
15年來,自然語言處理神經網路相關技術發展史上的8大里程碑
原標題:15年來,自然語言處理髮展史上的8大里程碑
自然語言是人類獨有的智慧結晶。自然語言處理(Natural Language Processing,NLP)是電腦科學領域與人工智慧領域中的一個重要方向,旨在研究能實現人與計算機之間用自然語言進行有效通訊的各種理論和方法。用自然語言與計算機進行通訊,有著十分重要的實際應用意義,也有著革命性的理論意義。
由於理解自然語言,需要關於外在世界的廣泛知識以及運用操作這些知識的能力,所以自然語言處理,也被視為解決人工智慧完備(AI-complete)的核心問題之一。對自然語言處理的研究也是充滿魅力和挑戰的。
本文是來自自然語言處理領域從業人員、知名博主 Sebatian Ruder的一篇文章,
2001年——神經語言模型(Neurallanguage models)
語言模型解決的是在給定已出現詞語的文字中,預測下一個單詞的任務。這可以算是最簡單的語言處理任務,但卻有許多具體的實際應用,例如智慧鍵盤、電子郵件回覆建議等。當然,語言模型的歷史由來已久。經典的方法基於 n-grams 模型(利用前面 n 個詞語預測下一個單詞),並利用平滑操作處理不可見的 n-grams。
第一個神經語言模型,前饋神經網路(feed-forward neuralnetwork),是 Bengio 等人於 2001 年提出的。如圖 1 所示。
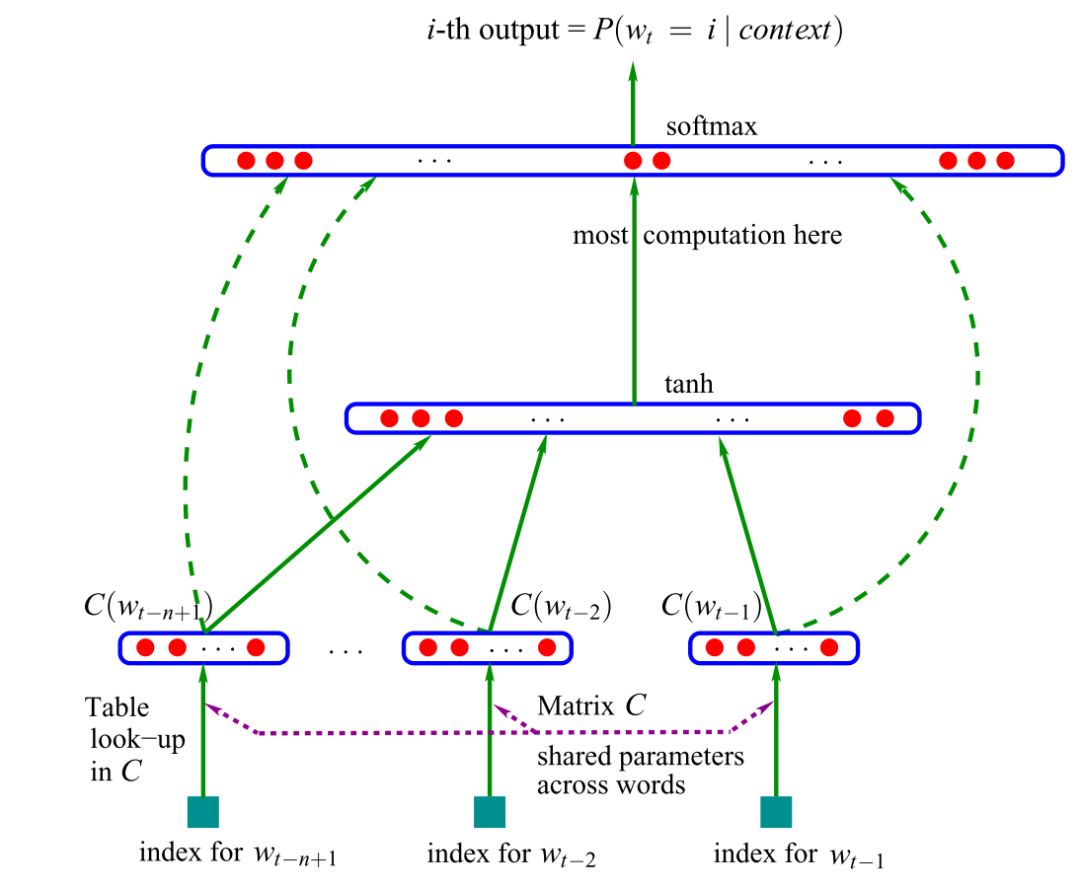
圖 1 | 前饋神經網路語言模型(Bengio et al., 2001; 2003)
這個模型以某詞語之前出現的 n 個詞語作為輸入向量。今天,這樣的向量被稱為大家熟知的詞嵌入(word embeddings)。這些詞嵌入在級聯後進入一個隱藏層,該層的輸出然後通過一個 softmax 層。
近年來,用於構建語言模型的前饋神經網路已經被迴圈神經網路(RNNs)和長短期記憶神經網路(LSTMs)取代。雖然後來提出的許多新模型在經典的 LSTM 上進行了擴充套件,但它仍然是強有力的基礎模型。甚至 Bengio 等人的經典前饋神經網路在某些設定下也和更復雜的模型效果相當,因為這些任務只需要考慮鄰近的詞語。更好地理解語言模型究竟捕捉了哪些資訊也是當今一個活躍的研究領域。
語言模型的建立是一種無監督學習(unsupervised learning),Yann LeCun 也將其稱之為預測學習(predictive learning),是獲得世界如何運作常識的先決條件。關於語言模型最引人注目的是,儘管它很簡單,但卻與後文許多核心進展息息相關。
反過來,這也意味著自然語言處理領域的許多重要進展都可以簡化為某種形式的語言模型構建。但要實現對自然語言真正意義上的理解,僅僅從原始文字中進行學習是不夠的,我們需要新的方法和模型。
2008年——多工學習(Multi-tasklearning)
多工學習是在多個任務下訓練的模型之間共享引數的方法,在神經網路中可以通過捆綁不同層的權重輕鬆實現。多工學習的思想在 1993 年由 Rich Caruana 首次提出,並應用於道路追蹤和肺炎預測。多工學習鼓勵模型學習對多個任務有效的表徵描述。這對於學習一般的、低階的描述形式、集中模型的注意力或在訓練資料有限的環境中特別有用。
多工學習於 2008 年被Collobert 和 Weston 等人首次在自然語言處理領域應用於神經網路。在他們的模型中,詞嵌入矩陣被兩個在不同任務下訓練的模型共享,如圖 2 所示。

圖 2 | 詞嵌入矩陣共享(Collobert & Weston, 2008; Collobert et al., 2011)
共享的詞嵌入矩陣使模型可以相互協作,共享矩陣中的低層級資訊,而詞嵌入矩陣往往構成了模型中需要訓練的絕大部分引數。Collobert 和 Weston 發表於 2008 年的論文,影響遠遠超過了它在多工學習中的應用。它開創的諸如預訓練詞嵌入和使用卷積神經網路處理文字的方法,在接下來的幾年被廣泛應用。他們也因此獲得了 2018 年機器學習國際會議(ICML)的 test-of-time 獎。
如今,多工學習在自然語言處理領域廣泛使用,而利用現有或“人工”任務已經成為 NLP 指令庫中的一個有用工具。雖然引數的共享是預先定義好的,但在優化的過程中卻可以學習不同的共享模式。當模型越來越多地在多個任務上進行測評以評估其泛化能力時,多工學習就變得愈加重要,近年來也湧現出更多針對多工學習的評估基準。
2013年——詞嵌入
通過稀疏向量對文字進行表示的詞袋模型,在自然語言處理領域已經有很長的歷史了。而用稠密的向量對詞語進行描述,也就是詞嵌入,則在 2001 年首次出現。2013 年Mikolov 等人工作的主要創新之處在於,通過去除隱藏層和近似計算目標使詞嵌入模型的訓練更為高效。儘管這些改變在本質上是十分簡單的,但它們與高效的 word2vec(word to vector,用來產生詞向量的相關模型)組合在一起,使得大規模的詞嵌入模型訓練成為可能。
Word2vec 有兩種不同的實現方法:CBOW(continuous bag-of-words)和 skip-gram。它們在預測目標上有所不同:一個是根據周圍的詞語預測中心詞語,另一個則恰恰相反。如圖 3 所示。
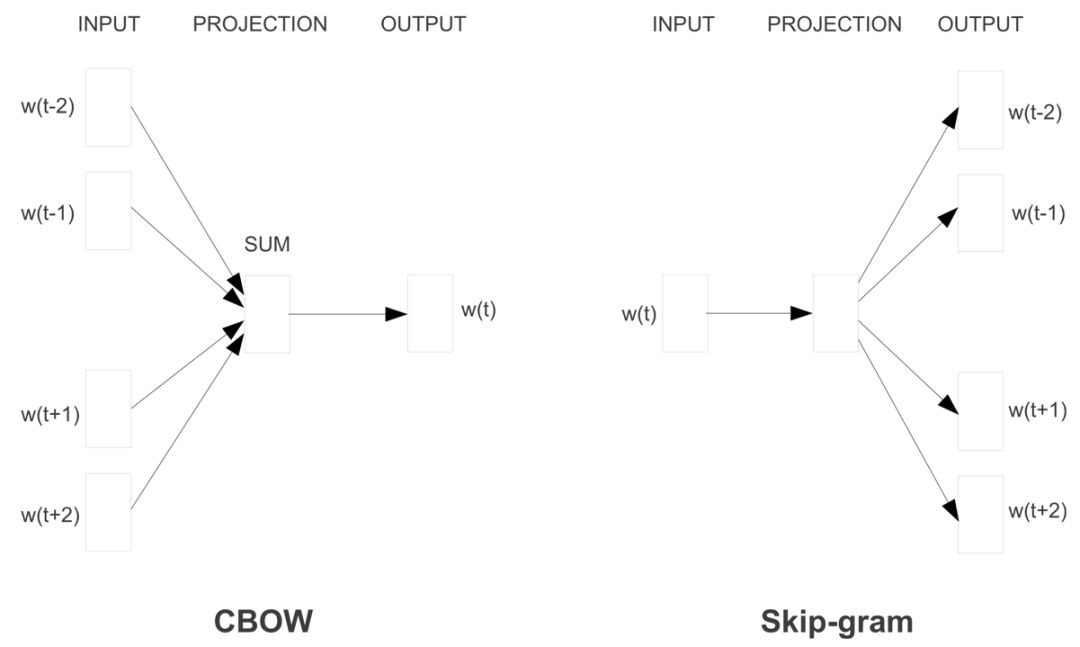
圖 3 | CBOW 和skip-gram 架構(Mikolov et al., 2013a; 2013b)
雖然這些嵌入與使用前饋神經網路學習的嵌入在概念上沒有區別,但是在一個非常大語料庫上的訓練使它們能夠獲取諸如性別、動詞時態和國際事務等單詞之間的特定關係。如下圖 4 所示。
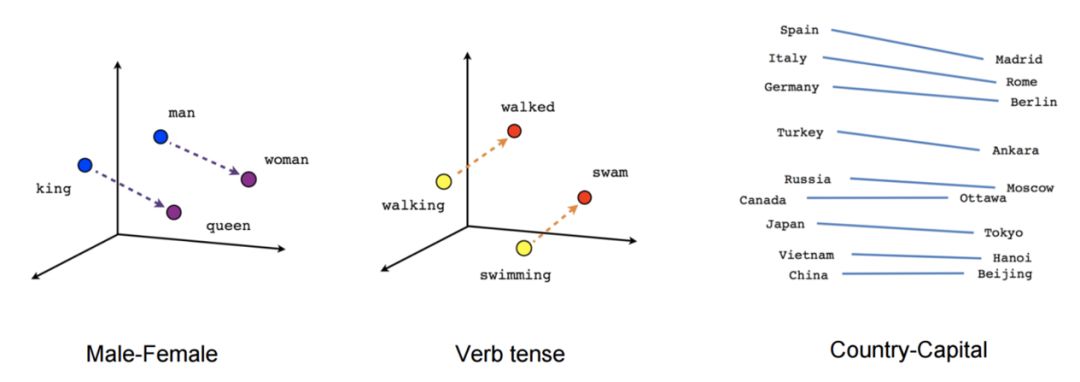
圖 4 | word2vec 捕獲的聯絡(Mikolov et al., 2013a; 2013b)
這些關係和它們背後的意義激起了人們對詞嵌入的興趣,許多研究都在關注這些線性關係的來源。然而,使詞嵌入成為目前自然語言處理領域中流砥柱的,是將預訓練的詞嵌入矩陣用於初始化可以提高大量下游任務效能的事實。
雖然 word2vec 捕捉到的關係具有直觀且幾乎不可思議的特性,但後來的研究表明,word2vec 本身並沒有什麼特殊之處:詞嵌入也可以通過矩陣分解來學習,經過適當的除錯,經典的矩陣分解方法 SVD 和 LSA 都可以獲得相似的結果。
從那時起,大量的工作開始探索詞嵌入的不同方面。儘管有很多發展,word2vec 仍然是目前應用最為廣泛的選擇。Word2vec 的應用範圍也超出了詞語級別:帶有負取樣的 skip-gram——一個基於上下文學習詞嵌入的方便目標,已經被用於學習句子的表徵。它甚至超越了自然語言處理的範圍,被應用於網路和生物序列等領域。
一個激動人心的研究方向是在同一空間中構建不同語言的詞嵌入模型,以達到(零樣本)跨語言轉換的目的。通過無監督學習構建這樣的對映變得越來越有希望(至少對於相似的語言來說),這也為語料資源較少的語言和無監督機器翻譯的應用程式創造可能。
2013年——用於自然語言處理的神經網路
2013年 和 2014 年是自然語言處理領域神經網路時代的開始。其中三種類型的神經網路應用最為廣泛:迴圈神經網路(recurrent neural networks)、卷積神經網路(convolutionalneural networks)和結構遞迴神經網路(recursive neural networks)。
迴圈神經網路是 NLP 領域處理動態輸入序列最自然的選擇。Vanilla 迴圈神經網路很快被經典的長短期記憶網路(long-shortterm memory networks,LSTM)代替,該模型能更好地解決梯度消失和梯度爆炸問題。在 2013 年之前,人們仍認為迴圈神經網路很難訓練,直到 Ilya Sutskever 博士的論文改變了迴圈神經網路這一名聲。雙向的長短期記憶記憶網路通常被用於同時處理出現在左側和右側的文字內容。LSTM 結構如圖 5 所示。
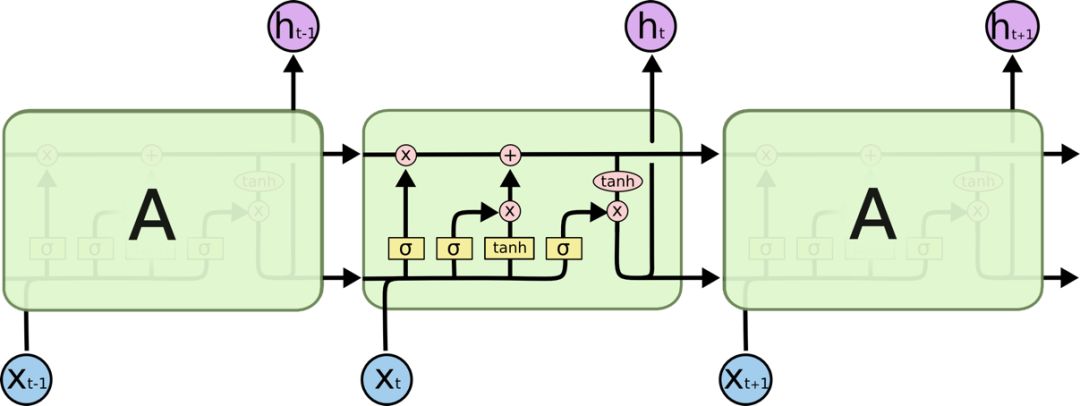
圖 5 | LSTM 網路(來源:ChrisOlah)
應用於文字的卷積神經網路只在兩個維度上進行操作,卷積層只需要在時序維度上移動即可。圖6 展示了應用於自然語言處理的卷積神經網路的典型結構。
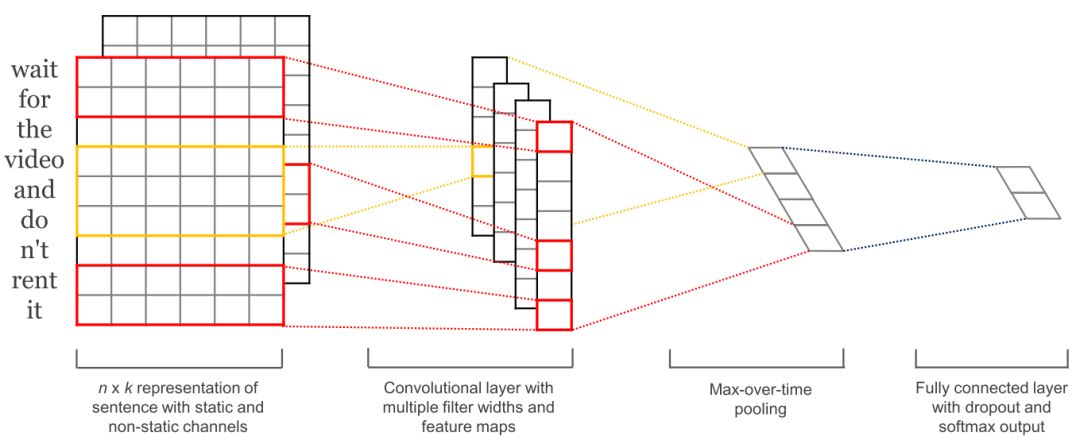
圖 6 | 卷積神經網路(Kim,2014)
與迴圈神經網路相比,卷積神經網路的一個優點是具有更好的並行性。因為卷積操作中每個時間步的狀態只依賴於區域性上下文,而不是迴圈神經網路中那樣依賴於所有過去的狀態。卷積神經網路可以使用更大的卷積層涵蓋更廣泛的上下文內容。卷積神經網路也可以和長短期記憶網路進行組合和堆疊,還可以用來加速長短期記憶網路的訓練。
迴圈神經網路和卷積神經網路都將語言視為一個序列。但從語言學的角度來看,語言是具有層級結構的:詞語組成高階的短語和小句,它們本身可以根據一定的產生規則遞迴地組合。這激發了利用結構遞迴神經網路,以樹形結構取代序列來表示語言的想法,如圖 7 所示。
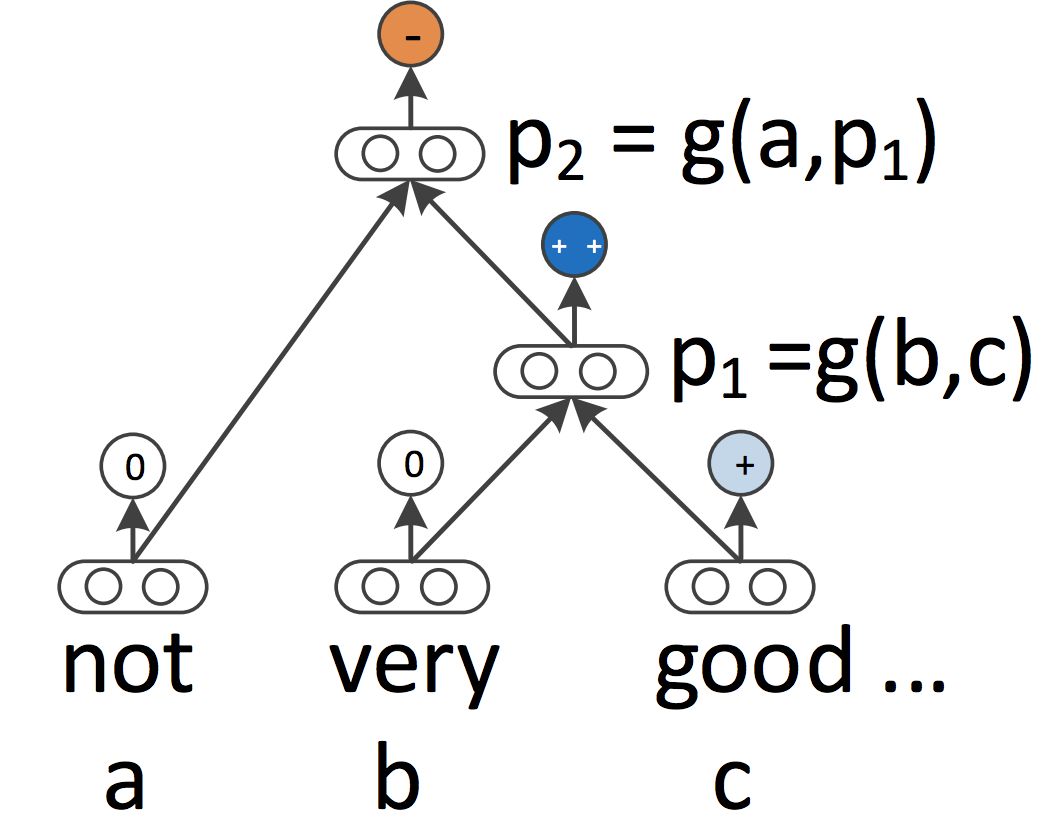
圖 7 | 結構遞迴神經網路(Socher et al., 2013)
結構遞迴神經網路自下而上構建序列的表示,與從左至右或從右至左對序列進行處理的迴圈神經網路形成鮮明的對比。樹中的每個節點是通過子節點的表徵計算得到的。一個樹也可以視為在迴圈神經網路上施加不同的處理順序,所以長短期記憶網路則可以很容易地被擴充套件為一棵樹。
不只是迴圈神經網路和長短期記憶網路可以擴充套件到使用層次結構,詞嵌入也可以在語法語境中學習,語言模型可以基於句法堆疊生成詞彙,圖形卷積神經網路可以樹狀結構執行。
2014年——序列到序列模型(Sequence-to-sequencemodels)
2014 年,Sutskever 等人提出了序列到序列學習,即使用神經網路將一個序列對映到另一個序列的一般化框架。在這個框架中,一個作為編碼器的神經網路對句子符號進行處理,並將其壓縮成向量表示;然後,一個作為解碼器的神經網路根據編碼器的狀態逐個預測輸出符號,並將前一個預測得到的輸出符號作為預測下一個輸出符號的輸入。如圖 8 所示。
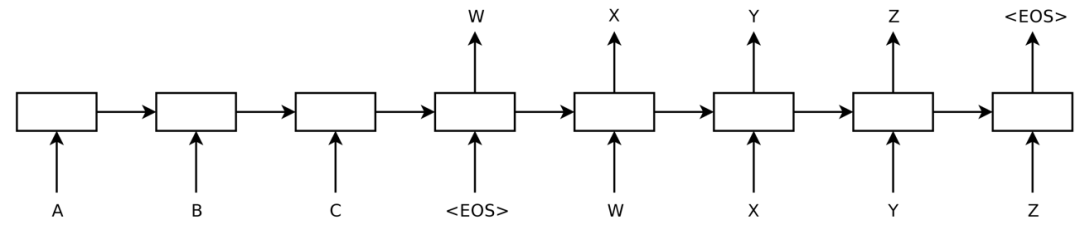
圖 8 | 序列到序列模型(Sutskever et al., 2014)
機器翻譯是這一框架的殺手級應用。2016 年,谷歌宣佈他們將用神經機器翻譯模型取代基於短語的整句機器翻譯模型。谷歌大腦負責人 Jeff Dean 表示,這意味著用 500 行神經網路模型程式碼取代 50 萬行基於短語的機器翻譯程式碼。
由於其靈活性,該框架在自然語言生成任務上被廣泛應用,其編碼器和解碼器分別由不同的模型來擔任。更重要的是,解碼器不僅可以適用於序列,在任意表示上均可以應用。比如基於圖片生成描述(如圖 9)、基於表格生成文字、根據原始碼改變生成描述,以及眾多其他應用。
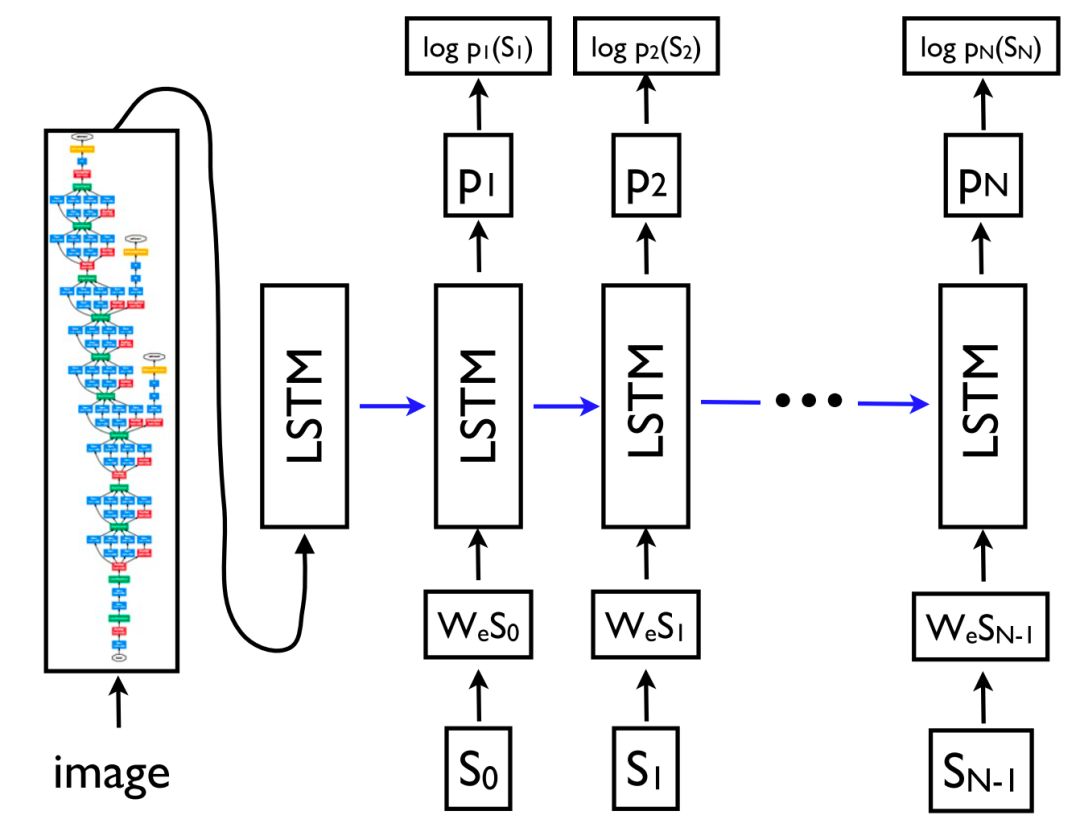
圖 9 | 基於影象生成標題(Vinyalset al., 2015)
序列到序列的學習甚至可以應用到自然語言處理領域常見的結構化預測任務中,也就是輸出具有特定的結構。為簡單起見,輸出就像選區解析一樣被線性化(如圖 10)。在給定足夠多訓練資料用於語法解析的情況下,神經網路已經被證明具有產生線性輸出和識別命名實體的能力。
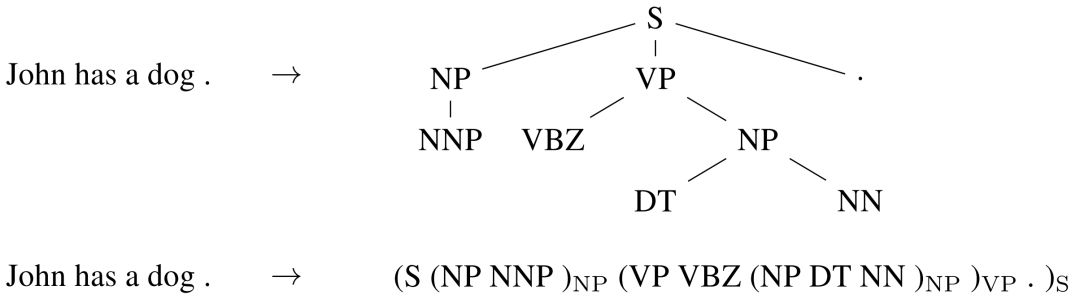
圖 10 | 線性化選區解析樹(Vinyalset al., 2015)
序列的編碼器和解碼器通常都是基於迴圈神經網路,但也可以使用其他模型。新的結構主要都從機器翻譯的工作中誕生,它已經成了序列到序列模型的培養基。近期提出的模型有深度長短期記憶網路、卷積編碼器、Transformer(一個基於自注意力機制的全新神經網路架構)以及長短期記憶依賴網路和的 Transformer 結合體等。
2015年——注意力機制
注意力機制是神經網路機器翻譯 (NMT) 的核心創新之一,也是使神經網路機器翻譯優於經典的基於短語的機器翻譯的關鍵。序列到序列學習的主要瓶頸是,需要將源序列的全部內容壓縮為固定大小的向量。注意力機制通過讓解碼器回顧源序列的隱藏狀態,以此為解碼器提供加權平均值的輸入來緩解這一問題,如圖 11 所示。
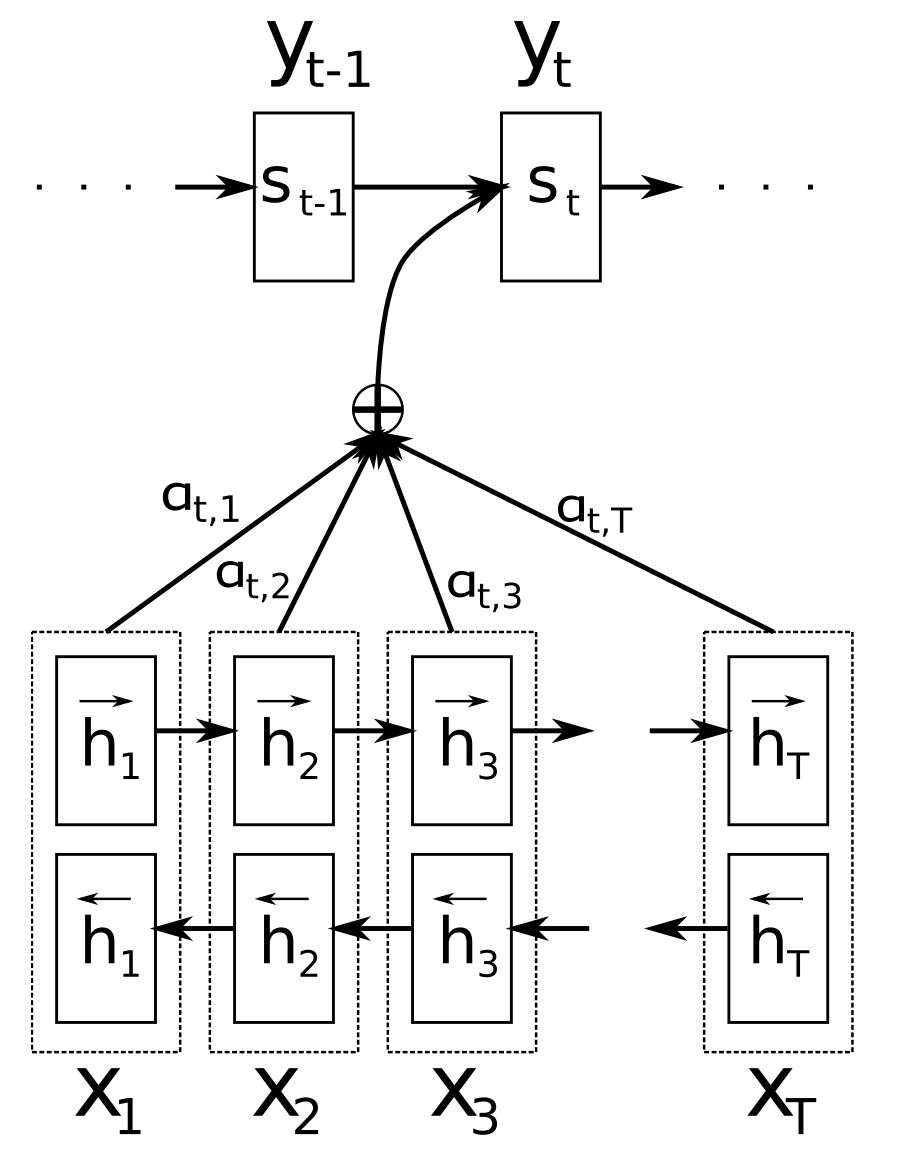
圖 11 | 注意力機制(Bahdanau et al., 2015)
之後,各種形式的注意力機制湧現而出。注意力機制被廣泛接受,在各種需要根據輸入的特定部分做出決策的任務上都有潛在的應用。它已經被應用於句法分析、閱讀理解、單樣本學習等任務中。它的輸入甚至不需要是一個序列,而可以包含其他表示,比如影象的描述(圖 12)。
注意力機制一個有用的附帶作用是它通過注意力權重來檢測輸入的哪一部分與特定的輸出相關,從而提供了一種罕見的雖然還是比較淺層次的,對模型內部運作機制的窺探。

圖 12 | 影象描述模型中的視覺注意力機制指示在生成”飛盤”時所關注的內容(Xu etal., 2015)
注意力機制也不僅僅侷限於輸入序列。自注意力機制可以用來觀察句子或文件中周圍的單詞,獲得包含更多上下文資訊的詞語表示。多層的自注意力機制是神經機器翻譯前沿模型 Transformer 的核心。
2015年——基於記憶的神經網路
注意力機制可以視為模糊記憶的一種形式,其記憶的內容包括模型之前的隱藏狀態,由模型選擇從記憶中檢索哪些內容。與此同時,更多具有明確記憶單元的模型被提出。他們有很多不同的變化形式,比如神經圖靈機(Neural Turing Machines)、記憶網路(Memory Network)、端到端的記憶網路(End-to-end Memory Newtorks)、動態記憶網路(DynamicMemory Networks)、神經可微計算機(Neural Differentiable Computer)、迴圈實體網路(RecurrentEntity Network)。
記憶的存取通常與注意力機制相似,基於與當前狀態且可以讀取和寫入。這些模型之間的差異體現在它們如何實現和利用儲存模組。比如說,端到端的記憶網路對輸入進行多次處理並更新記憶體,以實行多次推理。神經圖靈機也有一個基於位置的定址方式,使它們可以學習簡單的計算機程式,比如排序。基於記憶的模型通常用於需要長時間保留資訊的任務中,例如語言模型構建和閱讀理解。記憶模組的概念非常通用,知識庫和表格都可以作為記憶模組,記憶模組也可以基於輸入的全部或部分內容進行填充。
2018——預訓練的語言模型
預訓練的詞嵌入與上下文無關,僅用於初始化模型中的第一層。近幾個月以來,許多有監督的任務被用來預訓練神經網路。相比之下,語言模型只需要未標記的文字,因此其訓練可以擴充套件到數十億單詞的語料、新的領域、新的語言。預訓練的語言模型於 2015 年被首次提出,但直到最近它才被證明在大量不同型別的任務中均十分有效。語言模型嵌入可以作為目標模型中的特徵,或者根據具體任務進行調整。如下圖所示,語言模型嵌入為許多工的效果帶來了巨大的改進。
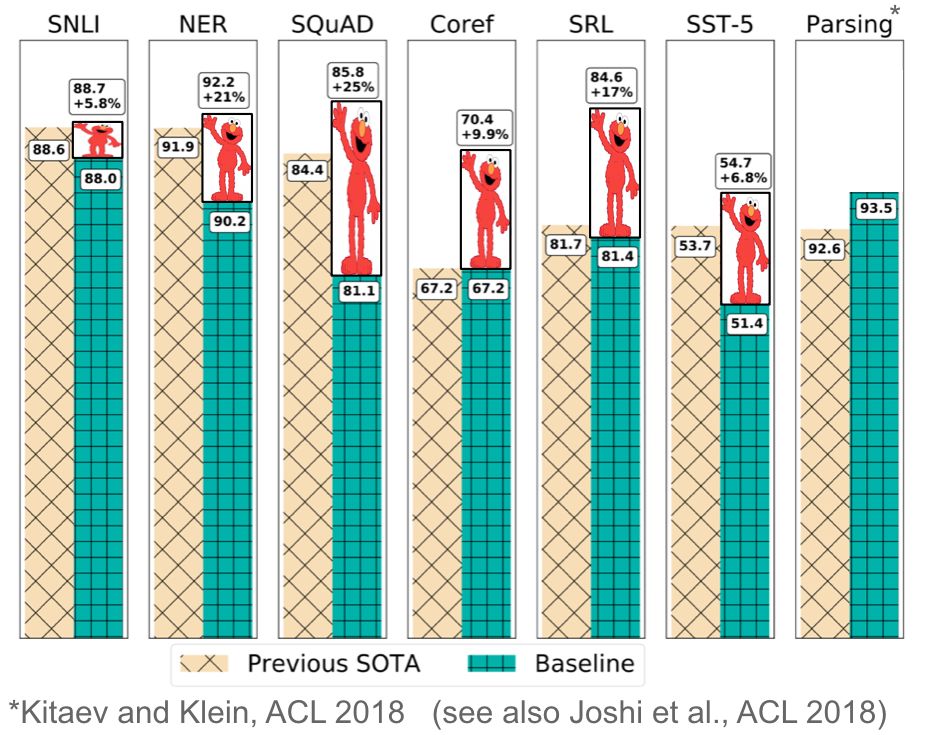
圖 13 | 改進的語言模型嵌入(Peterset al., 2018)
使用預訓練的語言模型可以在資料量十分少的情況下有效學習。由於語言模型的訓練只需要無標籤的資料,因此他們對於資料稀缺的低資源語言特別有利。
其他里程碑
一些其他進展雖不如上面提到的那樣流行,但仍產生了廣泛的影響。
基於字元的描述(Character-based representations)
在字元層級上使用卷積神經網路和長短期記憶網路,以獲得一個基於字元的詞語描述,目前已經相當常見了,特別是對於那些語言形態豐富的語種或那些形態資訊十分重要、包含許多未知單詞的任務。據目前所知,基於字元的描述最初用於序列標註,現在,基於字元的描述方法,減輕了必須以增加計算成本為代價建立固定詞彙表的問題,並使完全基於字元的機器翻譯的應用成為可能。
對抗學習(Adversarial learning)
對抗學習的方法在機器學習領域已經取得了廣泛應用,在自然語言處理領域也被應用於不同的任務中。對抗樣例的應用也日益廣泛,他們不僅僅是探測模型弱點的工具,更能使模型更具魯棒性(robust)。(虛擬的)對抗性訓練,也就是最壞情況的擾動,和域對抗性損失(domain-adversariallosses)都是可以使模型更具魯棒性的有效正則化方式。生成對抗網路 (GANs) 目前在自然語言生成任務上還不太有效,但在匹配分佈上十分有用。
強化學習(Reinforcement learning)
強化學習已經在具有時間依賴性的任務上證明了它的能力,比如在訓練期間選擇資料和對話建模。在機器翻譯和概括任務中,強化學習可以有效地直接優化”紅色”和”藍色”這樣不可微的度量,而不必去優化像交叉熵這樣的代理損失函式。同樣,逆向強化學習(inverse reinforcement learning)在類似視訊故事描述這樣的獎勵機制非常複雜且難以具體化的任務中,也非常有用。