
[Python爬蟲]Scrapy配合Selenium和PhantomJS爬取動態網頁
Python世界中Scrapy一直是爬蟲的一個較為成熟的解決方案,目前javascript在網頁中應用越來越廣泛,越來越多的網站選擇使用javascript動態的生成網頁的內容,使得很多純html的爬蟲解決方案失效。針對這種動態網站的爬取,目前也有很多解決方案。其中Selenium+PhantomJS是較為簡單和穩定的一種。
Selenium是一個網頁的自動化測試工具,其本身是用python編寫的。PhantomJS可以認為是一個基於WebKit核心的Headless瀏覽器。我們通過Selenium的Webdriver引入PhantomJS支援,使用PhantomJS來解析動態的網頁。
本文以爬取建行理財資料為例:
以下是建行理財頁面的截圖,其中紅色框標出的理財資料是後續使用js動態載入的,並不是一開始就寫死在html上的。
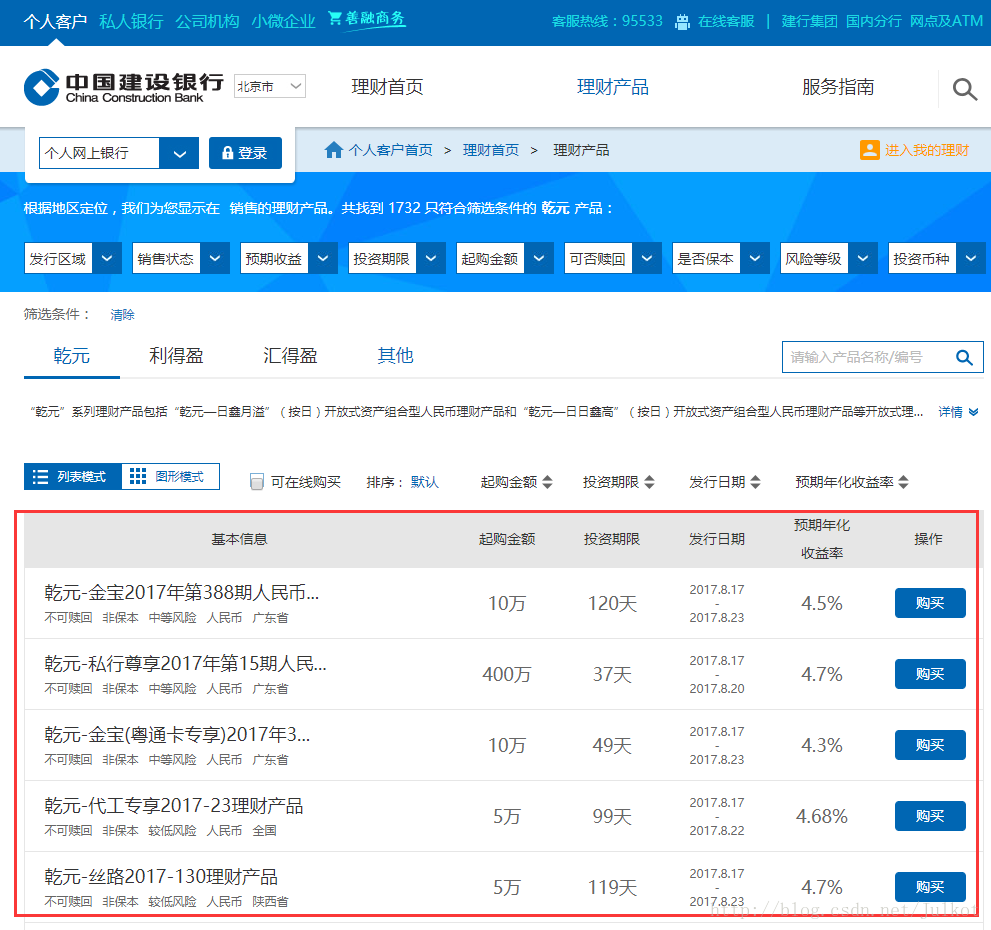
另外我還發現,如果僅僅使用phantomjs載入該網頁,沒辦法自動執行js指令碼,獲取理財列表。通過分析該網頁,我發現只要先選擇區域資訊,然後再載入一次頁面,即可下載對應的理財列表。
廢話不多說,先上完整程式碼:
爬蟲的程式碼檔案
# -*- coding: utf-8 -*-
import scrapy, urlparse, re
from selenium import webdriver
from scrapy.http import scrapy的配置檔案
# -*- coding: utf-8 -*-
BOT_NAME = 'robot'
SPIDER_MODULES = ['robot.spiders']
NEWSPIDER_MODULE = 'robot.spiders'
# Logging Setting
# LOG_FILE = os.path.normpath(os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), "log/spider.log"))
LOG_LEVEL = "INFO"
LOG_STDOUT = False
LOG_FORMAT = '%(asctime)s %(filename)s[line:%(lineno)d] [%(name)s] %(levelname)s: %(message)s'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY=1
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN=16
#CONCURRENT_REQUESTS_PER_IP=16
# Disable cookies (enabled by default)
COOKIES_ENABLED=True
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'robot.middlewares.PhantomJSMiddleware': 1000,
}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'robot.pipelines.DBPipeline': 1000,
}
PHANTOMJS_PATH = r'/root/phantomjs/bin/phantomjs'
DB_PATH = r'mysql+pymysql://robot:[email protected]:3306/robot'程式碼解析
首先,在scrapy的setting.py中,加入PhantomJS的安裝路徑,即上述程式碼中的PHANTOMJS_PATH = r'/root/phantomjs/bin/phantomjs'
接下來,我們來分析爬蟲的程式碼檔案,在爬蟲類_init_過程中,我們需要啟動selenium的Webdriver,並將其使用的瀏覽器設定為PhantomJS,self.driver = webdriver.PhantomJS(executable_path=PHANTOMJS_PATH, service_args=["--ssl-protocol=any", "--ignore-ssl-errors=true", "--load-images=false", "--disk-cache=true"])。 其中
--ssl-protocol=any, --ignore-ssl-errors=true用來設定ssl的--load-images=false設定了讓PhantomJS不載入圖片,有利於提高PhantomJS的速度--disk-cache=true啟用本地磁碟快取,同樣有利於提高提高PhantomJS的速度
然後在start_request中
- 先模擬點選id為txt元素,
self.driver.find_element_by_id("txt").click()如圖所示: - 呼叫Webdriver的等待函式,等待彈框顯示
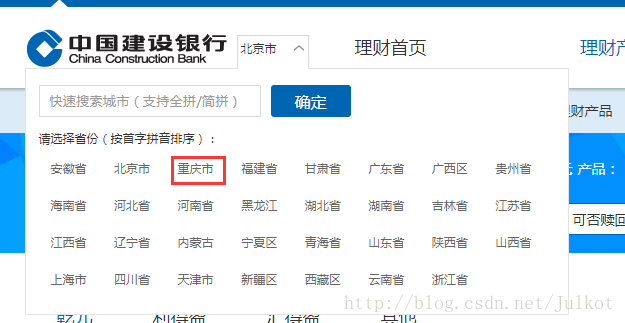
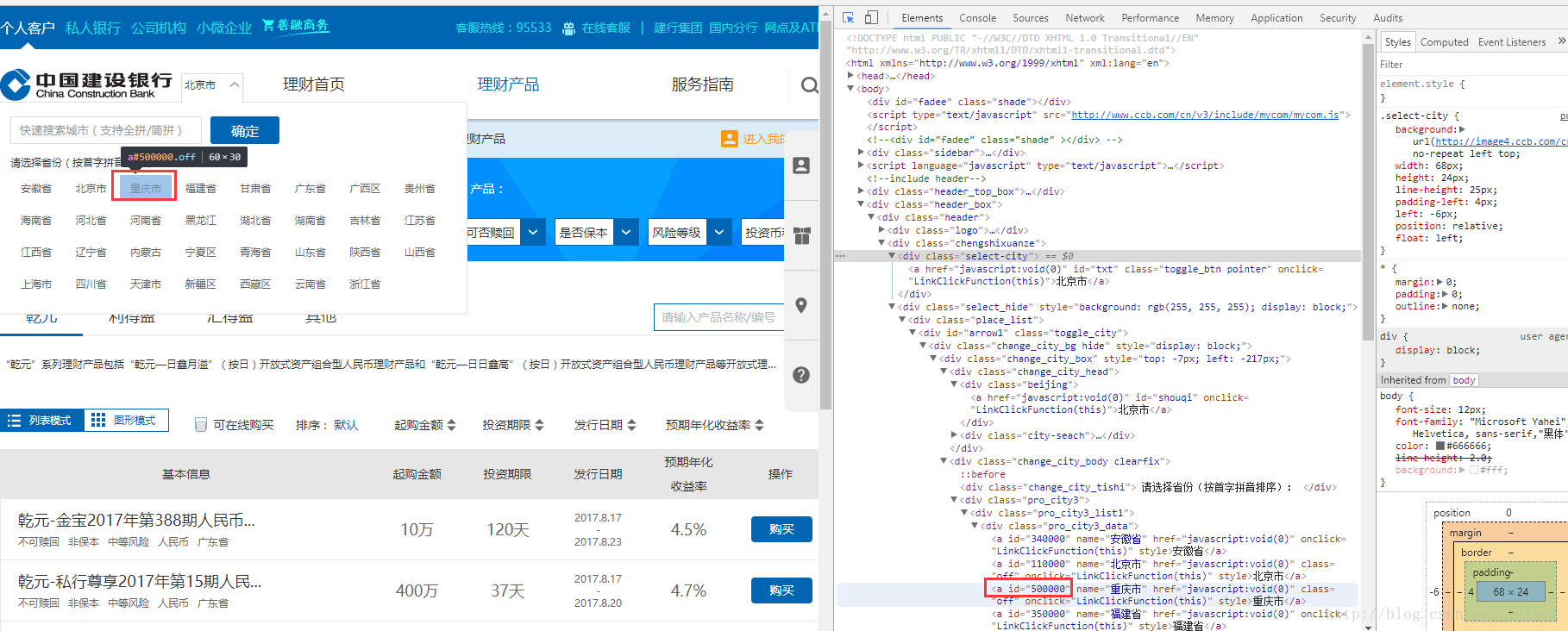
wait.until(EC.visibility_of_element_located((By.CLASS_NAME, 'select_hide'))) - 在彈框中,模擬點選重慶市(id為500000),
self.driver.find_element_by_id("500000").click()如圖所示 再重新獲取一次頁面,
self.driver.get(url)。PS: 我猜測,上面的點選會把地理位置資訊儲存在PhantomJS的網頁快取中,再一次獲取頁面就不用再去設定地理位置資訊,而通過這個資訊,即可馬上獲取對應的理財列表了。
遍歷理財種類的tab頁
for element in self.driver.find_elements_by_css_selector(".life_tab>a"): element.click()
- 遍歷當前頁面上理財列表,並且判斷是否還有下一頁,如果還有下一頁,模擬點選下一頁按鈕


if self.driver.find_element_by_id("pageDiv").is_displayed():
current, total = resp.css("#pageNum").xpath("./text()").extract()[0].split("/", 1)
if int(current) == int(total):
break
else:
self.driver.find_element_by_id("next").click()
else:
break以上就是selenium和PhantomJS配合使用的簡單解釋。
PS: 注意,在爬蟲類中一定要加上
def closed(self, reason):這個函式,並且在函式中顯式退出PhantomJS,否則PhantomJS的程序會一直保留。當你使用scrapyd進行部署執行的時候,這個問題會導致只能執行幾個爬蟲,之後程式就卡住了。