
Spark基本工作原理與RDD及wordcount程式例項和原理深度剖析
RDD以及其特點
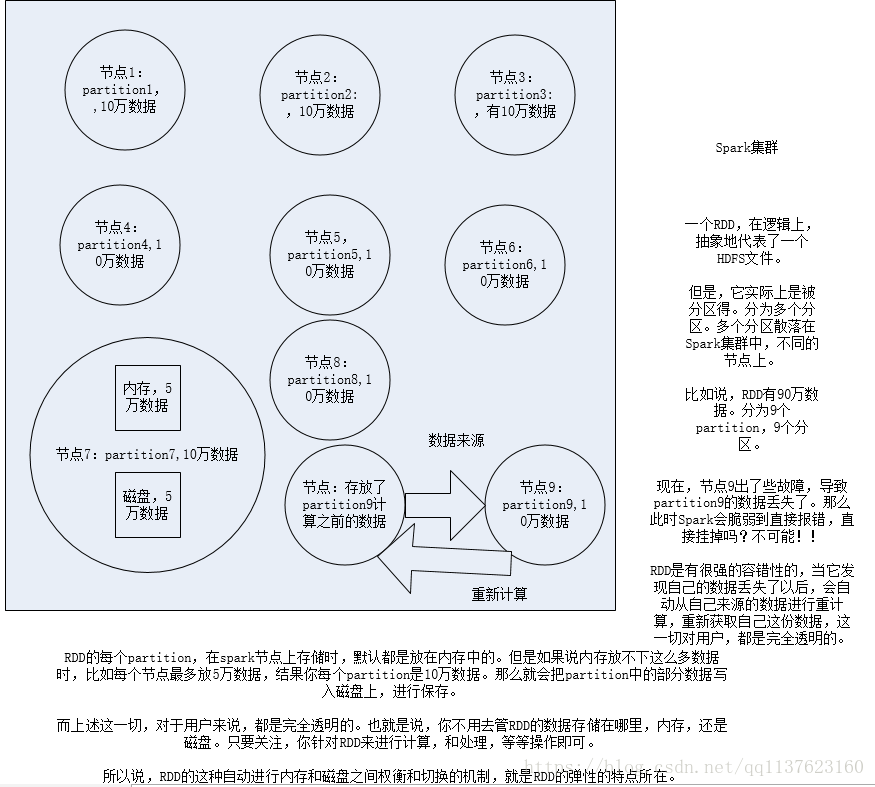
1、RDD是Spark提供的核心抽象,全稱為Resillient Distributed Dataset,即彈性分散式資料集。
2、RDD在抽象上來說是一種元素集合,包含了資料。它是被分割槽的,分為多個分割槽,每個分割槽分佈在叢集中的不同節點上,從而讓RDD中的資料可以被並行操作。(分散式資料集)
3、RDD通常通過Hadoop上的檔案,即HDFS檔案或者Hive表,來進行建立;有時也可以通過應用程式中的集合來建立。
4、RDD最重要的特性就是,提供了容錯性,可以自動從節點失敗中恢復過來。即如果某個節點上的RDD partition,因為節點故障,導致資料丟了,那麼RDD會自動通過自己的資料來源重新計算該partition。這一切對使用者是透明的。
5、RDD的資料預設情況下存放在記憶體中的,但是在記憶體資源不足時,Spark會自動將RDD資料寫入磁碟。(彈性)
RDD以及其特性
什麼是Spark開發?
1、核心開發:離線批處理 / 延遲性的互動式資料處理
2、SQL查詢:底層都是RDD和計算操作
3、實時計算:底層都是RDD和計算操作
Spark核心程式設計原理
開發wordcount程式
1、用Java開發wordcount程式
1.1 配置maven環境
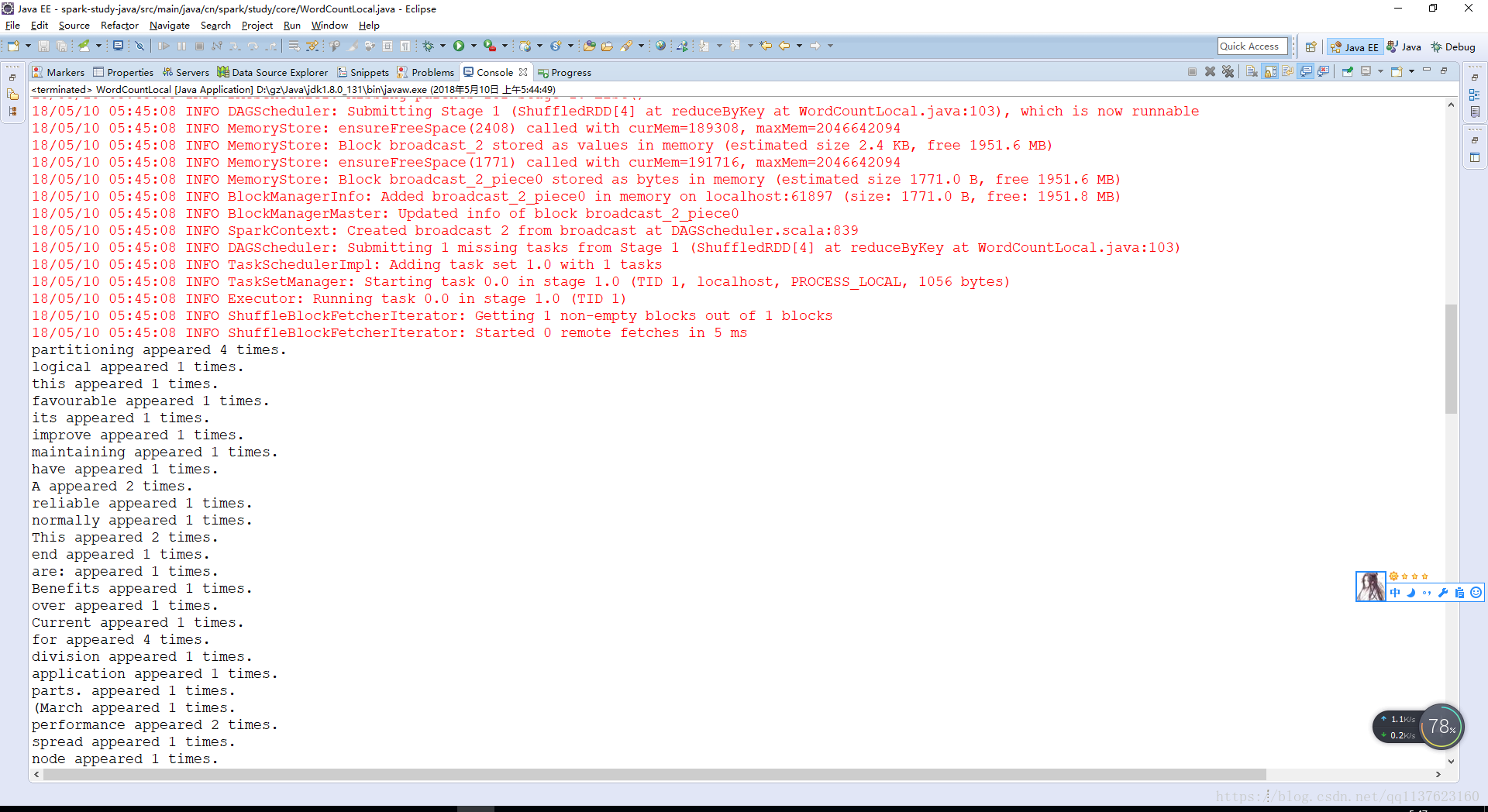
1.2 如何進行本地測試
1.3 如何使用spark-submit提交到spark叢集進行執行(spark-submit常用引數說明,spark-submit其實就類似於hadoop的hadoop jar命令)
pom.xml
<project 程式碼
package cn.spark.study.core;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
/**
* 使用java開發本地測試的wordcount程式
* @author Administrator
*
*/
public class WordCountLocal {
public static void main(String[] args) {
// 編寫Spark應用程式
// 本地執行,是可以執行在eclipse中的main方法中,執行的
// 第一步:建立SparkConf物件,設定Spark應用的配置資訊
// 使用setMaster()可以設定Spark應用程式要連線的Spark叢集的master節點的url
// 但是如果設定為local則代表,在本地執行
SparkConf conf = new SparkConf()
.setAppName("WordCountLocal")
.setMaster("local");
// 第二步:建立JavaSparkContext物件
// 在Spark中,SparkContext是Spark所有功能的一個入口,你無論是用java、scala,甚至是python編寫
// 都必須要有一個SparkContext,它的主要作用,包括初始化Spark應用程式所需的一些核心元件,包括
// 排程器(DAGSchedule、TaskScheduler),還會去到Spark Master節點上進行註冊,等等
// 一句話,SparkContext,是Spark應用中,可以說是最最重要的一個物件
// 但是呢,在Spark中,編寫不同型別的Spark應用程式,使用的SparkContext是不同的,如果使用scala,
// 使用的就是原生的SparkContext物件
// 但是如果使用Java,那麼就是JavaSparkContext物件
// 如果是開發Spark SQL程式,那麼就是SQLContext、HiveContext
// 如果是開發Spark Streaming程式,那麼就是它獨有的SparkContext
// 以此類推
JavaSparkContext sc = new JavaSparkContext(conf);
// 第三步:要針對輸入源(hdfs檔案、本地檔案,等等),建立一個初始的RDD
// 輸入源中的資料會打散,分配到RDD的每個partition中,從而形成一個初始的分散式的資料集
// 我們這裡呢,因為是本地測試,所以呢,就是針對本地檔案
// SparkContext中,用於根據檔案型別的輸入源建立RDD的方法,叫做textFile()方法
// 在Java中,建立的普通RDD,都叫做JavaRDD
// 在這裡呢,RDD中,有元素這種概念,如果是hdfs或者本地檔案呢,建立的RDD,每一個元素就相當於
// 是檔案裡的一行
JavaRDD<String> lines = sc.textFile("D://1.txt");
// 第四步:對初始RDD進行transformation操作,也就是一些計算操作
// 通常操作會通過建立function,並配合RDD的map、flatMap等運算元來執行
// function,通常,如果比較簡單,則建立指定Function的匿名內部類
// 但是如果function比較複雜,則會單獨建立一個類,作為實現這個function介面的類
// 先將每一行拆分成單個的單詞
// FlatMapFunction,有兩個泛型引數,分別代表了輸入和輸出型別
// 我們這裡呢,輸入肯定是String,因為是一行一行的文字,輸出,其實也是String,因為是每一行的文字
// 這裡先簡要介紹flatMap運算元的作用,其實就是,將RDD的一個元素,給拆分成一個或多個元素
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
// 接著,需要將每一個單詞,對映為(單詞, 1)的這種格式
// 因為只有這樣,後面才能根據單詞作為key,來進行每個單詞的出現次數的累加
// mapToPair,其實就是將每個元素,對映為一個(v1,v2)這樣的Tuple2型別的元素
// 如果大家還記得scala裡面講的tuple,那麼沒錯,這裡的tuple2就是scala型別,包含了兩個值
// mapToPair這個運算元,要求的是與PairFunction配合使用,第一個泛型引數代表了輸入型別
// 第二個和第三個泛型引數,代表的輸出的Tuple2的第一個值和第二個值的型別
// JavaPairRDD的兩個泛型引數,分別代表了tuple元素的第一個值和第二個值的型別
JavaPairRDD<String, Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
// 接著,需要以單詞作為key,統計每個單詞出現的次數
// 這裡要使用reduceByKey這個運算元,對每個key對應的value,都進行reduce操作
// 比如JavaPairRDD中有幾個元素,分別為(hello, 1) (hello, 1) (hello, 1) (world, 1)
// reduce操作,相當於是把第一個值和第二個值進行計算,然後再將結果與第三個值進行計算
// 比如這裡的hello,那麼就相當於是,首先是1 + 1 = 2,然後再將2 + 1 = 3
// 最後返回的JavaPairRDD中的元素,也是tuple,但是第一個值就是每個key,第二個值就是key的value
// reduce之後的結果,相當於就是每個單詞出現的次數
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 到這裡為止,我們通過幾個Spark運算元操作,已經統計出了單詞的次數
// 但是,之前我們使用的flatMap、mapToPair、reduceByKey這種操作,都叫做transformation操作
// 一個Spark應用中,光是有transformation操作,是不行的,是不會執行的,必須要有一種叫做action
// 接著,最後,可以使用一種叫做action操作的,比如說,foreach,來觸發程式的執行
wordCounts.foreach(new VoidFunction<Tuple2<String,Integer>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " appeared " + wordCount._2 + " times.");
}
});
sc.close();
}
}
叢集上執行、操作步驟和Scala差不多、可參考下面
2、用Scala開發wordcount程式
2.1 下載scala ide for eclipse
2.2 在Java Build Path中,新增spark依賴包(如果與scala ide for eclipse原生的scala版本發生衝突,則移除原生的scala / 重新配置scala compiler)
2.3 用export匯出scala spark工程
pom.xml同上
程式碼
package cn.spark.study.core;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
/**
* 將java開發的wordcount程式部署到spark叢集上執行
* @author Administrator
*
*/
public class WordCountCluster {
public static void main(String[] args) {
// 如果要在spark叢集上執行,需要修改的,只有兩個地方
// 第一,將SparkConf的setMaster()方法給刪掉,預設它自己會去連線
// 第二,我們針對的不是本地檔案了,修改為hadoop hdfs上的真正的儲存大資料的檔案
// 實際執行步驟:
// 1、將spark.txt檔案上傳到hdfs上去
// 2、使用我們最早在pom.xml裡配置的maven外掛,對spark工程進行打包
// 3、將打包後的spark工程jar包,上傳到機器上執行
// 4、編寫spark-submit指令碼
// 5、執行spark-submit指令碼,提交spark應用到叢集執行
SparkConf conf = new SparkConf()
.setAppName("WordCountCluster");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://eshop-cache01:9000/spark.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD<String, Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordCounts.foreach(new VoidFunction<Tuple2<String,Integer>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " appeared " + wordCount._2 + " times.");
}
});
sc.close();
}
}
wordcount.sh
/usr/local/spark/bin/spark-submit \
--class cn.spark.study.core.WordCount \
--num-executors 3 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 3 \
/usr/local/spark-study/scala/WordCount.jar \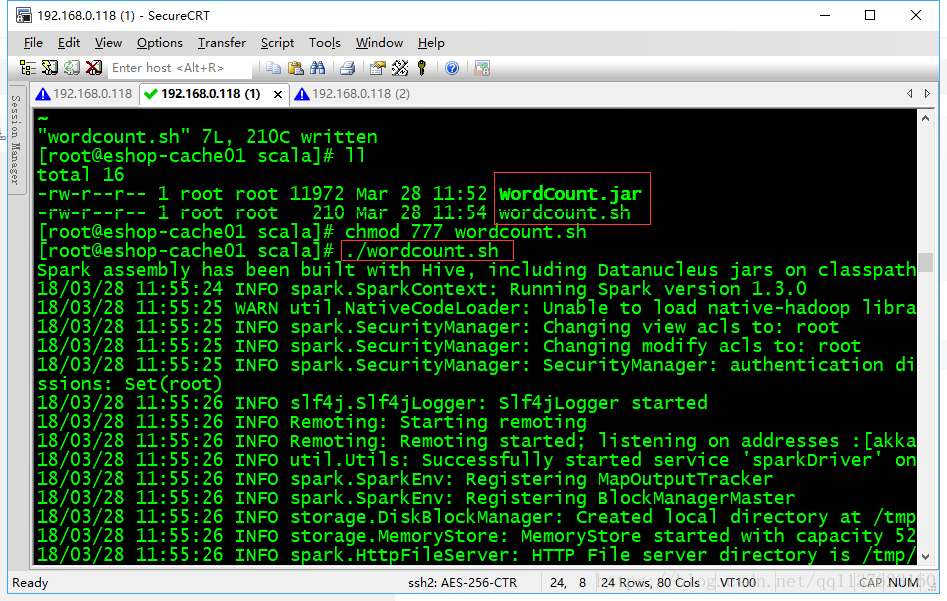
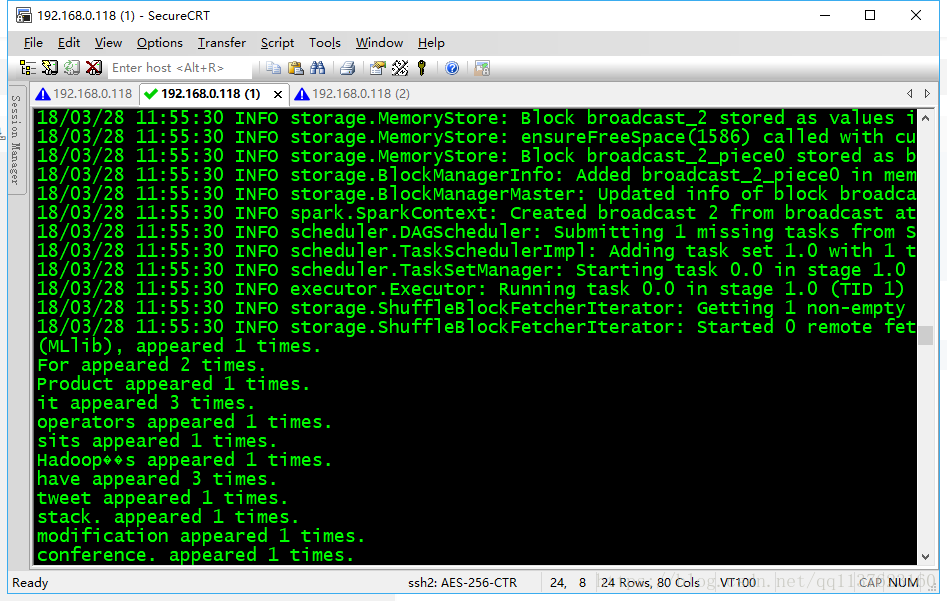
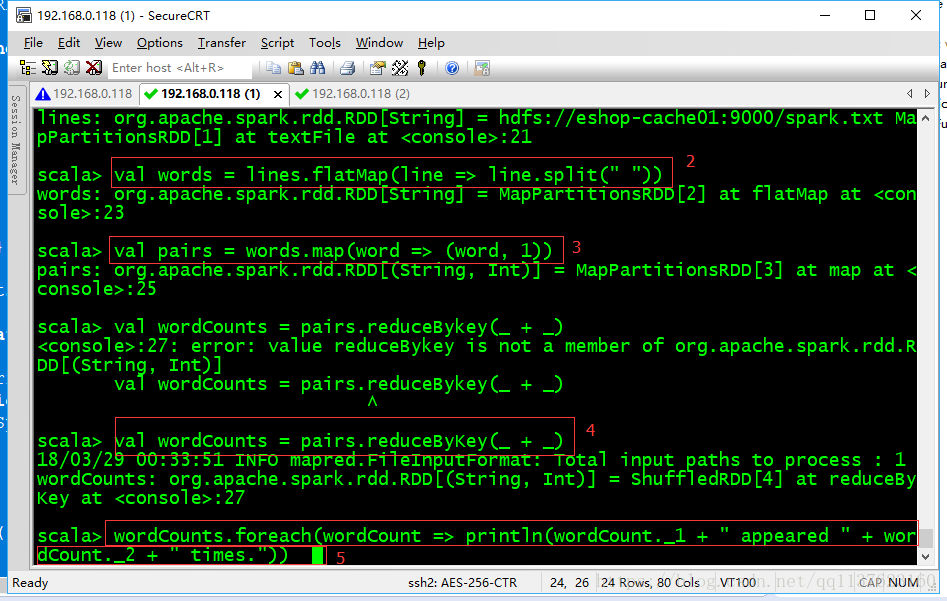
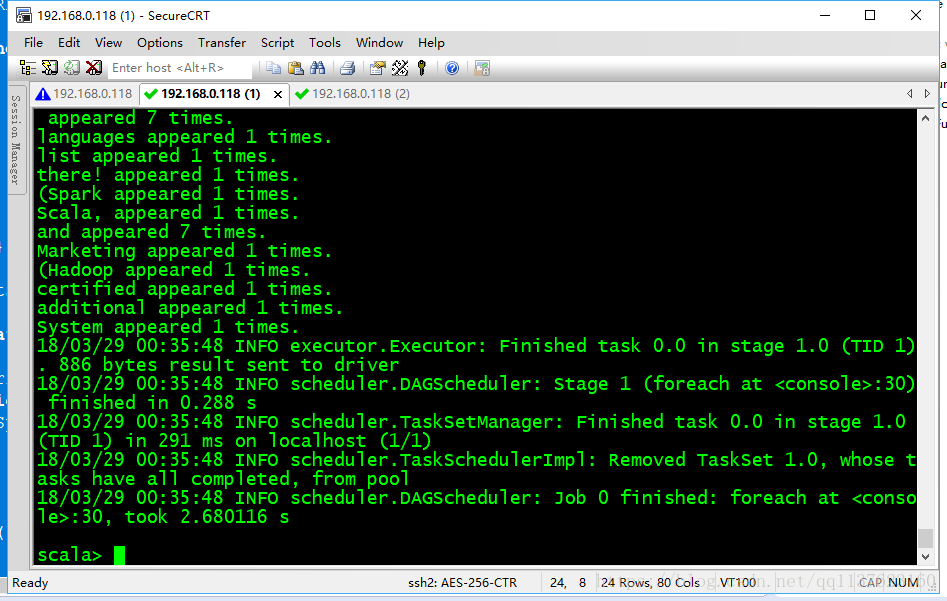
3、用spark-shell開發wordcount程式
3.1 常用於簡單的測試

wordcount程式原理深度剖析
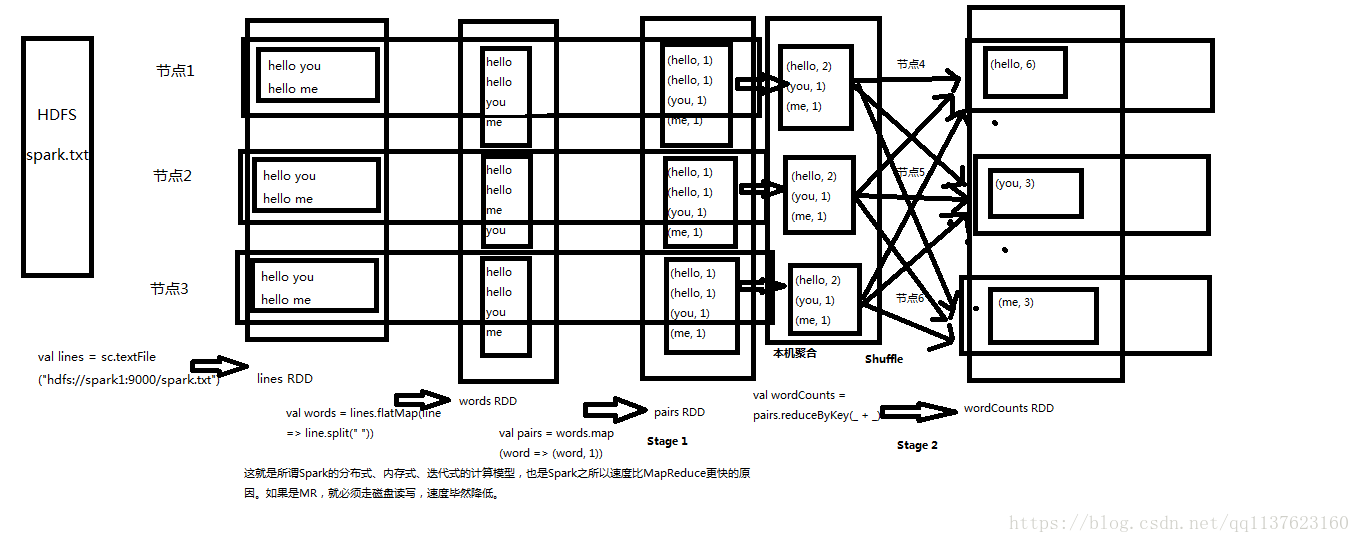
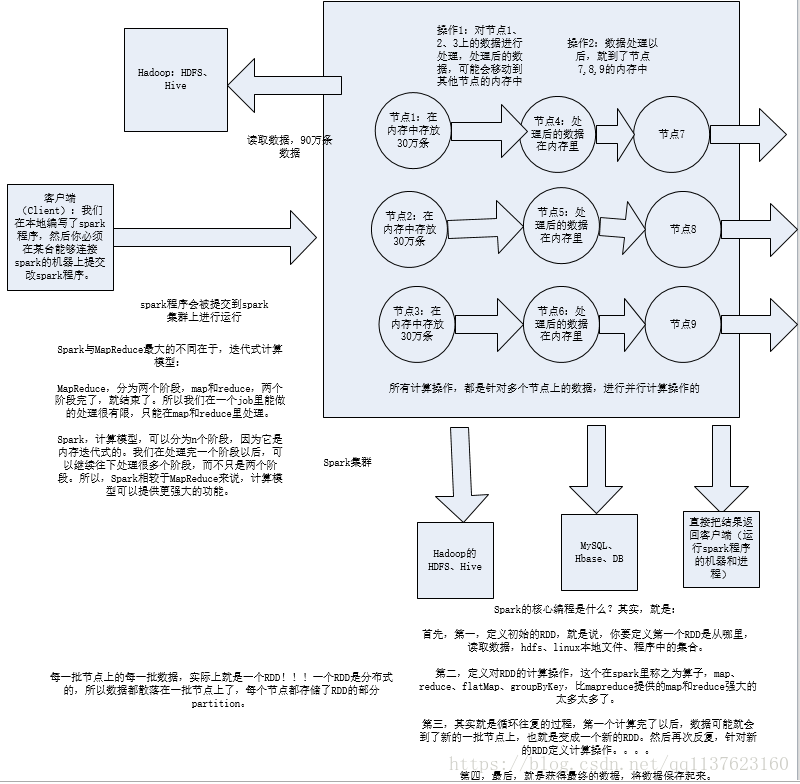
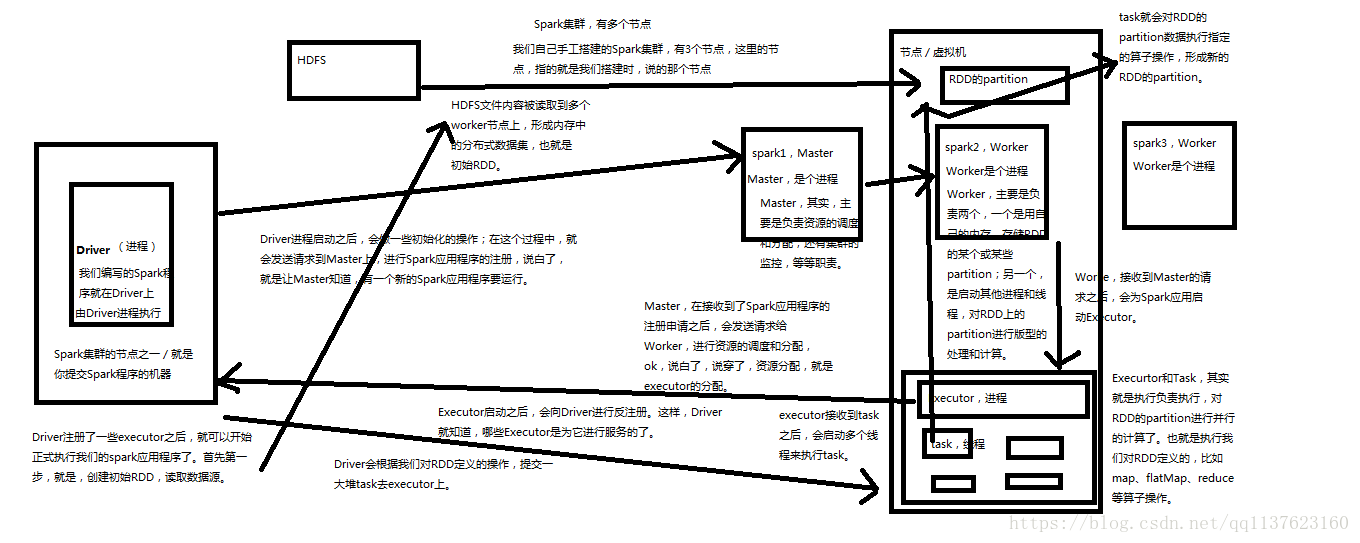
Spark架構原理
對於上面的wordcount程式在Spark各個元件的執行流程一個簡單的圖、詳細流程後面會有
相關推薦
Spark基本工作原理與RDD及wordcount程式例項和原理深度剖析
RDD以及其特點 1、RDD是Spark提供的核心抽象,全稱為Resillient Distributed Dataset,即彈性分散式資料集。 2、RDD在抽象上來說是一種元素集合,包含了資料。它是被分割槽的,分為多個分割槽,每個分割槽分佈在叢集中的不同節
spark核心程式設計,spark基本工作原理與RDD
Spark2.0筆記 spark核心程式設計,spark基本工作原理與RDD 1. Spark基本工作原理 2. RDD以及其特點 3. 什麼是Spark開發 1.Spark基本工作原理 2. RDD以及其特點 3. 什麼是Spark開發 spark核心程
Spark:基本工作原理與RDD
Spark的基本工作原理 我們從巨集觀講解Spark的基本工作原理,幫助你全面瞭解佈局 1、客戶端: 客戶端也就是專業們常說的Client端,這裡的是表示我們在本地編寫Spark程式,然後必須找一個能夠連線Spark叢集,並提交程式進行執行的機器 2、讀取資料: 在準備執行Sp
Spark基本工作流程及YARN cluster模式原理(讀書筆記)
Spark基本工作流程及YARN cluster模式原理 Spark基本工作流程 相關術語解釋 Spark應用程式相關的幾個術語: Worker:叢集中任何可以執行Application程式碼的節點,類似於YARN中的NodeManager節點。在Spark on Yarn模式中指的就是NodeMana
Spark- Spark基本工作原理
最大 取數 park spa 移動 工作 區別 bsp 行處理 Spark特點: 1.分布式 spark讀取數據時是把數據分布式存儲到各個節點內存中 2.主要基於內存(少數情況基於磁盤,如shuffle階段) 所有計算操作,都是針對多個節點上內存的數據,進行並行操作
spark基本組件與概念
維表 優化 shu 合成 dag 優勢 lib task hive 數據結構 核心之數據集RDD 俗稱為彈性分布式數據集。Resilient Distributed Datasets,意為容錯的、並行的數據結構,可以讓用戶顯式地將數據存儲到磁盤和內存中,並能控制數據的分區
路由器的基本原理與配置命令(靜態路由和默認路由)
路由技術 路由表 route命令 路由環路 楊書凡 路由器工作在OSI參考模型的網絡層,它的重要作用是為數據包選擇最佳路徑,最終送達目的地。那麽路由器是怎樣選擇路徑的呢?如果主機A要和主機B通信,就需要一種方法判斷源主機和目標主機所經過的最佳路徑,從而進行數據轉發,這就是路由技術。
探祕Dubbo原理與原始碼及實操
閱讀原始碼的作用 提取設計思路,增強設計能力 理解執行機制,便於快速解決問題以及功能擴充套件 常見有關dubbo的問題 dubbo的負載均衡是在哪個元件中處理的? dubbo預設的負載均衡演算法是什麼? 如果註冊中心掛掉了客戶端是否能夠繼續呼叫dubbo? 一個請求從
Python3 websocket server與client及javascript client通訊實現原理
WebSocket是HTML5開始提供的一種在單個 TCP 連線上進行全雙工通訊的協議。在WebSocket API中,瀏覽器和伺服器只需要做一個握手的動作,然後,瀏覽器和伺服器之間就形成了一條快速通道。兩者之間就直接可以資料互相傳送。瀏覽器通過 JavaScript 向伺服器發出建立 WebSocket 連
wine的工作原理與自動執行PE程式
一次偶然的情況,發現我電腦上的linux可以直接使用./來執行tools/vnd/BCM7584UPKFxBA/brcm_sign_enc.exe程式,但是另外一臺linux電腦就不可以。使用file命令檢視該檔案是windowsPE格式的程式。由於我電腦上有wine,猜測它
蒸妙集團:蒸妙燻蒸的中藥燻蒸原理與作用及燻蒸療法的好處
中藥燻蒸原理與作用 根據中醫理論,利用中醫中藥與現代高科技燻蒸器的完美結合,借熱力和藥力的雙向作用,實現“面板吃藥”的物理療
《微機原理與介面技術》第二章——微機原理(8088)
雖然寫這個部落格主要目的是為了給我自己做一個思路記憶錄,但是如果你恰好點了進來,那麼先對你說一聲歡迎。我並不是什麼大觸,只是一個菜菜的學生,如果您發現了什麼錯誤或者您對於某些地方有更好的意見,非常歡迎您的斧正! 目錄 第一章重點回顧: 第一節 8088 CPU的基本原理 第二節 80
《微機原理與介面技術》第一章——微機原理概述
雖然寫這個部落格主要目的是為了給我自己做一個思路記憶錄,但是如果你恰好點了進來,那麼先對你說一聲歡迎。我並不是什麼大觸,只是一個菜菜的學生,如果您發現了什麼錯誤或者您對於某些地方有更好的意見,非常歡迎您的斧正! 目錄 第1節 基本術語 第2節
10. LCD驅動程式 ——框架分析 第017課 LCD原理詳解及裸機程式分析 15.linux-LCD層次分析(詳解)
引言: 由LCD的硬體原理及操作(可參看韋哥部落格:第017課 LCD原理詳解及裸機程式分析) 我們知道只要LCD控制器的相關暫存器正確配置好,就可以在LCD面板上顯示framebuffer中的內容。 若應用程式需要在LCD螢幕上顯示文字或影象時,只需要把相應的顯示內容以正確的格式寫到Framebuff
網路通訊之 位元組序轉換原理與網路位元組序、大端和小端模式
原因如下:網路協議規定接收到得第一個位元組是高位元組,存放到低地址,所以傳送時會首先去低地址取資料的高位元組。小端模式的多位元組資料在存放時,低地址存放的是低位元組,而被髮送方網路協議函式傳送時會首先去低地址取資料(想要取高位元組,真正取得是低位元組),接收方網路協議函式接收時會將接收到的第一個位元
Hadoop HDFS 配置、格式化、啟動、基本使用Hadoop MapReduce配置、wordcount程式提交
Hadoop的安裝方式 單機:所有的服務執行在一個程序裡面,開發階段才會使用 分散式:將多個服務(JVM),分別執行在多臺機器上。 偽分散式:將多個服務(JVM)執行在一臺機器上 Hadoop偽分散式安裝 文件:http://hadoop.a
Python語句中基本的規則與特殊字元簡單操作例項
#coding=utf8 ''' Python語句中基本的規則與特殊字元: 1.井號(#)表示之後的字元為Python註釋 2.換行(\n)是標準的行分隔符(通常一個語句一行) 3.反斜線(\)繼續上
java基本資料型別與封裝型別詳解(int和Integer區別)
int是java提供的8種原始資料型別之一。 Java為每個原始型別提供了封裝類,Integer是java為int提供的封裝類(即Integer是一個java物件,而int只是一個基本資料型別)。int的預設值為0,而Integer的預設值為null,即Integer可以區
形象地展示訊號與系統中的一些細節和原理——卷積、複數、傅立葉變換、拉普拉斯變換、零極圖唯一確定因果LTI系統
看懂本文需要讀者具備一定的微積分基礎、至少開始學訊號與系統了本文主要講解尤拉公式、傅立葉變換的頻率軸的負半軸的意義、傅立葉變換的缺陷、為什麼因果LTI系統可以被零極圖幾乎唯一確定等等容易被初學者忽略但對深入理解非常重要的細節問題本文秉承儘量直觀的原則,儘量少用純數學推導,而多用形象直觀的物理意義、幾何意義、舉
一個工作三年左右的Java程式設計師和大家談談從業心得
轉發連結地址:https://mp.weixin.qq.com/s/SSh9HcA5PgMHv7xiolQkig 貌似這一點適應的行業最廣,但是我可以很肯定的說:當你從事web開發一年後,重新找工作時,才會真實的感受到這句話。 工作第一年,往往是什麼都充滿新鮮感,什麼