫字母,轉換為小寫字母的結果是%c\n",(input+32));
}
else if (input>='a'&&input<='z') {
printf("你輸入的是小寫寫字母,轉換為小寫字母的結果是%c\n", (input - 32));
}
system("pause");
}
2.8.2 字串
字串用於表示字元序列,也就是一串使用""包含起來的內容,接下來使用system函式呼叫系統命令理解下什麼是字串,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
字串的應用場景
*/
void main() {
//改變視窗的顏色
system("color 4f");
//改變視窗的標題
system("title power by tony");
getchar();
}
C語言中的字串以/0結尾,這也就是意味著即使雙引號""中什麼都沒有也會佔據一個位元組,而中文字串中的每個字元同樣會佔據兩個位元組,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
字串常量
*/
void main() {
//字串是以/0結尾,這裡字串A佔據2個位元組
printf("字串A佔據的位元組數量是%d\n",sizeof("A"));
printf("\"\"佔據的位元組數量為%d\n",sizeof("")); //以\0結尾
//字串單箇中文佔據兩個位元組
printf("字串劉光磊佔據的位元組數量是%d",sizeof("劉光磊")); //每個中文佔據兩個位元組,然後以\0結尾 因此是7個
system("pause");
}
字串加密解密的實現
#include <stdio.h>
#include <stdlib.h>
/*
字串簡單的加密
*/
void main() {
char str[5] = {'c','a','l','c','\0'};
system(str);
printf("加密之前str = %s\n",str);
for (int i = 0; i < 4;i++) {
str[i] += 1;
}
printf("加密之後str = %s\n", str);
for (int i = 0; i < 4;i++) {
str[i] -= 1;
}
printf("解密之後str = %s\n", str);
system("pause");
}
使用sprintf函式實現整合字串
#include <stdio.h>
#include <stdlib.h>
/*
通過sprintf函式列印到字串,然後藉助color命令實現視窗變色
*/
void main() {
char str[20] = {0};
while (1) {
for (char ch = '0'; ch <= '9'; ch++) {
sprintf(str, "color %c%c", ch, 'e');
system(str);
}
}
}
通過sprintf函式實現整合字串
#include <stdio.h>
#include <stdlib.h>
/*
通過sprintf函式實現整合字串
*/
void main() {
char str[100] = {0};
sprintf(str,"title power by %s","tony");
system(str);
}
2.9 布林型別
bool型別只有兩個值,即true和fasle,它們在記憶體中分別使用1和0表示,這樣一個位元組便可以儲存bool型別的變數,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
/*
bool的使用
*/
void main() {
bool flag = true;
//佔據的位元組數量為1
printf("bool佔據的位元組數量是%d\n", sizeof(flag));
//成立的結果為1
printf("bool = %d\n", flag);
flag = false;
//不成立的結果為0
printf("bool = %d\n", flag);
system("pause");
}
bool的應用場景就是用來判斷條件表示式是否成立,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
/*
bool的應用場景就是用來判斷表示式是否成立
*/
void main() {
bool flag = 5 > 30;
if (flag==true) {
printf("條件成立\n");
}
else {
printf("不成立\n");
}
getchar();
}
2.10 型別轉換及其記憶體原理
2.10.1 printf與強制型別轉換
printf()函式在輸出資料時,不會進行資料型別轉換,如果想要獲取預期的結果,就需要進行強轉實現,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
printf()函式與強制型別轉換
*/
void main() {
//因為printf函式不會進行型別轉換,所以這裡得到一個錯誤的結果858993459
printf("%d\n",12.1);
//12.1為浮點型別,這裡使用強制型別轉換實現轉換為整數
printf("%d\n",(int)12.1);
printf("%f\n",10); //整數按照浮點數解析,得到的結果就是0.000000
printf("%f\n",(float)10); //強制型別轉換
getchar();
}
2.10.2 自動型別轉換
表示範圍小的資料和表示範圍大的資料在參與運算時,運算結果的型別會自動轉換為表示範圍大的型別,應用案例如下所示。
#include "common.h"
/*
自動型別轉換
在進行算術運算時,會發生自動型別轉換 表示範圍小的值自動轉換為表示範圍大的變數,儲存精度
char->short>int->long->float->double->long double
*/
void main() {
char ch = 'A';
printf("1.0佔據的位元組數量是%d\n",sizeof(1.0));
printf("字元變數ch+1的位元組數量是%d\n",sizeof(ch+1));
printf("字元變數ch+1.0的位元組數量是%d\n",sizeof(ch+1.0));
getchar();
}
2.10.3 強制型別轉換
在某些應用場景下需要使用到強制型別轉換,例如銀行賬戶的取整等等,強制型別轉換的應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
強制型別轉換
*/
void main() {
float fl = 10.8;
float flt = 10.3;
int num = (int)fl + flt; //20.3 先把fl強制轉換為int型別,然後再和flt相加
printf("num =%d\n",num);
num = (int)(fl + flt);//21 先把fl和flt相加後,強制轉換為int
printf("num =%d\n", num);
getchar();
}
而需要注意的是強制型別轉換則會損失原有資料的精度,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
強制型別轉換的案例
*/
void main() {
//這裡發生了自動型別轉換
double dbl = 3;
printf("dbl = %f\n",dbl);
//7.8預設是double型別,這裡轉換為int會損失精度
int num = 7.8;
//printf()函式沒有進行資料型別轉換
printf("num =%d\n",num);
getchar();
}
但是由於強制型別轉換是由CPU的暫存器完成的,強制轉換後不會影響原來的變數值,應用案例如下所示
#include <stdio.h>
#include <stdlib.h>
/*
強制型別轉換不會改變原有的值
*/
void main() {
double dbl = 4.5;
//賦值運算會執行型別轉換,但是為了考慮到軟體工程的規範,這裡還是加上強制型別轉換,增加程式碼的閱讀性
int num = (int)dbl; //強制型別轉換是在CPU內部的暫存器完成的
printf("dbl = %f\nnum =%d",dbl,num);
getchar();
}
在進行強制型別轉換時要考慮資料的極限問題,不然會引發資料溢位,應用案例如下所示。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
/*
強制型別轉換的溢位問題
*/
void main() {
int num = 256;
//無符號的char能儲存的最大值為255,這裡的256超過它的最大表示範圍,因此發生資料溢位
unsigned char ch = num;
printf("num =%d \t ch = %u",num,ch);
getchar();
}
2.10.4 資料型別轉換的記憶體原理
當在進行資料型別轉換時,如果該資料是有符號的,在進行資料型別轉換時按照符號位數來填充,如果是無符號則按照0來填充,應用案例如下所示
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
/*
資料型別轉換的記憶體原理
有符號 低位元組轉高位元組按照符號位數填充
無符號 低位元組轉高位元組按照0填充
*/
void main() {
//正數按照0填充
char ch = 1; // 二進位制表示 0000 0001
int num = 1; // 二進位制表示 0000 0000 0000 0000 0000 0000 0000 0001
//負數按照1填充
// 二進位制表示 原碼 1000 0001 反碼 1111 1110 補碼 1111 1111 ->ff
ch = -1;
// 二進位制表示 原碼 1000 0000 0000 0000 0000 0000 0000 00001
// 反碼 1111 1111 1111 1111 1111 1111 1111 1110
// 補碼 1111 1111 1111 1111 1111 1111 1111 1111 -> ffffffff
num = ch;
unsigned char data = 255+1; // 二進位制補碼 1 0000 0000 但是char只能佔據8位,因此這裡會擷取8位即0000 0000,結果位0
printf("unsigned char data的地址是%p",&data);
printf("data = %d",data);
unsigned int u_num = -1; //賦值錯誤,能編譯不意味著結果正確
// 1000 0000 0000 0000 0000 0000 0000 0000 0001
// 1111 1111 1111 1111 1111 1111 1111 1111 1110
// 1111 1111 1111 1111 1111 1111 1111 1111 1111 無符號解析結果為2的32次方即4294967295
for (int i = 0; i < u_num;i++) {
system("mspaint");
}
getchar();
}
2.11 應用案例
- 使用強制資料型別轉換實現偷錢程式
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
/*
實現偷錢程式
如果賬戶餘額的分大於等於4分就不偷錢,小於等於3分就偷走
*/
void main() {
printf("請輸入你的賬戶餘額\n");
double balance =0.0;
scanf("%lf",&balance);
// 12.34*10=123.4 123.4+0.6=124 124/10.0=12.4 12.4>12.34
double rest = (int)((balance * 10) + 0.6) / 10.0;
printf("rest = %f",rest);
if (rest<balance) {
//
printf("可以偷錢%.2f元",balance-rest);
}
getchar();
}
- 小數點後三位實現四捨五入
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
/*
實現對小數點後三位實現四捨五入
*/
void main() {
printf("請輸入四捨五入的三位小數\n");
double input = 0.0;
scanf("%lf",&input);
double val = 1.235;
//1.234*100=123.4 123.4+0.5=123 123/100.0=1.23
// 1.235*100=123.5 123.5+0.5=124 124/100=1.24
// 1.24>1.235
// 1.24-1.235=0.05
//1.235+0.05=1.24
double result =(int)(input * 100 + 0.5) / 100.0;
printf("result =%.2f",result);
getchar();
}