
SPARK及其工作原理
阿新 • • 發佈:2018-12-16
文章目錄
什麼是Spark開發
1.核心開發:離線批處理 / 延遲性的互動式資料處理
2.SQL查詢:底層都是RDD和計算操作
3.實時計算:底層都是RDD和計算操作
Spark-RDD解釋
1.RDD是spark提供的核心抽象,全稱Resillient Distributed Dataset,彈性分散式資料集 2.RDD在抽象上來說是一種元素集合,包含了資料。它是被分割槽的,分為多個分割槽,每個分割槽分佈在叢集中的不同節點上,從而讓RDD中的資料可以被並行操作。(分散式資料集) 3.RDD通常通過Hadoop上的檔案,即HDFS檔案或者Hive表,來進行建立;有時也可以通過應用程式中的集合來建立。 4.RDD最重要的特性就是,提供了容錯性,可以自動從節點失敗中恢復過來。即如果某個節點上的RDD partition,因為節點故障,導致資料丟了,那麼RDD會自動通過自己的資料來源重新計算該partition。這一切對使用者是透明的。 5.RDD的資料預設情況下存放在記憶體中的,但是在記憶體資源不足時,Spark會自動將RDD資料寫入磁碟。(彈性)
RDD以及其特性
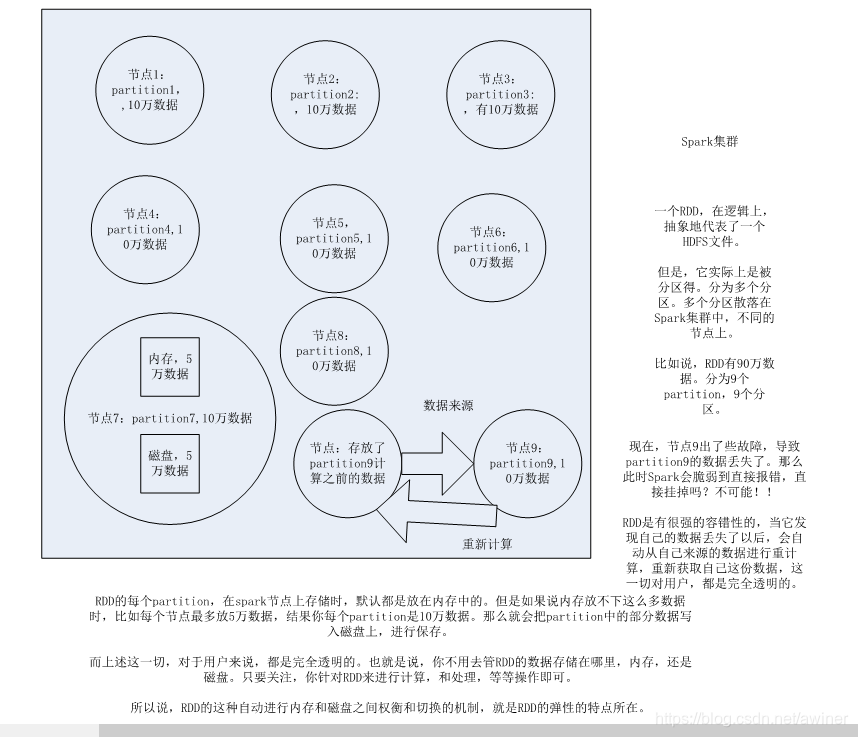
Spark基本工作原理
1.分散式
2.主要基於記憶體
3.迭代式計算
Spark基礎工作原理
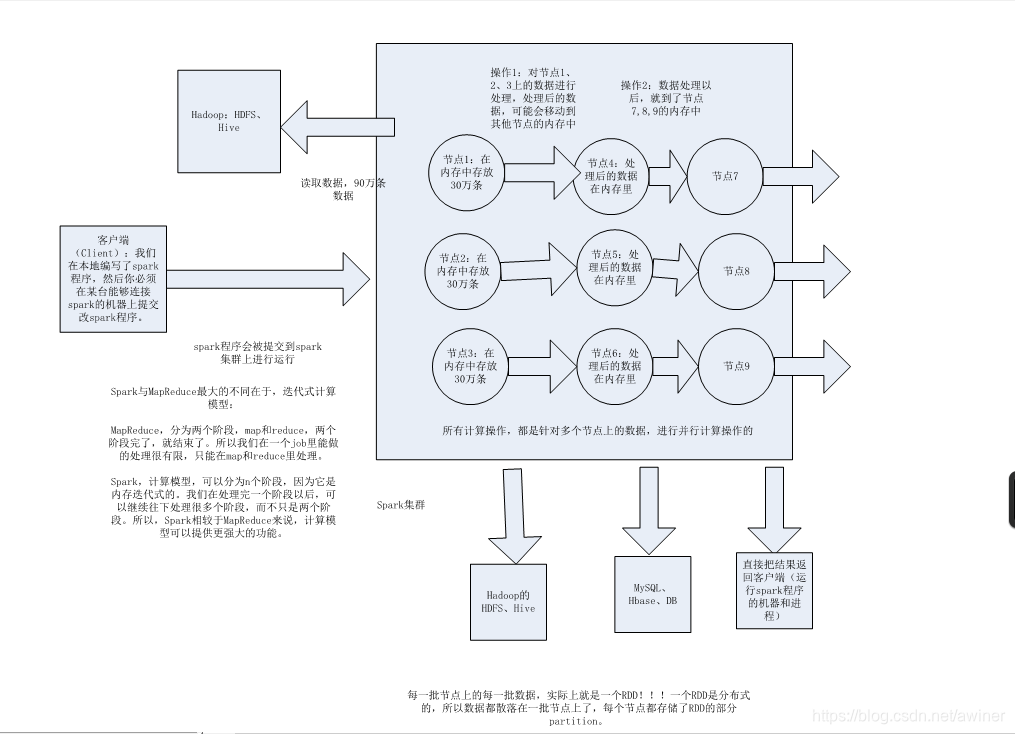
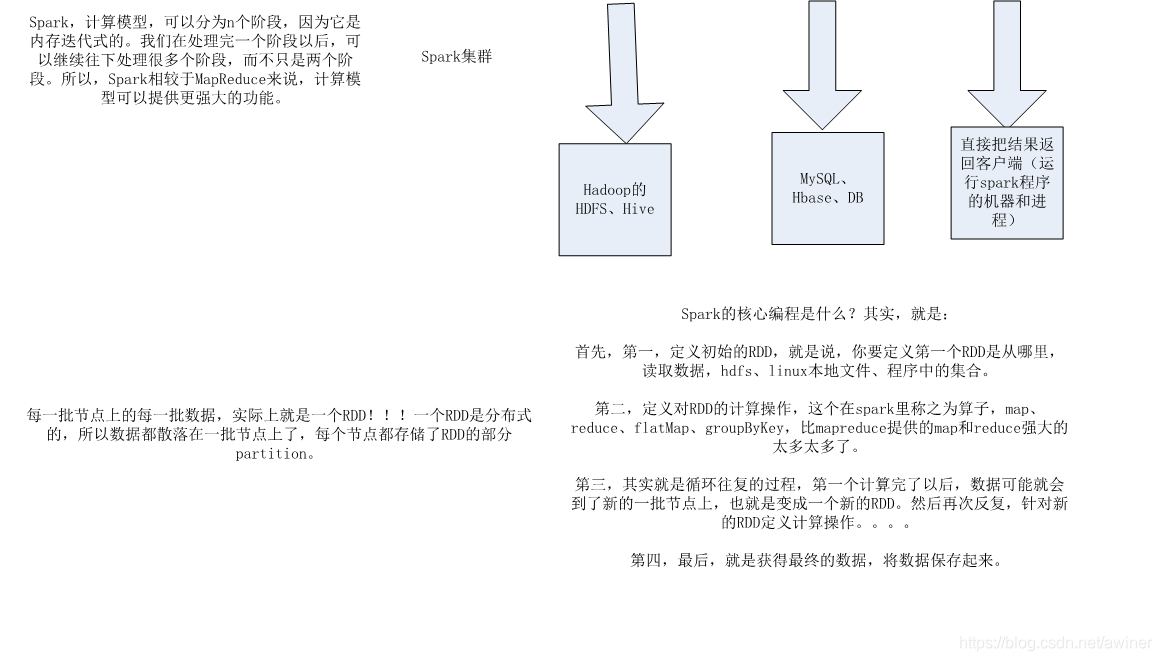
Spark核心工作原理
學習內容來自《北風網-中華石杉》