目標檢測+影象分割專案
【深度學習:目標檢測】RCNN學習筆記(10):SSD:Single Shot MultiBox Detector
2016年10月06日 19:00:10 蓀蓀 閱讀數:40730更多
之前一直想總結下SSD,奈何時間緣故一直沒有整理,在我的認知當中,SSD是對Faster RCNN RPN這一獨特步驟的延伸與整合。總而言之,在思考於RPN進行2-class分類的時候,能否借鑑YOLO並簡化faster rcnn在21分類同時整合faster rcnn中anchor boxes實現multi-scale的思想而設計出了SSD,這篇blog關於SSD的細節方面整理的很好,以供參考。
轉自:http://blog.csdn.net/u010167269/article/details/52563573 Preface
Abstract
這篇文章在既保證速度,又要保證精度的情況下,提出了 SSD 物體檢測模型,與現在流行的檢測模型一樣,將檢測過程整個成一個 single deep neural network。便於訓練與優化,同時提高檢測速度。SSD 將輸出一系列 離散化(discretization) 的 bounding boxes,這些 bounding boxes 是在 不同層次(layers) 上的 feature maps 上生成的,並且有著不同的 aspect ratio。
在 prediction 階段:
-
要計算出每一個 default box 中的物體,其屬於每個類別的可能性,即 score,得分。如對於
PASCAL VOC 資料集,總共有 20 類,那麼得出每一個 bounding box 中物體屬於這 20 個類別的每一種的可能性。 -
同時,要對這些 bounding boxes 的 shape 進行微調,以使得其符合物體的 外接矩形。
-
還有就是,為了處理相同物體的不同尺寸的情況,SSD 結合了不同解析度的 feature maps 的 predictions。
相對於那些需要 object proposals 的檢測模型,本文的 SSD 方法完全取消了 proposals generation、pixel resampling 或者 feature resampling 這些階段。這樣使得 SSD 更容易去優化訓練,也更容易地將檢測模型融合進系統之中。
在 PASCAL VOC、MS COCO、ILSVRC 資料集上的實驗顯示,SSD 在保證精度的同時,其速度要比用 region proposals 的方法要快很多。
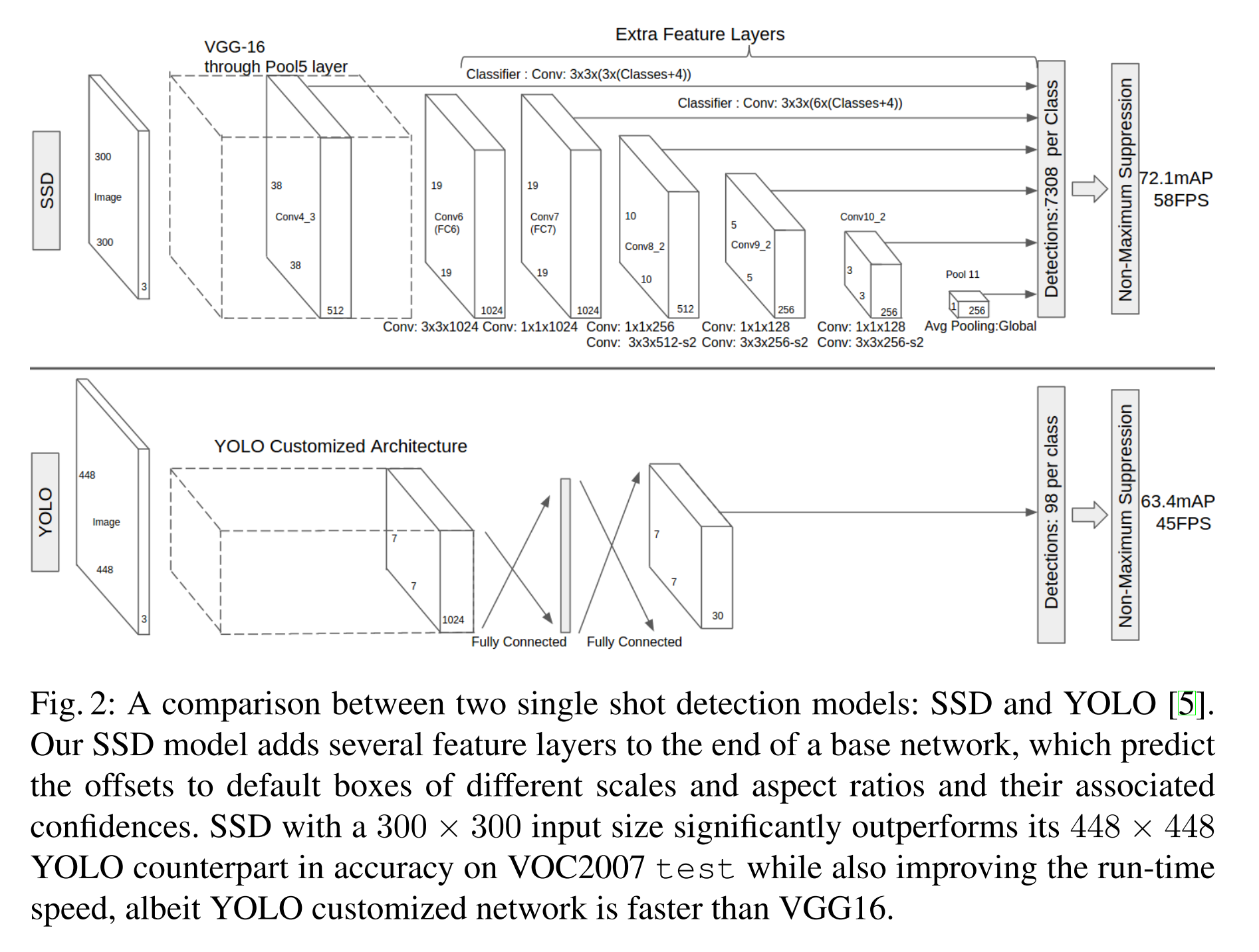
SSD 相比較於其他單結構模型(YOLO),SSD 取得更高的精度,即是是在輸入影象較小的情況下。如輸入 大小的 PASCAL VOC 2007 test 影象,在 Titan X 上,SSD 以 58 幀的速率,同時取得了 的 mAP。
如果輸入的影象是 ,SSD 則取得了 的 mAP,比目前最 state-of-art 的 Faster R-CNN 要好很多。
Introduction
現金流行的 state-of-art 的檢測系統大致都是如下步驟,先生成一些假設的 bounding boxes,然後在這些 bounding boxes 中提取特徵,之後再經過一個分類器,來判斷裡面是不是物體,是什麼物體。
這類 pipeline 自從 IJCV 2013, Selective Search for Object Recognition 開始,到如今在 PASCAL VOC、MS COCO、ILSVRC 資料集上取得領先的基於 Faster R-CNN 的 ResNet 。但這類方法對於嵌入式系統,所需要的計算時間太久了,不足以實時的進行檢測。當然也有很多工作是朝著實時檢測邁進,但目前為止,都是犧牲檢測精度來換取時間。
本文提出的實時檢測方法,消除了中間的 bounding boxes、pixel or feature resampling 的過程。雖然本文不是第一篇這樣做的文章(YOLO),但是本文做了一些提升性的工作,既保證了速度,也保證了檢測精度。
這裡面有一句非常關鍵的話,基本概括了本文的核心思想:
Our improvements include using a small convolutional filter to predict object categories and offsets in bounding box locations, using separate predictors (filters) for different aspect ratio detections, and applying these filters to multiple feature maps from the later stages of a network in order to perform detection at multiple scales.
本文的主要貢獻總結如下:
-
提出了新的物體檢測方法:SSD,比原先最快的 YOLO: You Only Look Once 方法,還要快,還要精確。保證速度的同時,其結果的 mAP 可與使用 region proposals 技術的方法(如 Faster R-CNN)相媲美。
-
SSD 方法的核心就是 predict object(物體),以及其 歸屬類別的 score(得分);同時,在 feature map 上使用小的卷積核,去 predict 一系列 bounding boxes 的 box offsets。
-
本文中為了得到高精度的檢測結果,在不同層次的 feature maps 上去 predict object、box offsets,同時,還得到不同 aspect ratio 的 predictions。
-
本文的這些改進設計,能夠在當輸入解析度較低的影象時,保證檢測的精度。同時,這個整體 end-to-end 的設計,訓練也變得簡單。在檢測速度、檢測精度之間取得較好的 trade-off。
-
本文提出的模型(model)在不同的資料集上,如 PASCAL VOC、MS COCO、ILSVRC, 都進行了測試。在檢測時間(timing)、檢測精度(accuracy)上,均與目前物體檢測領域 state-of-art 的檢測方法進行了比較。
The Single Shot Detector(SSD)
這部分詳細講解了 SSD 物體檢測框架,以及 SSD 的訓練方法。
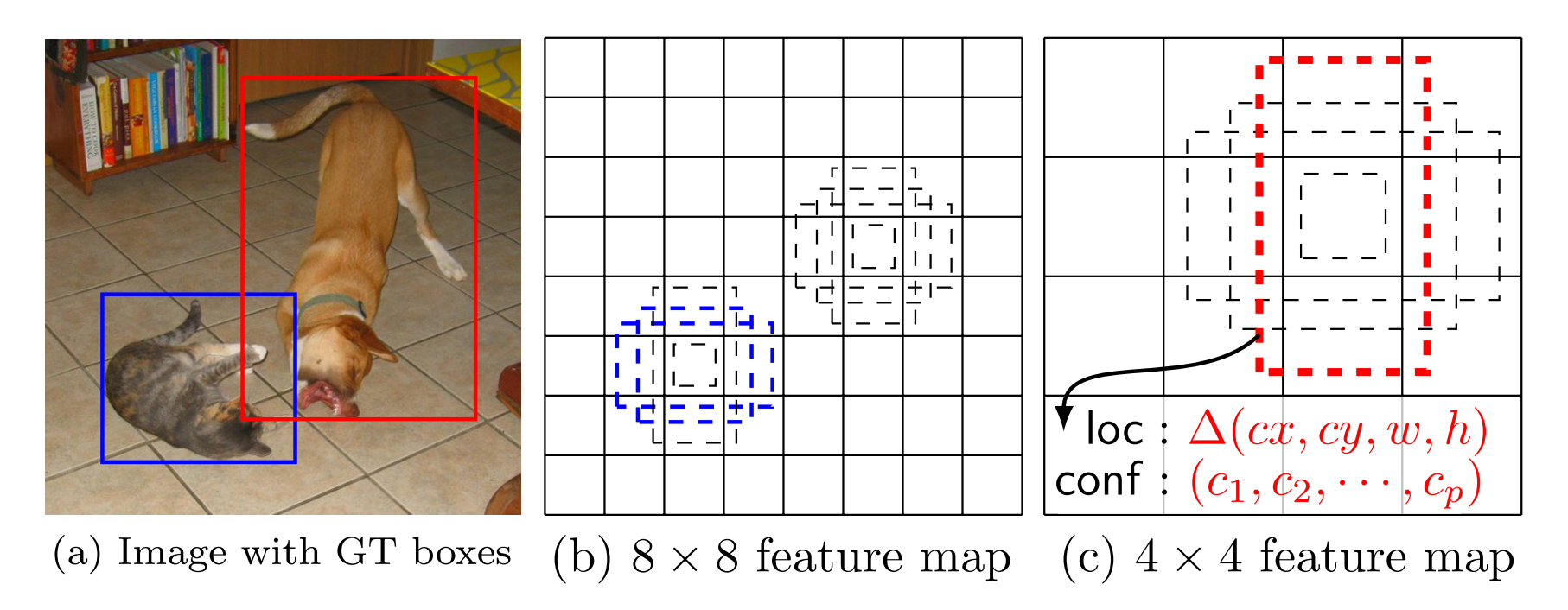
這裡,先弄清楚下文所說的 default box 以及 feature map cell 是什麼。看下圖:
-
feature map cell 就是將 feature map 切分成 或者 之後的一個個 格子;
-
而 default box 就是每一個格子上,一系列固定大小的 box,即圖中虛線所形成的一系列 boxes。
Model
SSD 是基於一個前向傳播 CNN 網路,產生一系列 固定大小(fixed-size) 的 bounding boxes,以及每一個 box 中包含物體例項的可能性,即 score。之後,進行一個 非極大值抑制(Non-maximum suppression) 得到最終的 predictions。
SSD 模型的最開始部分,本文稱作 base network,是用於影象分類的標準架構。在 base network 之後,本文添加了額外輔助的網路結構:
-
Multi-scale feature maps for detection 在基礎網路結構後,添加了額外的卷積層,這些卷積層的大小是逐層遞減的,可以在多尺度下進行 predictions。
-
Convolutional predictors for detection 每一個新增的特徵層(或者在基礎網路結構中的特徵層),可以使用一系列 convolutional filters,去產生一系列固定大小的 predictions,具體見 Fig.2。對於一個大小為 ,具有 通道的特徵層,使用的 convolutional filters 就是 的 kernels。產生的 predictions,那麼就是歸屬類別的一個得分,要麼就是相對於 default box coordinate 的 shape offsets。 在每一個 的特徵圖位置上,使用上面的 的 kernel,會產生一個輸出值。bounding box offset 值是輸出的 default box 與此時 feature map location 之間的相對距離(YOLO 架構則是用一個全連線層來代替這裡的卷積層)。
-
Default boxes and aspect ratios 每一個 box 相對於與其對應的 feature map cell 的位置是固定的。 在每一個 feature map cell 中,我們要 predict 得到的 box 與 default box 之間的 offsets,以及每一個 box 中包含物體的 score(每一個類別概率都要計算出)。 因此,對於一個位置上的 個boxes 中的每一個 box,我們需要計算出 個類,每一個類的 score,還有這個 box 相對於 它的預設 box 的 4 個偏移值(offsets)。於是,在 feature map 中的每一個 feature map cell 上,就需要有 個 filters。對於一張 大小的 feature map,即會產生 個輸出結果。
這裡的 default box 很類似於 Faster R-CNN 中的 Anchor boxes,關於這裡的 Anchor boxes,詳細的參見原論文。但是又不同於 Faster R-CNN 中的,本文中的 Anchor boxes 用在了不同解析度的 feature maps 上。
Training
在訓練時,本文的 SSD 與那些用 region proposals + pooling 方法的區別是,SSD 訓練影象中的 groundtruth 需要賦予到那些固定輸出的 boxes 上。在前面也已經提到了,SSD 輸出的是事先定義好的,一系列固定大小的 bounding boxes。
如下圖中,狗狗的 groundtruth 是紅色的 bounding boxes,但進行 label 標註的時候,要將紅色的 groundtruth box 賦予 圖(c)中一系列固定輸出的 boxes 中的一個,即 圖(c)中的紅色虛線框。
事實上,文章中指出,像這樣定義的 groundtruth boxes 不止在本文中用到。在 YOLO 中,在 Faster R-CNN中的 region proposal 階段,以及在 MultiBox 中,都用到了。
當這種將訓練影象中的 groundtruth 與固定輸出的 boxes 對應之後,就可以 end-to-end 的進行 loss function 的計算以及 back-propagation 的計算更新了。
訓練中會遇到一些問題:
-
選擇一系列 default boxes
-
選擇上文中提到的 scales 的問題
-
hard negative mining
-
資料增廣的策略
下面會談本文的解決這些問題的方式,分為以下下面的幾個部分。
Matching strategy:
如何將 groundtruth boxes 與 default boxes 進行配對,以組成 label 呢?
在開始的時候,用 MultiBox 中的 best jaccard overlap 來匹配每一個 ground truth box 與 default box,這樣就能保證每一個 groundtruth box 與唯一的一個 default box 對應起來。
但是又不同於 MultiBox ,本文之後又將 default box 與任何的 groundtruth box 配對,只要兩者之間的jaccard overlap 大於一個閾值,這裡本文的閾值為 0.5。
Training objective:
SSD 訓練的目標函式(training objective)源自於 MultiBox 的目標函式,但是本文將其拓展,使其可以處理多個目標類別。用 表示 第 個 default box 與 類別 的 第 個 ground truth box 相匹配,否則若不匹配的話,則 。
根據上面的匹配策略,一定有 ,意味著對於 第 個 ground truth box,有可能有多個 default box與其相匹配。
總的目標損失函式(objective loss function)就由 localization loss(loc) 與 confidence loss(conf) 的加權求和:
其中:
-
是與 ground truth box 相匹配的 default boxes 個數
-
localization loss(loc) 是 Fast R-CNN 中 Smooth L1 Loss,用在 predict box() 與 ground truth box() 引數(即中心座標位置,width、height)中,迴歸 bounding boxes 的中心位置,以及 width、height
-
confidence loss(conf) 是 Softmax Loss,輸入為每一類的置信度
-
權重項 ,設定為 1
Choosing scales and aspect ratios for default boxes:
大部分 CNN 網路在越深的層,feature map 的尺寸(size)會越來越小。這樣做不僅僅是為了減少計算與記憶體的需求,還有個好處就是,最後提取的 feature map 就會有某種程度上的平移與尺度不變性。
但是其實,如果使用同一個網路中的、不同層上的 feature maps,也可以達到相同的效果,同時在所有物體尺度中共享引數。
因此,本文同時使用 lower feature maps、upper feature maps 來 predict detections。下圖展示了本文中使用的兩種不同尺度的 feature map, 的feature map,以及 的 feature map:
一般來說,一個 CNN 網路中不同的 layers 有著不同尺寸的 感受野(receptive fields)。這裡的感受野,指的是輸出的 feature map 上的一個節點,其對應輸入影象上尺寸的大小。具體的感受野的計算,參見兩篇 blog:
所幸的是,SSD 結構中,default boxes 不必要與每一層 layer 的 receptive fields 對應。本文的設計中,feature map 中特定的位置,來負責影象中特定的區域,以及物體特定的尺寸。加入我們用 個 feature maps 來做 predictions,每一個 feature map 中 default box 的尺寸大小計算如下:
其中, 取值 , 取值 ,意味著最低層的尺度是 ,最高層的尺度是 ,再用不同 aspect ratio 的 default boxes,用 來表示:,則每一個 default boxes 的 width、height 就可以計算出來: 對於 aspect ratio 為 1 時,本文還增加了一個 default box,這個 box 的 scale 是 。所以最終,在每個 feature map location 上,有 6 個 default boxes。
每一個 default box 的中心,設定為:,其中, 是第 個 feature map 的大小,同時,。
在結合 feature maps 上,所有 不同尺度、不同 aspect ratios 的 default boxes,它們預測的 predictions 之後。可以想見,我們有許多個 predictions,包含了物體的不同尺寸、形狀。如下圖,狗狗的 ground truth box 與 feature map 中的紅色 box 吻合,所以其餘的 boxes 都看作負樣本。
Hard negative mining
在生成一系列的 predictions 之後,會產生很多個符合 ground truth box 的 predictions boxes,但同時,不符合 ground truth boxes 也很多,而且這個 negative boxes,遠多於 positive boxes。這會造成 negative boxes、positive boxes 之間的不均衡。訓練時難以收斂。
因此,本文采取,先將每一個物體位置上對應 predictions(default boxes)是 negative 的 boxes 進行排序,按照 default boxes 的 confidence 的大小。 選擇最高的幾個,保證最後 negatives、positives 的比例在 。
本文通過實驗發現,這樣的比例可以更快的優化,訓練也更穩定。
Data augmentation
本文同時對訓練資料做了 data augmentation,資料增廣。關於資料增廣,推薦一篇文章:Must Know Tips/Tricks in Deep Neural Networks,其中的 section 1 就講了 data augmentation 技術。
每一張訓練影象,隨機的進行如下幾種選擇:
- 使用原始的影象
- 取樣一個 patch,與物體之間最小的 jaccard overlap 為:,,, 與
- 隨機的取樣一個 patch
取樣的 patch 是原始影象大小比例是 ,aspect ratio 在 與 之間。
當 groundtruth box 的 中心(center)在取樣的 patch 中時,我們保留重疊部分。
在這些取樣步驟之後,每一個取樣的 patch 被 resize 到固定的大小,並且以 的概率隨機的 水平翻轉(horizontally flipped)
Experimental Results
Base network and hole filling algorithm
與 ICLR 2015, DeepLab-LargeFOV 的工作類似,本文將 VGG 中的 FC6 layer、FC7 layer 轉成為 卷積層,並從模型的 FC6、FC7 上的引數,進行取樣得到這兩個卷積層的 parameters。
還將 Pool5 layer 的引數,從 轉變成 ,外加一個 pad(1),如下圖:
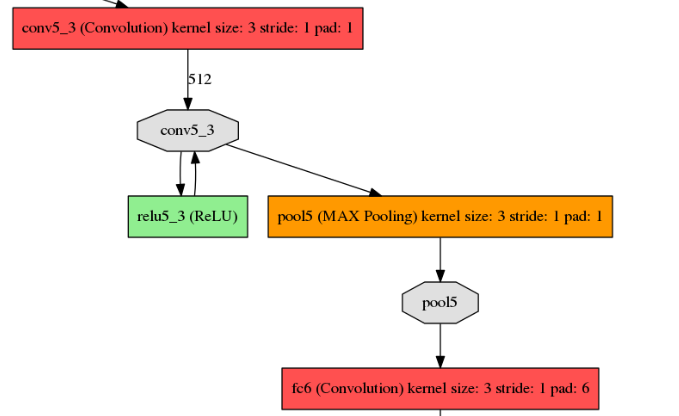
但是這樣變化後,會改變感受野(receptive field)的大小。因此,採用了 atrous algorithm 的技術,這裡所謂的 atrous algorithm,我查閱了資料,就是 hole filling algorithm。
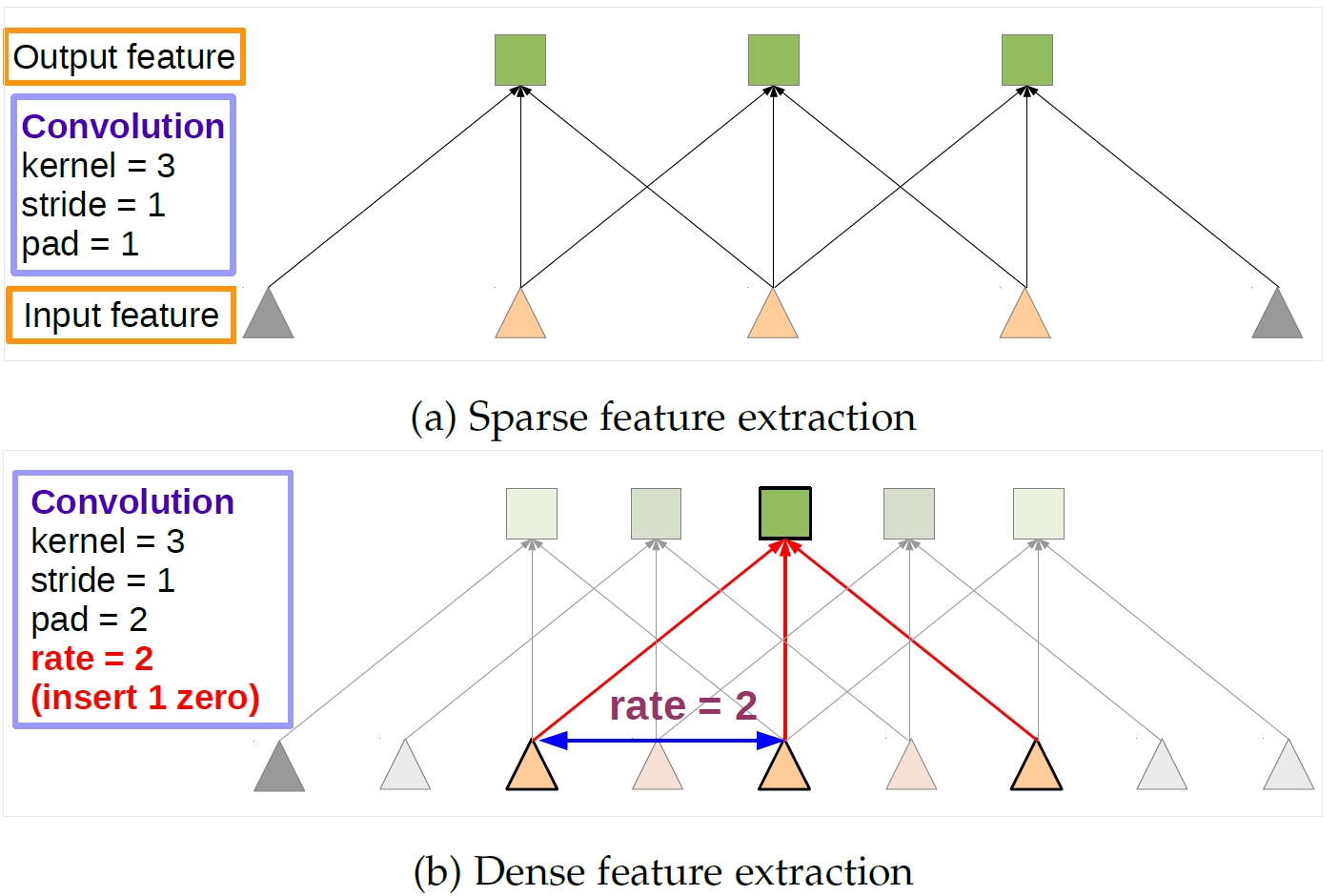
最早用的就是 deeplab 的文章了,Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFS 這篇文章和 fcn 不同的是,在最後產生 score map 時,不是進行upsampling,而是採用了 hole algorithm,就是在 pool4 和 pool 5層,步長由 2 變成 1,必然輸出的 score map 變大了,但是 receptive field 也變小了,為了不降低 receptive field,怎麼做呢?利用 hole algorithm,將卷積 weights 膨脹擴大,即原來卷積核是 3x3,膨脹後,可能變成 7x7 了,這樣 receptive field 變大了,而 score map 也很大,即輸出變成 dense 的了。
這麼做的好處是,輸出的 score map 變大了,即是 dense 的輸出了,而且 receptive field 不會變小,而且可以變大。這對做分割、檢測等工作非常重要。
既想利用已經訓練好的模型進行 fine-tuning,又想改變網路結構得到更加 dense 的 score map.
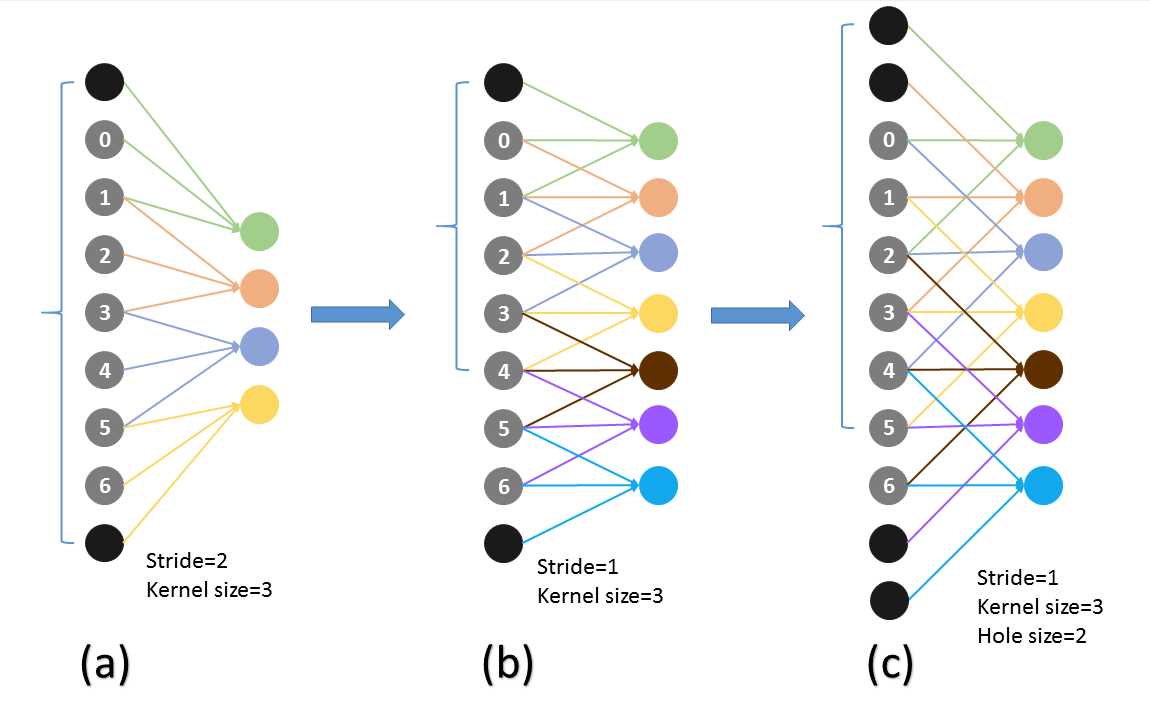
這個解決辦法就是採用 Hole 演算法。如下圖 (a) (b) 所示,在以往的卷積或者 pooling 中,一個 filter 中相鄰的權重作用在 feature map 上的位置都是物理上連續的。如下圖 (c) 所示,為了保證感受野不發生變化,某一層的 stride 由 2 變為 1 以後,後面的層需要採用 hole 演算法,具體來講就是將連續的連線關係是根據 hole size 大小變成 skip 連線的(圖 (c) 為了顯示方便直接畫在本層上了)。不要被 (c) 中的 padding 為 2 嚇著了,其實 2 個 padding 不會同時和一個 filter 相連。
pool4 的 stride 由 2 變為 1,則緊接著的 conv5_1, conv5_2 和 conv5_3 中 hole size 為 2。接著 pool5 由 2 變為 1 , 則後面的 fc6 中 hole size 為 4。
本文在 fine-tuning 預訓練的 VGG model 時,初始 learning rate 為 ,momentum 為 ,weight decay 為 ,batch size 為 ,learning rate decay 的策略隨資料集的不同而變化。
PASCAL VOC 2007
在這個資料集中,與 Fast R-CNN、Faster R-CNN 進行了比較,幾種檢測網路都用相同的訓練資料集,以及預訓練模型(VGG16)。
測試集選取的是 VOC 2007 test,共計 4952 張影象。
下圖展示了 SSD300 model 的結構:

我們用 conv4_3,conv7(原先的 FC7),conv8_2,conv9_2,conv10_2,以及 pool11,這些 layer 來predict location、 confidence。
因為 conv4_3 的尺寸比較大,size 為 的大小,我們只在上面放置 3 個 default boxes,一個 box 的 scale 為 ,另外兩個 boxes 的 aspect ratio 分別為 、。但對於其他的用來做 predictions 的 layers,本文都放了 個 default boxes。
文獻 ICLR 2016, ParseNet: Looking wider to see better 指出,conv4_3 相比較於其他的 layers,有著不同的 feature scale,我們使用 ParseNet 中的 L2 normalization 技術將 conv4_3 feature map 中每一個位置的 feature norm scale 到 20,並且在 back-propagation 中學習這個 scale。
在最開始的 40K 次迭代中,本文使用的 learning rate 是 ,之後將其減小到 ,再接著迭代 20K 次。
下面 Table 1 顯示了,我們的 SSD300 model 的精度已經超過了 Fast R-CNN,當我們用 SSD 在更大的影象尺寸上, 訓練得到的 model,甚至要比 Faster R-CNN 還要高出 的 mAP。

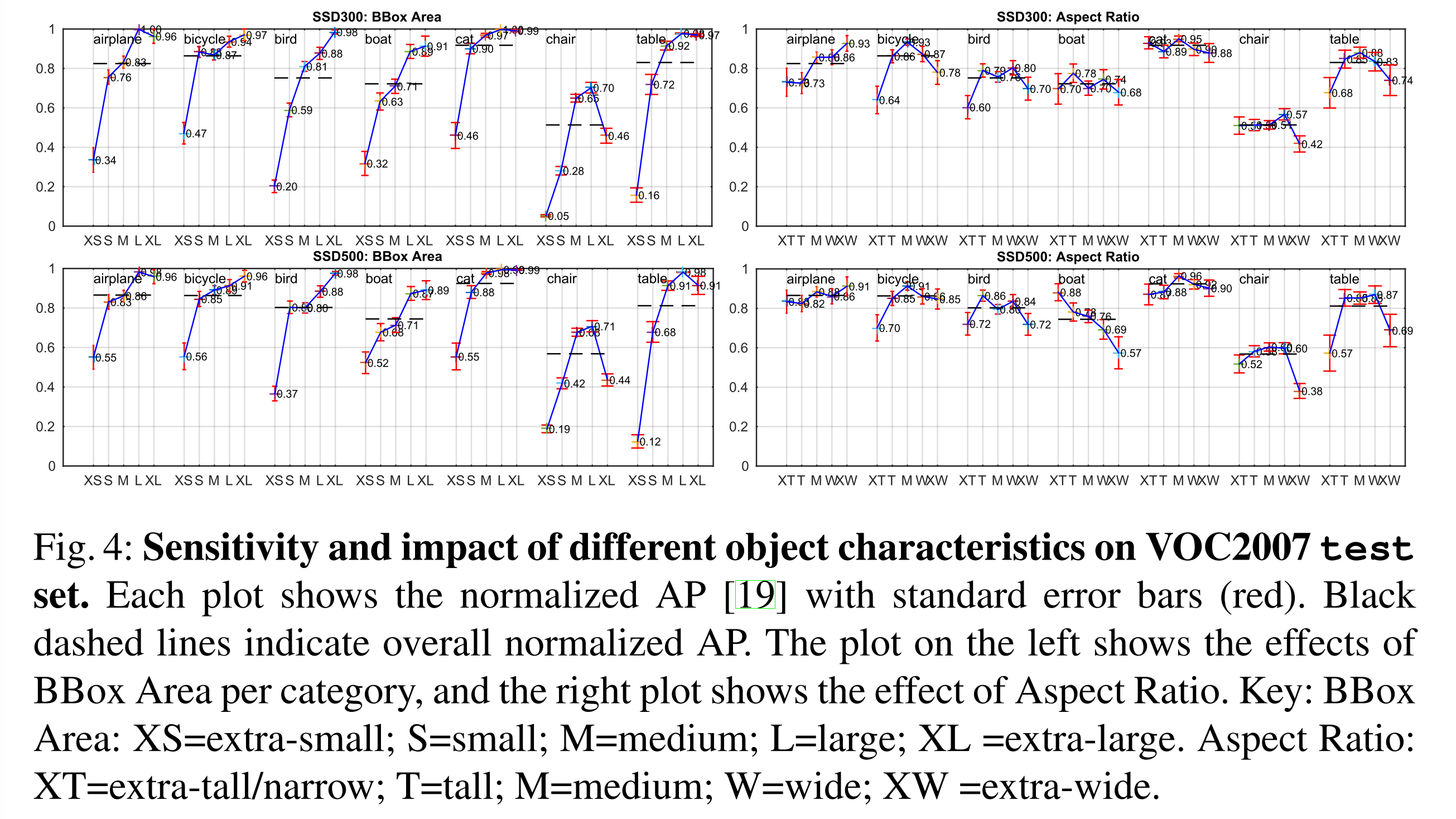
為了更細節的瞭解本文的兩個 SSD model,我們使用了 ECCV 2012, Diagnosing error in object detectors 的檢測分析工具。下圖 Figure 3 顯示了 SSD 可以高質量的檢測不同種類的物體。
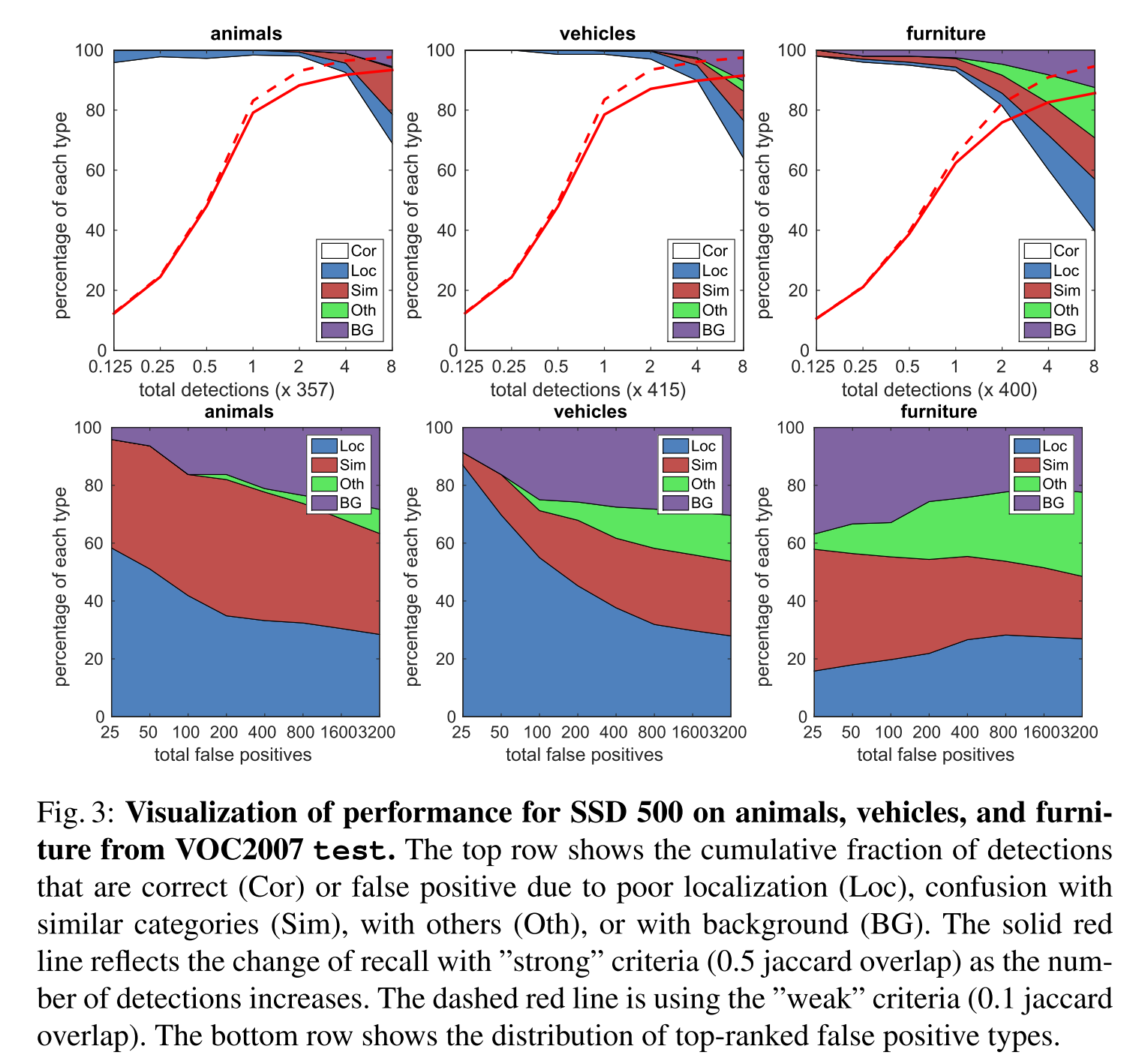
下圖 Figure 4 展示了 SSD 模型對 bounding box 的 size 非常的敏感。也就是說,SSD 對小物體目標較為敏感,在檢測小物體目標上表現較差。其實這也算情理之中,因為對於小目標而言,經過多層卷積之後,就沒剩多少資訊了。雖然提高輸入影象的 size 可以提高對小目標的檢測效果,但是對於小目標檢測問題,還是有很多提升空間的。
同時,積極的看,SSD 對大目標檢測效果非常好。同時,因為本文使用了不同 aspect ratios 的 default boxes,SSD 對於不同 aspect ratios 的物體檢測效果也很好。
Model analysis
為了更好的理解 SSD,本文還使用控制變數法來驗證 SSD 中的每一部分對最終結果效能的影響。測試如下表 Table 2 所示:

從上表可以看出一下幾點:
-
資料增廣(Data augmentation)對於結果的提升非常明顯 Fast R-CNN 與 Faster R-CNN 使用原始影象,以及 0.5 的概率對原始影象進行水平翻轉(horizontal flip),進行訓練。如上面寫的,本文還使用了額外的 sampling 策略,YOLO 中還使用了 亮度扭曲(photometric distortions),但是本文中沒有使用。 做了資料增廣,將 mAP 從 提升到了 ,提升了 。 我們還不清楚,本文的 sampling 策略會對 Fast R-CNN、Faster R-CNN 有多少好處。但是估計不會很多,因為 Fast R-CNN、Faster R-CNN 使用了 feature pooling,這比人為的對資料進行增廣擴充,還要更 robust。
-
使用更多的 feature maps 對結果提升更大 類似於 FCN,使用含影象資訊更多的低 layer 來提升影象分割效果。我們也使用了 lower layer feature maps 來進行 predict bounding boxes。 我們比較了,當 SSD 不使用 conv4_3 來 predict boxes 的結果。當不使用 conv4_3,mAP 下降到了 。 可以看見,低層的 feature map 蘊含更多的資訊,對於影象分割、物體檢測效能提升幫助很大的。
-
使用更多的 default boxes,結果也越好 如 Table 2 所示,SSD 中我們預設使用 6 個 default boxes(除了 conv4_3 因為大小問題使用了 3 個 default boxes)。如果將 aspect ratios 為 、 的 boxes 移除,performance 下降了 。如果再進一步的,將 、 的 default boxes 移除,那麼 performance 下降了近 。
-
Atrous 使得 SSD 又好又快 如前面所描述,我們根據 ICLR 2015, DeepLab-LargeFOV,使用結合 atrous algorithm 的 VGG16 版本。 如果我們使用原始的 VGG16 版本,即保留 pool5 的引數為:,且不從 FC6,FC7 上採集 parameters,同時新增 conv5_3 來做 prediction,結果反而會下降 。同時最關鍵的,速度慢了 。
PASCAL VOC 2012
本文又在 VOC 2012 test 上進行的實驗,比較結果如下:

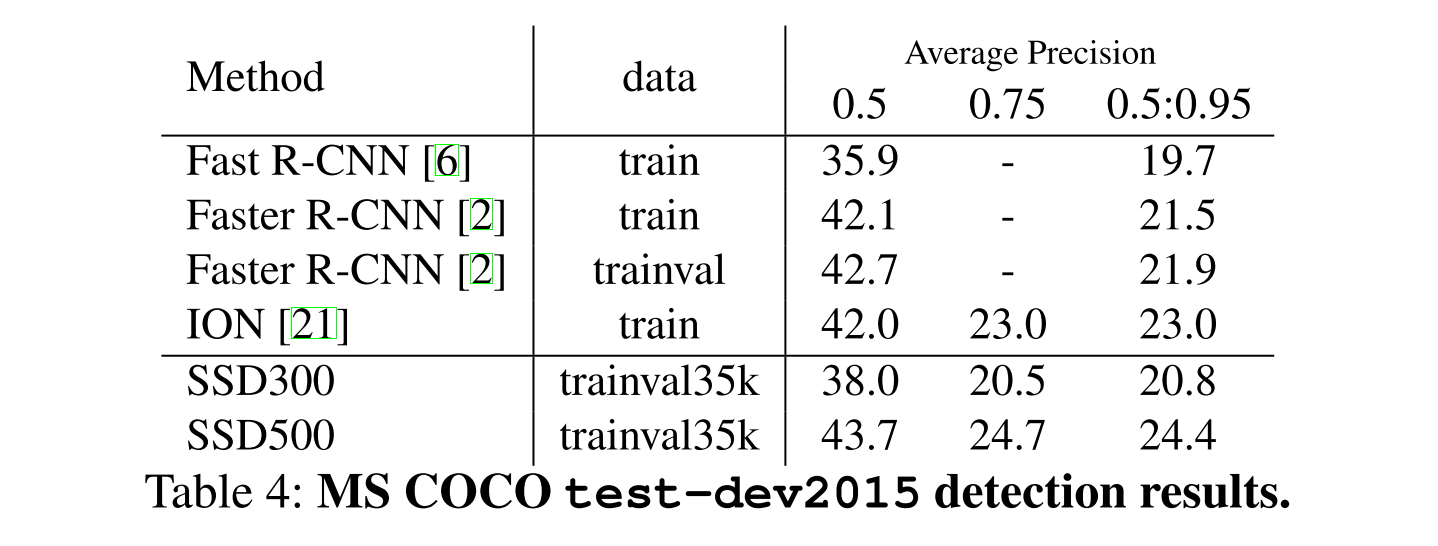
MS COCO
為了進一步的驗證本文的 SSD 模型,我們將 SSD300、SSD500 在 MS COCO 資料集上進行訓練檢測。
因為 COCO 資料集中的檢測目標更小,我們在所有的 layers 上,使用更小的 default boxes。
這裡,還跟 ION 檢測方法 進行了比較。
總的結果如下:
Inference time
本文的方法一開始會生成大量的 bounding boxes,所以有必要用 Non-maximum suppression(NMS)來去除大量重複的 boxes。
通過設定 confidence 的閾值為 ,我們可以過濾掉大多數的 boxes。
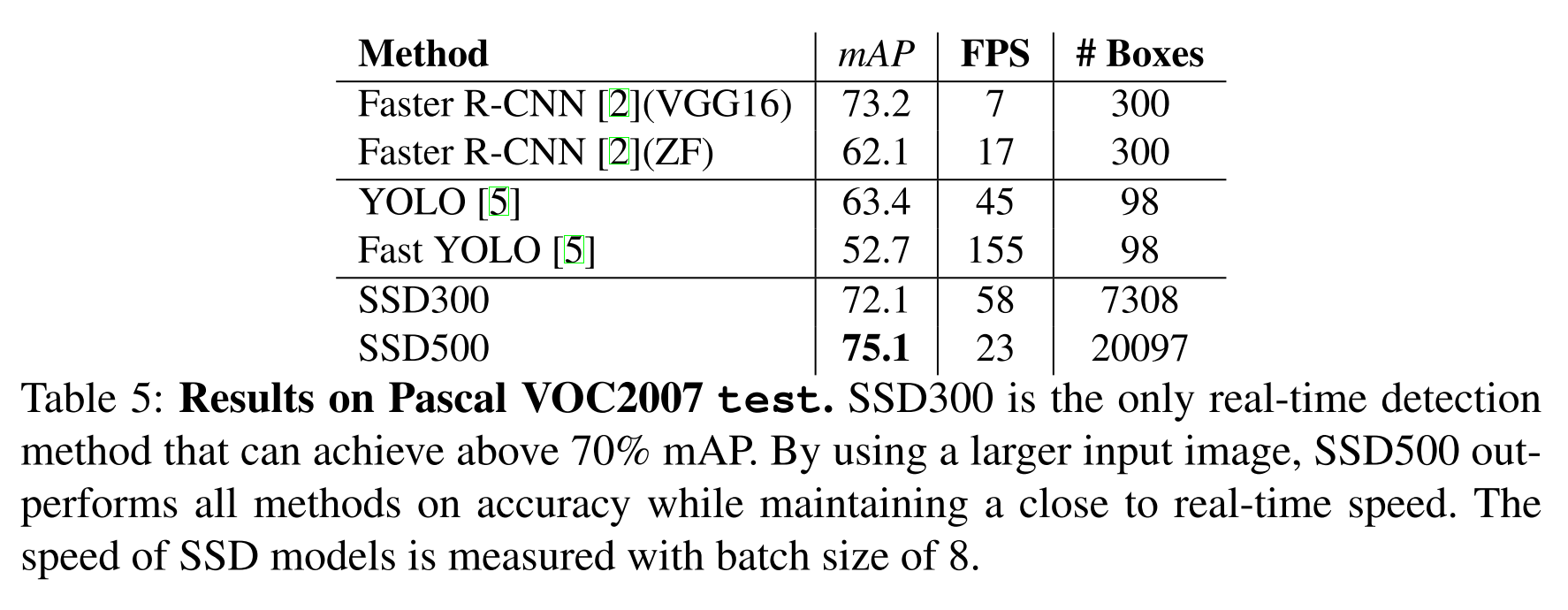
之後,我們再用 Thrust CUDA library 進行排序,用 GPU 版本的實現來計算剩下的 boxes 兩兩之間的 overlap。然後,進行 NMS,每一張影象保留 top 200 detections。這一步 SSD300 在 VOC 20 類的每張影象上,需要耗時 。
下面是在 PASCAL VOC 2007 test 上的速度統計:
Related work and result images
這篇文章居然把相關工作總結放在最後面,我還是第一次見到。
具體的看原文吧。
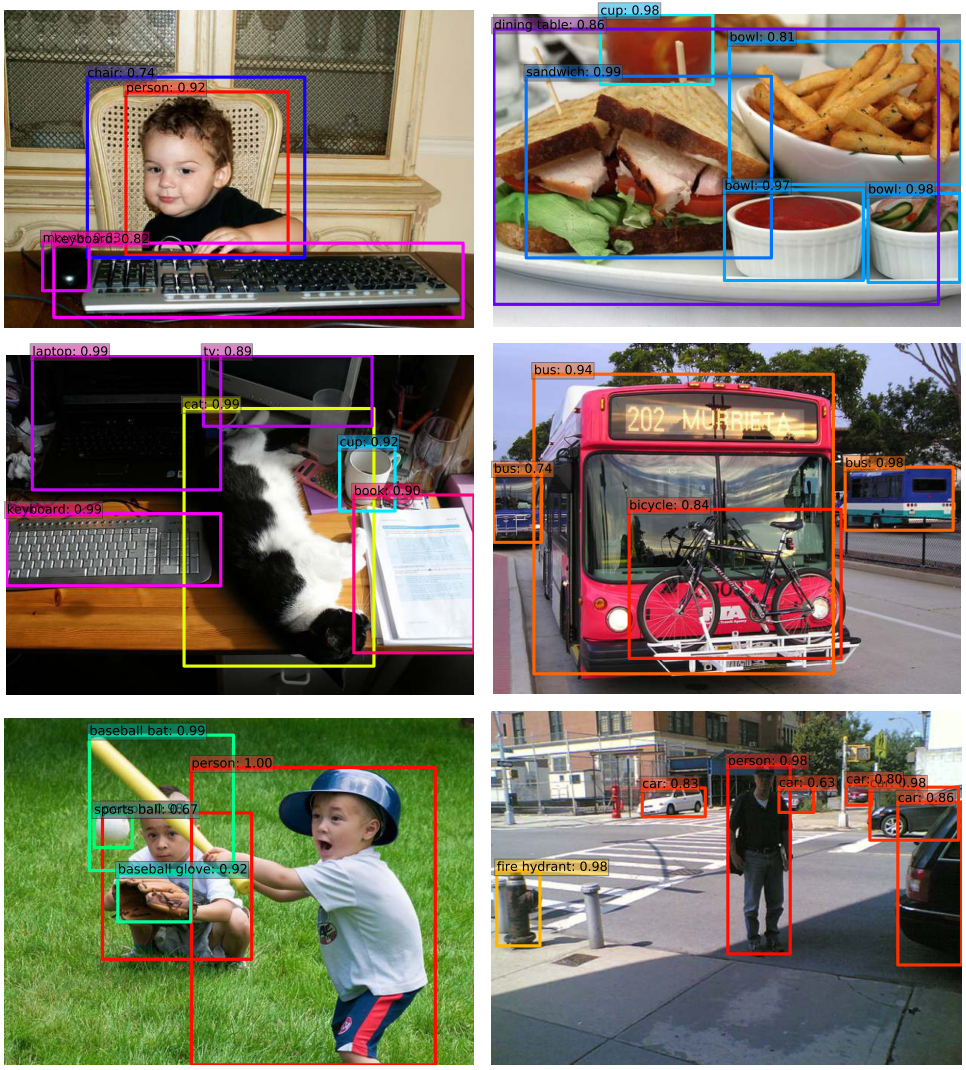
最後放幾張結果圖: