
Spark:Task原理分析
在Spark中,一個應用程式要想被執行,肯定要經過以下的步驟:
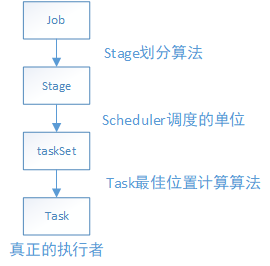
從這個路線得知,最終一個job是依賴於分佈在叢集不同節點中的task,通過並行或者併發的執行來完成真正的工作。由此可見,一個個的分散式的task才是Spark的真正執行者。下面先來張task執行框架整體的對Spark的task執行有個大概的瞭解。
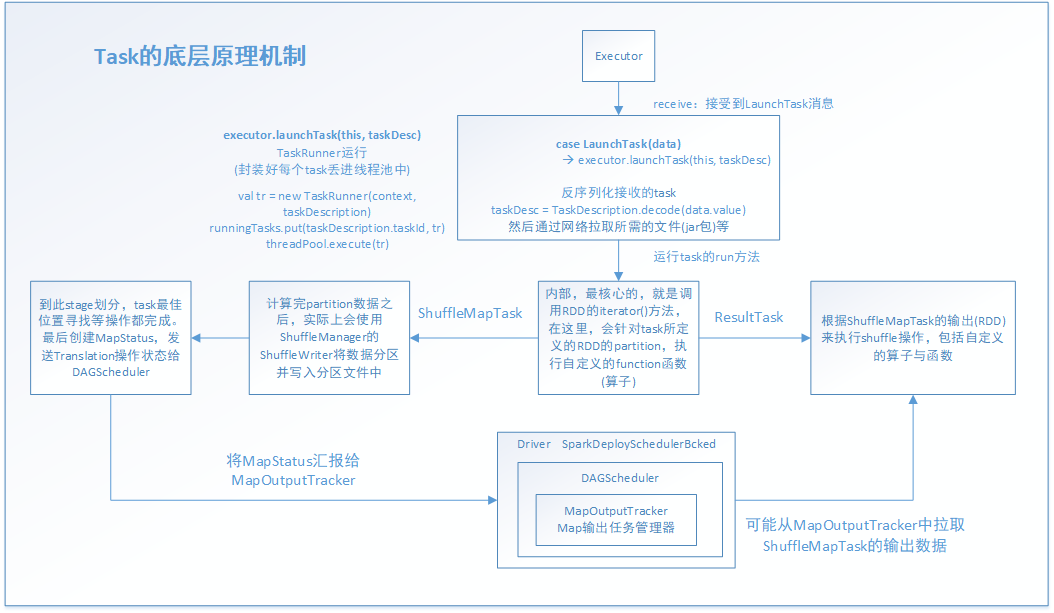
task執行之前的工作是Driver啟動Executor,接著Executor準備好一切執行環境,並向Driver反向註冊,最終Driver向Executor傳送LunchTask事件訊息,從Executor接受到LanchTask那一刻起,task就一發不可收拾了,開始通過java執行緒來進行以後的工作。當然了,在task正式工作之前,還有一些工作,比如根據stage演算法劃分好stage,根據task最佳位置計算演算法尋找到task的最佳位置(第一期盼都是希望能夠在同一個節點的同一個程序中有task所需要的需要,第二才是同一節點的不同程序,第三才是同一機架的不同節點,第四才是不同機架)。這樣做的目的是減少網路通訊的開銷,節省CPU資源,提高系統性能。
其實雖然圖片看起來複雜,其實task所做的事情無非以下幾點:
1.通過網路拉取執行所需的資源,並反序列化(由於多個task執行在多個Executor中,都是並行執行的,或者併發執行的,一個stage的task,處理的RDD是一樣的,這是通過廣播變數來完成的)
2.獲取shuffleManager,從shuffleManager中獲取shuffleWriter(shuffleWriter用於後面的資料處理並把返回的資料結果寫入磁碟)
3.呼叫rdd.iterator(),並傳入當前task要處理的partition(針對RDD的某個partition執行自定義的運算元或邏輯函式,返回的資料都是通過上面生成的ShuffleWriter,經過HashPartitioner[預設是這個]分割槽之後寫入對應的分割槽backet,其實就是寫入磁碟檔案中)
4.封裝資料結果為MapStatus ,傳送給MapOutputTracker,供ResultTask拉取。(MapStatus裡面封裝了ShuffleMaptask計算後的資料和儲存位置地址等資料資訊。其實也就是BlockManager相關資訊,BlockManager 是Spark底層的記憶體,資料,磁碟資料管理的元件)
5.ResultTask拉取ShuffleMapTask的結果資料(經過2/3/4步驟之後的結果)
實現這個過程,task有ShuffleMapTask和ResultTask兩個子類task來支撐,前者是用於通過各種map運算元和自定義函式轉換RDD。後者主要是觸發了action操作,把map階段後的新的RDD拉取過去,再執行我們自定義的函式體,實現各種業務功能。
下面通過原始碼來分析整個流程:
CoarseGrainedExecutorBackend是executor粗粒度真正的後臺處理程序。其中比較重要的是以下函式,主要是用於接受其他工作程序所傳送的事件訊息,並做對應的響應。
override def receive: PartialFunction[Any, Unit]
executor接受到這個事件訊息後,task才真正開始工作。其中的executor.launchTask(this, taskDesc)就是主要的實現函式體
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskDesc)
}
launchTask方法,主要是new出一個TaskRunner執行緒,並把它放進java的執行緒池中執行。通過這裡也知道其實Spark的底層是依賴Java和Scala共同實現的。
def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = {
val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
threadPool.execute(tr)
}通過看TaskRunner的實現,知道它是繼承Runnable的,因此,就知道執行緒真正的執行體是run()方法。
class TaskRunner(
execBackend: ExecutorBackend,
private val taskDescription: TaskDescription)
extends Runnable
下面是run( )方法的主要部分原始碼。
override def run(): Unit = {
threadId = Thread.currentThread.getId
Thread.currentThread.setName(threadName)
val threadMXBean = ManagementFactory.getThreadMXBean
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser = env.closureSerializer.newInstance()
logInfo(s"Running $taskName (TID $taskId)")
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var taskStart: Long = 0
var taskStartCpu: Long = 0
startGCTime = computeTotalGcTime()
try {
// Must be set before updateDependencies() is called, in case fetching dependencies
// requires access to properties contained within (e.g. for access control).
//對序列化的資料,進行反序列化
Executor.taskDeserializationProps.set(taskDescription.properties)
//通過網路通訊的方法,把task執行所需要的檔案、資源、jar等拉取過來
updateDependencies(taskDescription.addedFiles, taskDescription.addedJars)
//最後,通過正式的反序列化操作,將整個task的資料集拉取過來
//這裡用ClassLoader的原因是通過指定的上下文資源,進行載入和讀取。(當然,反射還有另外的功能:通過反射放射動態載入一個類,建立類的物件)
task = ser.deserialize[Task[Any]](
taskDescription.serializedTask, Thread.currentThread.getContextClassLoader)
task.localProperties = taskDescription.properties
task.setTaskMemoryManager(taskMemoryManager)
// If this task has been killed before we deserialized it, let's quit now. Otherwise,
// continue executing the task.
val killReason = reasonIfKilled
if (killReason.isDefined) {
// Throw an exception rather than returning, because returning within a try{} block
// causes a NonLocalReturnControl exception to be thrown. The NonLocalReturnControl
// exception will be caught by the catch block, leading to an incorrect ExceptionFailure
// for the task.
throw new TaskKilledException(killReason.get)
}
logDebug("Task " + taskId + "'s epoch is " + task.epoch)
env.mapOutputTracker.updateEpoch(task.epoch)
// Run the actual task and measure its runtime.
//計算task開始的時間
taskStart = System.currentTimeMillis()
taskStartCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
var threwException = true
/**
* value 對於ShuffleMapTask來說,就是MapStatus
* 封裝了ShuffleMapTask計算的資料,輸出的位置
* 後面的ShuffleMapTask會去聯絡MapOutputTracker來獲取一個ShuffleMapTask的輸出位置,通過網路網路拉取資料
* ResultTask也是這樣的,只不過是查詢ShuffleMapTask的結果MapStatus的位置
* 總的來說 MapOutputTracker(Map輸出工作管理員),把map和action聯絡起來了。
*/
val value = try {
//真正的task的執行緒執行方法,下面會詳細分析
val res = task.run(
taskAttemptId = taskId,
attemptNumber = taskDescription.attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {
val releasedLocks = env.blockManager.releaseAllLocksForTask(taskId)
val freedMemory = taskMemoryManager.cleanUpAllAllocatedMemory()
if (freedMemory > 0 && !threwException) {
val errMsg = s"Managed memory leak detected; size = $freedMemory bytes, TID = $taskId"
if (conf.getBoolean("spark.unsafe.exceptionOnMemoryLeak", false)) {
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
if (releasedLocks.nonEmpty && !threwException) {
val errMsg =
s"${releasedLocks.size} block locks were not released by TID = $taskId:\n" +
releasedLocks.mkString("[", ", ", "]")
if (conf.getBoolean("spark.storage.exceptionOnPinLeak", false)) {
throw new SparkException(errMsg)
} else {
logInfo(errMsg)
}
}
}
task.context.fetchFailed.foreach { fetchFailure =>
// uh-oh. it appears the user code has caught the fetch-failure without throwing any
// other exceptions. Its *possible* this is what the user meant to do (though highly
// unlikely). So we will log an error and keep going.
logError(s"TID ${taskId} completed successfully though internally it encountered " +
s"unrecoverable fetch failures! Most likely this means user code is incorrectly " +
s"swallowing Spark's internal ${classOf[FetchFailedException]}", fetchFailure)
}
//task結束的時間
val taskFinish = System.currentTimeMillis()
val taskFinishCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
// If the task has been killed, let's fail it.
task.context.killTaskIfInterrupted()
//對MapStatus進行各種序列化和封裝,後面要傳送給MapOutputTracker
val resultSer = env.serializer.newInstance()
val beforeSerialization = System.currentTimeMillis()
val valueBytes = resultSer.serialize(value)
val afterSerialization = System.currentTimeMillis()
// Deserialization happens in two parts: first, we deserialize a Task object, which
// includes the Partition. Second, Task.run() deserializes the RDD and function to be run.
/**
* 計算出task的一些統計資訊,執行時間/反序列化消耗的時間/JAva虛擬機器 GC消耗的時間/反序列化消耗的時間
*/
task.metrics.setExecutorDeserializeTime(
(taskStart - deserializeStartTime) + task.executorDeserializeTime)
task.metrics.setExecutorDeserializeCpuTime(
(taskStartCpu - deserializeStartCpuTime) + task.executorDeserializeCpuTime)
// We need to subtract Task.run()'s deserialization time to avoid double-counting
task.metrics.setExecutorRunTime((taskFinish - taskStart) - task.executorDeserializeTime)
task.metrics.setExecutorCpuTime(
(taskFinishCpu - taskStartCpu) - task.executorDeserializeCpuTime)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.metrics.setResultSerializationTime(afterSerialization - beforeSerialization)
// Note: accumulator updates must be collected after TaskMetrics is updated
val accumUpdates = task.collectAccumulatorUpdates()
// TODO: do not serialize value twice
val directResult = new DirectTaskResult(valueBytes, accumUpdates)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit
// directSend = sending directly back to the driver
//下面是對map結果做序列化和對其做位置等資訊的封裝,方便網路傳輸和位置查詢。注意,BlockManager 是Spark底層的記憶體,資料,磁碟資料管理的元件
val serializedResult: ByteBuffer = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
//呼叫executor所在的ScoresGrainedExecutorBackend的statusUpdate,更新狀態資訊
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
case t: Throwable if hasFetchFailure && !Utils.isFatalError(t) =>
val reason = task.context.fetchFailed.get.toTaskFailedReason
if (!t.isInstanceOf[FetchFailedException]) {
// there was a fetch failure in the task, but some user code wrapped that exception
// and threw something else. Regardless, we treat it as a fetch failure.
val fetchFailedCls = classOf[FetchFailedException].getName
logWarning(s"TID ${taskId} encountered a ${fetchFailedCls} and " +
s"failed, but the ${fetchFailedCls} was hidden by another " +
s"exception. Spark is handling this like a fetch failure and ignoring the " +
s"other exception: $t")
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
executor的task.run,底層主要是task的run方法,很明顯看出來,主要工作是建立一個context,把task執行過程中的上下文記錄下來。其中關鍵的是呼叫抽象方法,runTask。
final def run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem): T = {
SparkEnv.get.blockManager.registerTask(taskAttemptId)
//建立 context ,task的執行上下文,裡面記錄task執行的全域性性的資料
//重試次數,task屬於哪個stage,task要處理的是哪個rdd,哪個partition等
context = new TaskContextImpl(
stageId,
partitionId,
taskAttemptId,
attemptNumber,
taskMemoryManager,
localProperties,
metricsSystem,
metrics)
TaskContext.setTaskContext(context)
taskThread = Thread.currentThread()
if (_reasonIfKilled != null) {
kill(interruptThread = false, _reasonIfKilled)
}
new CallerContext(
"TASK",
SparkEnv.get.conf.get(APP_CALLER_CONTEXT),
appId,
appAttemptId,
jobId,
Option(stageId),
Option(stageAttemptId),
Option(taskAttemptId),
Option(attemptNumber)).setCurrentContext()
try {
//呼叫抽象方法,runTask
runTask(context)
} catch {
case e: Throwable =>
// Catch all errors; run task failure callbacks, and rethrow the exception.
try {
context.markTaskFailed(e)
} catch {
case t: Throwable =>
e.addSuppressed(t)
}
context.markTaskCompleted(Some(e))
throw e
} finally {
try {
// Call the task completion callbacks. If "markTaskCompleted" is called twice, the second
// one is no-op.
context.markTaskCompleted(None)
} finally {
try {
Utils.tryLogNonFatalError {
// Release memory used by this thread for unrolling blocks
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP)
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(
MemoryMode.OFF_HEAP)
// Notify any tasks waiting for execution memory to be freed to wake up and try to
// acquire memory again. This makes impossible the scenario where a task sleeps forever
// because there are no other tasks left to notify it. Since this is safe to do but may
// not be strictly necessary, we should revisit whether we can remove this in the
// future.
val memoryManager = SparkEnv.get.memoryManager
memoryManager.synchronized { memoryManager.notifyAll() }
}
} finally {
// Though we unset the ThreadLocal here, the context member variable itself is still
// queried directly in the TaskRunner to check for FetchFailedExceptions.
TaskContext.unset()
}
}
}
}task是抽象方法,意味著這個類只是模板類,僅僅封裝了一些子類通用的屬性和方法,依賴於子類實現它們,來確定具體的功能。 前面說過task的有兩個子類ShuffleMapTask和ResultTask。有了它們,才能執行定義的運算元和邏輯
def runTask(context: TaskContext): T
def preferredLocations: Seq[TaskLocation] = Nil
// Map output tracker epoch. Will be set by TaskSetManager.
var epoch: Long = -1
// Task context, to be initialized in run().
@transient var context: TaskContextImpl = _
// The actual Thread on which the task is running, if any. Initialized in run().
@volatile @transient private var taskThread: Thread = _
// If non-null, this task has been killed and the reason is as specified. This is used in case
// context is not yet initialized when kill() is invoked.
@volatile @transient private var _reasonIfKilled: String = null
protected var _executorDeserializeTime: Long = 0
protected var _executorDeserializeCpuTime: Long = 0
/**
* If defined, this task has been killed and this option contains the reason.
*/
def reasonIfKilled: Option[String] = Option(_reasonIfKilled)
/**
* Returns the amount of time spent deserializing the RDD and function to be run.
*/
def executorDeserializeTime: Long = _executorDeserializeTime
def executorDeserializeCpuTime: Long = _executorDeserializeCpuTime
/**
* Collect the latest values of accumulators used in this task. If the task failed,
* filter out the accumulators whose values should not be included on failures.
*/
def collectAccumulatorUpdates(taskFailed: Boolean = false): Seq[AccumulatorV2[_, _]] = {
if (context != null) {
// Note: internal accumulators representing task metrics always count failed values
context.taskMetrics.nonZeroInternalAccums() ++
// zero value external accumulators may still be useful, e.g. SQLMetrics, we should not
// filter them out.
context.taskMetrics.externalAccums.filter(a => !taskFailed || a.countFailedValues)
} else {
Seq.empty
}
}到此,task整個執行流程已分析一遍,最後,呼叫下面的函式來更新狀態資訊
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)最後來總結一下,task的執行一開始不是直接呼叫底層的task的run方法直接處理job-->stage-->taskSet-->task這條路線的task任務的,它是通過分層和分工的思想來完成。task會派生出兩個子類ShuffleMapTask和ResultTask分別完成對應的工作,ShuffleMapTask主要是對task所擁有的的RDD的partition做對應的RDD轉換工作,ResultTask主要是根據action動作觸發,並拉取ShuffleMapTask階段的結果做進一步的運算元和邏輯函式對資料對真正進一步的處理。這兩個階段是通過MapOutputTracker來連線起來的。