
scrapy框架的底層原理和如何提高爬取效率
Scrapy的最新架構圖: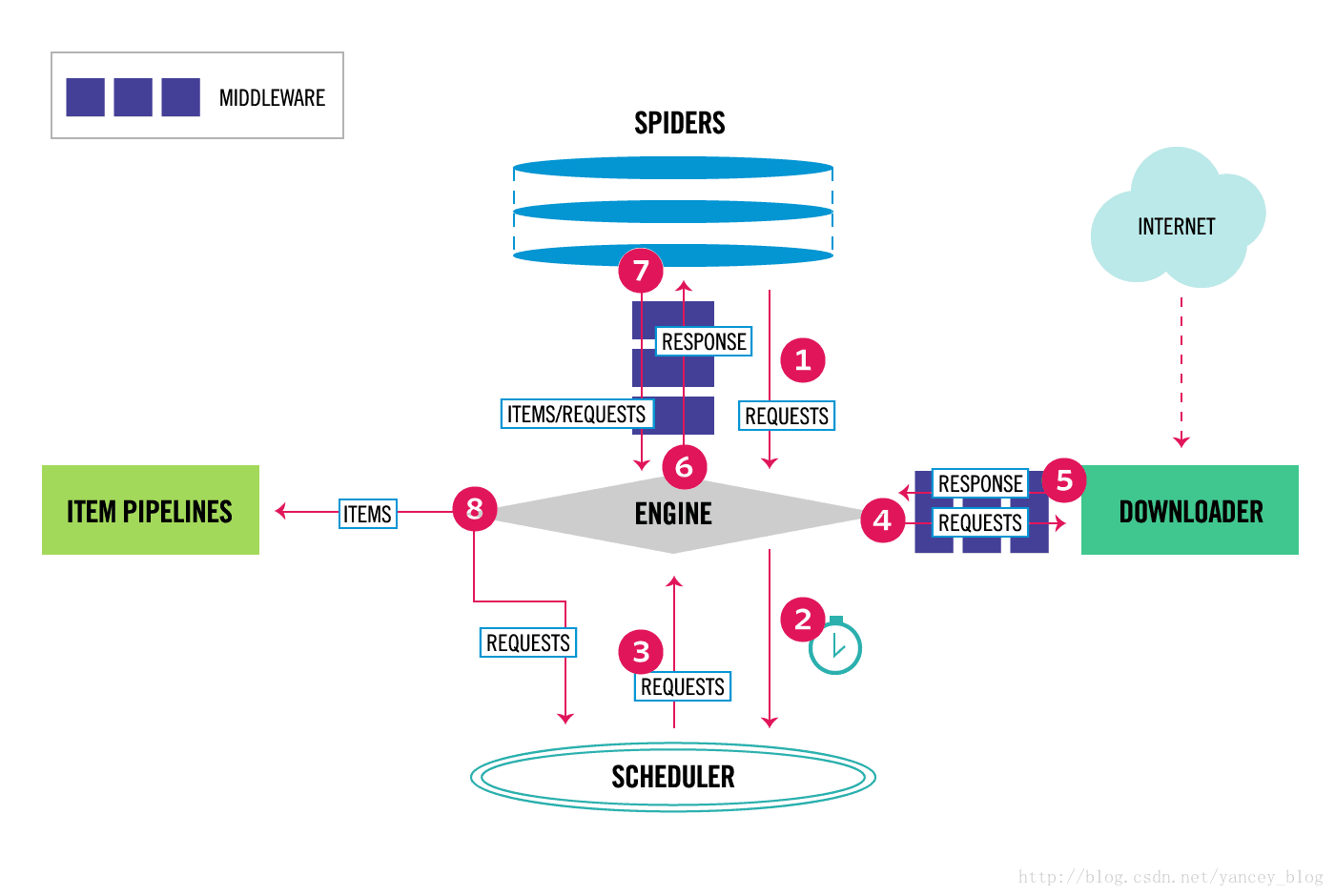
Scrapy引擎是用來控制整個系統的資料處理流程,並進行事務處理的觸發。更多的詳細內容可以看下面的資料處理流程。
2、Scheduler(排程)
排程程式從Scrapy引擎接受請求並排序列入佇列,並在Scrapy引擎發出請求後返還給他們。
3、Downloader(下載器)
下載器的主要職責是抓取網頁並將網頁內容返還給蜘蛛( Spiders)。
4、Spiders(蜘蛛)
蜘蛛是有Scrapy使用者自己定義用來解析網頁並抓取制定URL返回的內容的類,每個蜘蛛都能處理一個域名或一組域名。換句話說就是用來定義特定網站的抓取和解析規則。
蜘蛛的整個抓取流程(週期)是這樣的:
首先獲取第一個URL的初始請求,當請求返回後調取一個回撥函式。第一個請求是通過呼叫start_requests()方法。該方法預設從start_urls中的Url中生成請求,並執行解析來呼叫回撥函式。
在回撥函式中,你可以解析網頁響應並返回專案物件和請求物件或兩者的迭代。這些請求也將包含一個回撥,然後被Scrapy下載,然後有指定的回撥處理。
在回撥函式中,你解析網站的內容,同程使用的是Xpath選擇器(但是你也可以使用BeautifuSoup, lxml或其他任何你喜歡的程式),並生成解析的資料項。
最後,從蜘蛛返回的專案通常會進駐到專案管道。
5、Item Pipeline(專案管道)
專案管道的主要責任是負責處理有蜘蛛從網頁中抽取的專案,他的主要任務是清晰、驗證和儲存資料。當頁面被蜘蛛解析後,將被髮送到專案管道,並經過幾 個特定的次序處理資料。每個專案管道的元件都是有一個簡單的方法組成的Python類。他們獲取了專案並執行他們的方法,同時他們還需要確定的是是否需要 在專案管道中繼續執行下一步或是直接丟棄掉不處理。
專案管道通常執行的過程有:
清洗HTML資料
驗證解析到的資料(檢查專案是否包含必要的欄位)
檢查是否是重複資料(如果重複就刪除)
將解析到的資料儲存到資料庫中
6、Downloader middlewares(下載器中介軟體)
下載中介軟體是位於Scrapy引擎和下載器之間的鉤子框架,主要是處理Scrapy引擎與下載器之間的請求及響應。它提供了一個自定義的程式碼的方式 來拓展Scrapy的功能。下載中間器是一個處理請求和響應的鉤子框架。他是輕量級的,對Scrapy盡享全域性控制的底層的系統。
7、Spider middlewares(蜘蛛中介軟體)
蜘蛛中介軟體是介於Scrapy引擎和蜘蛛之間的鉤子框架,主要工作是處理蜘蛛的響應輸入和請求輸出。它提供一個自定義程式碼的方式來拓展Scrapy 的功能。蛛中介軟體是一個掛接到Scrapy的蜘蛛處理機制的框架,你可以插入自定義的程式碼來處理髮送給蜘蛛的請求和返回蜘蛛獲取的響應內容和專案。
8、Scheduler middlewares(排程中介軟體)
排程中介軟體是介於Scrapy引擎和排程之間的中介軟體,主要工作是處從Scrapy引擎傳送到排程的請求和響應。他提供了一個自定義的程式碼來拓展Scrapy的功能。
三、資料處理流程
Scrapy的整個資料處理流程有Scrapy引擎進行控制,其主要的執行方式為:
引擎開啟一個域名,時蜘蛛處理這個域名,並讓蜘蛛獲取第一個爬取的URL。
引擎從蜘蛛那獲取第一個需要爬取的URL,然後作為請求在排程中進行排程。
引擎從排程那獲取接下來進行爬取的頁面。
排程將下一個爬取的URL返回給引擎,引擎將他們通過下載中介軟體傳送到下載器。
當網頁被下載器下載完成以後,響應內容通過下載中介軟體被髮送到引擎。
引擎收到下載器的響應並將它通過蜘蛛中介軟體傳送到蜘蛛進行處理。
蜘蛛處理響應並返回爬取到的專案,然後給引擎傳送新的請求。
引擎將抓取到的專案專案管道,並向排程傳送請求。
系統重複第二部後面的操作,直到排程中沒有請求,然後斷開引擎與域之間的聯絡。
四、驅動器
Scrapy是由Twisted寫的一個受歡迎的Python事件驅動網路框架,它使用的是非堵塞的非同步處理。