
Linux效能優化大師-系統優化漫談
目錄
Linux效能度量標準
處理器度量標準
1.CPU使用率
2.使用者程序消耗CPU的時間
3.核心操作消耗CPU的時間,包括IRQ和softirq時間
4.等待,等待上的時間總量,比如io等
5.CPU空閒時間
6.nice消耗CPU時間
7.平均負載,正在處理的程序和不可中斷程序綜合的平均值
8.可執行的程序,可執行的程序數量不應超過處理器數量的10倍
9.阻塞的程序
10.上下文切換
11.中斷
記憶體度量標準
1.空閒記憶體,從已使用used的記憶體中減去緩衝buffer和快取cache的記憶體數量即空閒的
2.使用的swap,需要關注in和out的值,每秒200-300換入換出就有瓶頸了
3.Slab,核心使用的記憶體數,核心的分頁不能移出磁碟
4.活躍和非活躍記憶體,非活躍記憶體可能是kswapd守護程序swap out到磁碟的候選者
塊裝置度量標準
1.I/O等待
2.平均佇列長度,未完成的I/O請求數量,磁碟有2-3個佇列是最佳的
3.平均等待時間,服務一個IO請求所測量的平均時間
4.每秒傳輸,每秒鐘多少個I/O操作被執行(讀和寫)
5.每秒讀取/寫入塊的數量
6.每秒讀取/寫入的位元組
網路介面度量標準
1.接收和傳送的資料包
2.接收和傳送的位元組
3.每秒鐘衝突的數量,如果持續衝突則要關注網路基礎設施而不是伺服器
4.丟棄的資料包
5.溢位,網路介面溢位緩衝區空間的次數,集合資料包被丟棄的值使用,來確定網路緩衝區或是網路
佇列長度出現瓶頸
6.錯誤,通常是網路不匹配或是網路電纜中斷導致的
瞭解系統的硬體配置
CPU
1.CPU(S)模式是什麼,處理器的架構是哪一個,使用什麼主機板晶片?
2.有多少個插口,每個CPU有多少核心?如果支援超執行緒那麼每個核心上有多少執行緒,每個插口socket如何連線
的,資料速率是多少 QPI HyperTransport FBS
3.CPU的每個層級的cache有多大,cache是核心私有的還是與socket上的其他核心共享的,或者與一個系統中
其他socket共享的,cache是如何被組織和訪問的?
4.處理器支援哪些特徵,處理器支援硬體虛擬化嗎,處理器的架構是32bit還是64bit?是否有其他的特殊
指令或者功能?
記憶體
1.系統有多少記憶體?硬體允許的最大數量的記憶體是多少?
2.系統使用的記憶體技術是什麼?它有什麼頻寬和延遲?
3.系統的記憶體是如何被連線的,榮國一個Northbridge和前端匯流排或者直接接到CPU,是SMP或NUMA嗎?
如果是NUMA節點使用什麼技術,當訪問不用漁區的記憶體時會有什麼影響
儲存
1.附加在系統上的儲存裝置是什麼型別的,實際裝置是什麼模型?他們是基於旋轉的磁碟片的傳統硬體,
還是固態硬體solid-state diskSSD驅動器?
2.傳統的硬碟,它們有沒有定址時間和旋轉延遲?你期待的最大化頻寬和延遲是多少,訪問驅動器不同
分割槽的速度變化是多少?
3.SSD驅動器,他們使用的快閃記憶體是MLC還是SLC?他們支援TRIM嗎,如何有效的對他們的耐久性和垃圾收集
系統進行測量?
4.磁碟陣列,已使用的硬體RAID級別是什麼?在一個陣列裡有多少個儲存裝置?RAID級別是條帶,在
陣列中每個條帶的大小是多少?
5.直連式儲存使用什麼進行互連SATA,SAS或其他,他是怎麼連線主機板到系統的其他部分呢,是否有充足的
頻寬讓所有的裝置支援通訊的連線?
6.SAN裝置,使用Fibre Channel或者iSCSI越過乙太網?SAN裝置的頻寬和延遲是多少?多路徑SAN裝置,
基於可用路徑的效能變化幾何?
網路
1.系統上可用的網路介面卡是什麼?使用的網路技術是什麼?(乙太網,無限頻寬技術等)?
2.對機器來說什麼網路是可用的或需要的?什麼是VLAN?如何大量利用這些網路?他們有特殊用途
嗎(儲存網路,帶外管理等)?他們運轉的速度是多少?
3.我們需要特別的能力嗎(列如I/O虛擬化可以將一個網絡卡劃分成多少vNIC作為系統上的guest虛擬機器)?
一些系統命令
通過檢視dmesg緩衝區
1.回顧啟動時的硬體檢測
2.觀察顯示出的硬體連線或檢測的資訊
3.觀察顯示出的警告或錯誤情況發生的資訊
當前dmesg緩衝區的內容到/var/log/dmesg中
lscpu -p 檢視cache的共享資訊
x86inifo 命令
檢視機器硬體相關資訊的命令 dmidecode
這些資訊再 /sys/class/dmi/id 中
chkconfig 檢測守護程序資訊
service 啟動/停止守護程序
SELinux
Security Enhanced Linux,引入強制訪問策略模式克服了linux使用的標準自主訪問模式的侷限性
在使用者和程序級別上強制安全性,所以任何特定程序的安全漏洞,隻影響分配給這個程序的資源,而不是整個系統
SELinux必須控制I/O是被,檢查許可權過程中會導致10%的開銷
編輯grub.conf檔案禁用SELinux
或者編輯/etc/selinux/config禁用
SELINUX=disabled
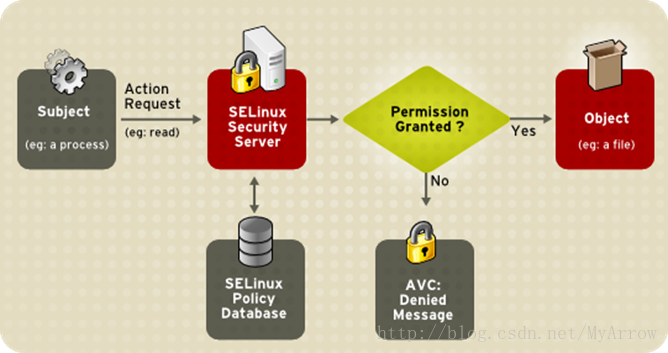
proc目錄
1.數字1-X,執行的程序各自pid的目錄
2.Acpi,現代桌面和筆記本系統支援的高階配置和電源介面
3.bus,綜合子系統的資訊,比如PCI匯流排或各自系統的USB介面
3.irq,中斷相關的資訊
4.scsi,各自系統的SCSI子系統資訊
5.sys,可調整的核心引數,比如虛擬記憶體管理器或網路協議棧的行為
6.tty,虛擬中斷和連線的物理裝置的資訊
/proc/sys/abi, 包含檔案與應用程式二進位制資訊
/proc/sys/debug
/proc/sys/dev, 特定裝置的資訊
/proc/sys/fs, 特定的檔案系統,檔案控制代碼,inode,dentry和配額調優
/proc/sys/kernel,用來控制核心的引數
/proc/sys/net, 核心網路部分的調整
/proc/sys/vm, 內管管理調優,包括buffer和cache管理等
通過 sysctl 命令也可以調整引數
調整處理器子系統
chrt 命令用來調整程序的排程策略
nice和renice 調整程序的執行級別,從19(最底優先順序) 到 -20(最高優先順序)
taskset 設定程序的CPU親和力
cgroup
cpuset.cpus 在cgroup中可以使用的CPU,可以是一個範圍
cpuset.mems,可以使用哪一個NUMA記憶體區域
cpuset.{cpu,memory}+exclusive,如果希望這個cgroup中的CPU/記憶體是獨有的可設定為1
中斷interrupt
這是一個來自硬體或者軟體的資訊
中斷有時候被稱為IRQ interrupt request
/proc/interrupts 描述了再一個特定的CPU上處理特定的中斷情況
確定核心在哪個CPU上執行特定的中斷處理程式,可以檢視/proc/irq/number/smp_affinity 掩碼檔案
NUMA系統
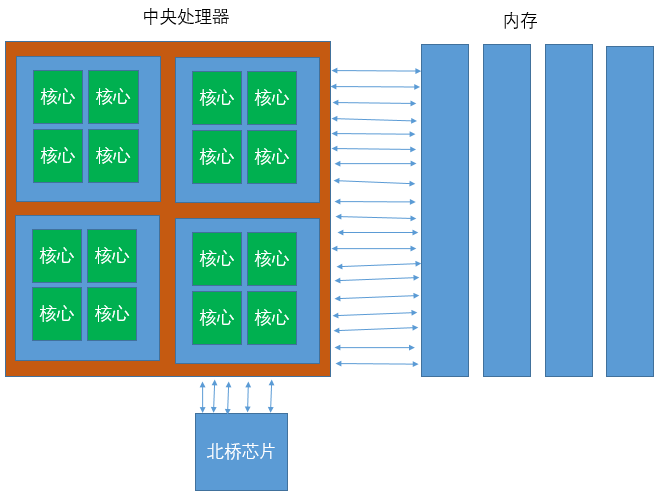
最早的多處理器系統是就對稱多處理器結構 Symmetric Multiprocessing SMP 設計的
每個CPU核心通過一個共享匯流排訪問系統RAM
這就是一個統一的記憶體架構 Uniform Memory Architecture UMA系統
隨著處理器增多這種系統就會出現瓶頸,下圖是SMP系統的架構圖
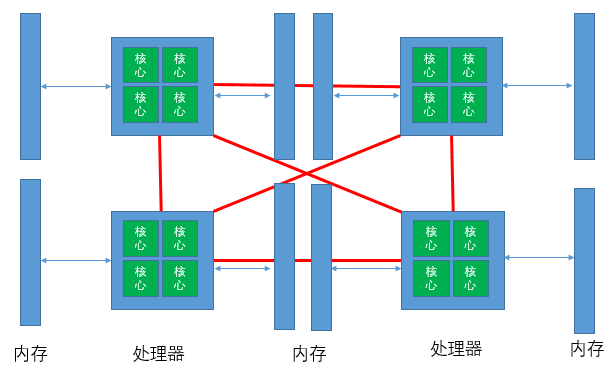
Non Uniform Memory Architecture NUMA 非統一記憶體架構
這些基於NUMA系統的主儲存器通過單獨的匯流排直接連線到單獨的處理器或CPU封裝
numastat 工具用於識別NUMA架構中處理困難的程序
/sys/devices/system/node/%{node_number}/numastat 檔案中可以看到 numastat工具所提供的統計資料
另一個命令 numactl
調整記憶體子系統
大多數應用程式不會直接寫入硬碟,他們通過虛擬記憶體寫入到檔案系統cache,最終將資料刷新出來
實體記憶體需要時不時被回收,以防止記憶體填滿導致系統不可用
記憶體分頁狀態
| Free | 分頁是有效的,可立刻分配 |
| Inactive Clean | 分頁沒有活躍使用,內容符合磁碟上的內容,因為它已經被寫回或自讀以來沒有改變 |
| Inactive Dirty | 分頁沒有活躍使用,但是自從磁碟上讀依賴分頁內容已經被修改,還沒有被寫回 |
| Active | 分頁在活躍使用中,並不能作為一個可釋放的候選者 |
對於每個程序的檢視可以檢視 /proc/PID/smaps,這個檔案描述了分配給一個程序的每個記憶體段,包含了Shared/Private clean大小,髒資料記憶體大小等當需要分配一個新的分頁的時候,分頁被標記為Inactive clean,即可以被視為空閒分頁,但如果擁有該分頁的程序之後再次需要分頁,將會發生一個主要頁錯誤(major page fault)
通過檢視/proc/meminfo 可以得到整個系統的記憶體分配概況,我們關注的是Inactive(file)和Dirty
Anonymous page(那些與磁碟上的檔案不相關的)不能輕易釋放,並且需要換出到磁碟釋放他們
相關髒資料核心引數
| vm.dirty_expire_centisecs | 經過多久(百分之一秒)髒資料才有資格寫入到磁碟,防止僅僅因為程序修改了記憶體的一個位元組,而導致核心快速連續的對相同分頁進行多次寫 |
| vm.dirty_writeback_centisecs | 核心多長時間喚醒flush執行緒來一次寫入資料,設定0將完全禁用週期的寫回 |
| vm.dirty_background_ratio | 髒資料達到系統總記憶體百分比,核心開始在後臺寫資料 |
| vm.dirty_ratio | 一個程序所擁有的臧姝達到系統總記憶體的百分比,該程序產生寫阻塞,並寫出髒頁 |
/proc/PID/maps和/proc/PID/smaps都是關於程序記憶體段對映資訊的
當記憶體不足時候 OOM killer會決定殺死哪個程序,每個程序都有一個執行不良分數
對應的是/proc/PID/oom_score 檔案
有許多因素來計算這個分數,虛擬記憶體大小,程序包括所有子程序積累的虛擬記憶體大小,nice值,總共執行時間,執行的使用者等
init對OOM killer是免疫的
可以呼叫/procPID/oom_adj 來調整 oom_score,最高是-17,最低是15
echo f > /proc/sysrq-trigger 會至少殺死一個程序,資訊輸出到 dmesg中
當核心想釋放記憶體中的一個分頁時,有兩種選擇
1.從程序的記憶體中換出一個分頁
2.從分頁cache中丟棄一個分頁
記憶體計算方式如下
swap_tendency = mapped_ratio/2 + distress + vm_swappiness
如果swap_tendency低於100核心將從分頁cache中回收一個分頁
如果大於等於100,一個程序記憶體空間中的一部分將有資格獲得交換
調整vm.swappiness可能會影響效能
mapped_ratio是實體記憶體使用的百分比,distress是衡量核心在釋放記憶體中有多少開銷
/proc/sys/vm/swappines 中的引數可以用來定於如何 將記憶體交換到磁碟上
機械硬碟應該避免過多交換,SSD可以多使用交換,但注意避免被頻繁的寫,以免寫入放大
可以使用mkswap將磁碟上的空閒分割槽建立為一個swap分頁,如果磁碟子系統沒有空閒可用,可以建立一個swap檔案
有限建立swap分割槽,這樣I/O就繞過了檔案系統和所有涉及寫入一個檔案的開銷,mkswap 命令建立swap分割槽
可以建立多個swap分割槽,並行讀取提高效能
cat /etc/fstab
swap空間分配參考
| 系統實體記憶體 | 建議最小swap空間 |
| 4G以內 | 至少2G |
| 4G-16G | 至少4G |
| 16G-64G | 至少8G |
| 64G-256G | 至少16G |
在分頁表中有一個虛擬地址到實體地址的對映,這個轉換是由一個專門的硬體完成的,叫TLB
CPU的旁路轉換緩衝(Translation Lookaside Buffer)TLB是一個很小的cache,用來儲存虛擬地址到實體地址的對映資訊,但他的大小是固定的,更大的分頁使得的TLB可以裝下更多的對映條目
通過下面命令檢視系統的TLB資訊
x86info -a
通過/proc/meminfo檢視大分頁相關的資訊
調整hugepage引數
/proc/sys/vm/nr_hugepages
通過命令調整
sysctl -w vm.nr_hugepage=512
新的Linux支援動態調整巨型分頁
/sys/kernel/mm/redhat_transparent_hugepage/enabled
記憶體同頁合併
通過後來程序將一些完全相同的分頁到一個分頁中,安裝KSM服務並配置
調整磁碟子系統
一旦作業系統的cache和磁碟子系統的cache不能再容納讀/寫請求的大小或數量,物理量磁碟就必須工作
假設一個磁碟驅動器每秒能處理200個I/O,有一個應用程式,在檔案系統上執行4KB的隨機位置寫請求,因此不能
選擇流或請求合併,最大的吞吐量是
200 * 4KB = 800KB
Linux分割槽和伺服器環境
| 分割槽 | 內容和可能的伺服器環境 |
| /home | 分理出home到自己的分割槽對於檔案伺服器有好處,這是系統上所有使用者的根目錄,如果沒有實現磁碟配額,那麼分離這個目錄是為了隔離使用者對磁碟空間的失控使用 |
| /tmp | 如果在高效能運算環境中執行,那麼在計算時需要大量的臨時空間,然後完成釋放 |
| /usr | 這是防止核心原始碼樹和Linux文件的位置,/usr/local目錄儲存的可執行檔案必須可以被系統上的所有使用者訪問,並且是一個很好的位置用來儲存為你環境開發的自定義指令碼,如果他被分離到他自己的分割槽,那麼在升級或重新安裝時通過簡單的選擇不需要重新格式化的分割槽,檔案不會被重新安裝 |
| /var | 在郵件,網站,列印伺服器環境中非常重要,他保護了這些環境的日誌檔案和整個系統的日誌,長期的訊息可以填滿這個分割槽,如果發生這種情況,並且此分割槽沒有從/ 中分離出來,則伺服器可能會中斷,根據不同的環境,可能要進一步分離這個分割槽,做法是在郵件伺服器上分離出/var/spool/mail,或相關係統日誌的/var/log |
| /opt | 安裝的一些第三方軟體,如Oracle資料庫伺服器預設使用這個分割槽,如果沒有分離,安裝將在/ 下繼續,如果不能分配足夠的空間,可能會失敗 |
4種I/O排程演算法相關的核心引數
| /sys/block/sda/queue/nr_requests | 磁碟佇列長度。預設只有 128 個佇列,可以提高到 512 個.會更加佔用記憶體 ,但能更加多的合併讀寫操作,速度變慢,但能讀寫更加多的量 |
| /sys/block/sda/queue/read_ahead_kb | 這個引數對順序讀非常有用,意思是,一次提前讀多少內容 |
| /proc/sys/vm/dirty_ratio | 這個引數控制檔案系統的檔案系統寫緩衝區的大小,單位是百分比,表示系統記憶體的百分比,表示當寫緩衝使用到系統記憶體多少的時候,開始向磁碟寫出數 |
| /proc/sys/vm/dirty_background_ratio | 這個引數控制檔案系統的pdflush程序,在何時重新整理磁碟.單位是百分比,表示系統記憶體的百分比,意思是當寫緩衝 使用到系統記憶體多少的時候,pdflush開始寫磁碟 |
| /proc/sys/vm/dirty_writeback_centisecs | 這個引數控制核心的髒資料重新整理程序pdflush的執行間隔.單位是 1/100 秒.預設數值是500,也就是 5 秒 |
| /proc/sys/vm/dirty_expire_centisecs | 這個引數宣告Linux核心寫緩衝區裡面的資料多“舊”了之後,pdflush程序就開始考慮寫到磁碟中去.單位是 1/100秒.預設是 30000,也就是 30 秒的資料就算舊了,將會重新整理磁碟 |
使用 ionice 命令分配I/O優先順序,支援3種優先順序
1.Idle,分配給I/O優先順序為idle的程序,只有在沒有其他Best-effort(盡力而為)或更高優先順序的程序請求
訪問資料時,才給其授權訪問磁碟子系統,這個設定對於人物非常有幫助,尤其當系統有空閒資源的時候
2.Best-effort,預設所有不要求特定I/O優先順序的程序被分配到這一類,程序將繼承他們各自的CPU的nice
優先順序為8到I/O優先順序
3.Real time,最高可以I/O優先順序是realtime,這意味著程序各自將總在給定優先順序下訪問磁碟子系統,
real time優先順序也可以設定優先級別為8,應小心適應,當給其分配一個執行緒real_time優先順序的時候,這個
程序可能導致其他任務等待
訪問時間也是一個開銷,但禁用檔案訪問更新只會產生一個非常小的系統性能提升
使用noatime選項掛在檔案系統防止訪問時被封信
選擇日誌檔案模式
data=journal,這個模式將檔案資料和元資料全部記錄到日誌中,有最高一致性但開銷也高
data=ordered(default),這個模式只記錄元資料,但保證檔案資料先被寫入
data=writeback,提供最快的資料訪問,但系統崩潰後可能出現數據不一致
通過mount命令可以修改
或者修改/etc/fstab 檔案
預設的塊大小是4KB
如果伺服器處理大量小檔案,那麼小塊將有效
如果是處理大量的大檔案,則較大的塊能提高效能
需要重新格式化後才能改變當前塊大小,根據測試改變塊大小提升效能並不大
虛擬化儲存
調整網路子系統
網路子系統會影響到其他子系統
如果資料包太小,CPU使用率會受到明顯的影響
如果有過多的TCP連線,記憶體使用會增加
網路繫結
通過使用bonding驅動程式,核心提供網路介面聚合的能力,這是一個與裝置不相關的bonding驅動程式
可以實現負載均衡和容錯,實現了更高層次的可用性和效能改善
支援模式
1.balance-rr,使用bond中所有的網絡卡,提供容錯並基本負載均衡
2.active-backup,僅使用bond中的一個網絡卡,當活躍當地網絡卡出故障時,另外網絡卡接管
巨幀
一個普通的TCP連線使用的協議報頭是40位元組,預設的MTU是1500位元組,有2.7%的容量損失
切換到UDP模式,報頭從40減到28,容量損失是1.9%
有些裝置可能不支援巨型幀
官方巨型幀最大是9000位元組
40位元組報頭,9000位元組MTU,容量損失是0.44%
速度與雙工模式
網路吞吐量依賴於很多因素,使用的網絡卡,佈線的型別,在一次連線中的跳數,傳送的包大小
提高網路效能最簡單的方法之一是檢測網路介面的實際速度,因為問題可能在網路元件(比如交換機)和網路介面卡之間
通過命令
ethtool eth0 檢查
增加網路緩衝區
| 基於系統記憶體自動計算出初始的整個tcp記憶體 | /proc/sys/net/ipv4/tcp_mem |
| 設定接收socket的記憶體預設值和最大值到一個更高的值 | /proc/sys/net/core/rmem_default /proc/sys/net/core/rmem_max |
| 設定傳送socket的記憶體預設值和最大值搞一個更高的值 | /proc/sys/net/core/wmem_default /proc/sys/net/core/wmem_max |
| 調整記憶體buffers的最大值搞一個更高的值 | /proc/sys/net/core/optmem_max |
調整頻寬延遲乘積 BDP(bandwidth delay product)
BDP = Bandwidth(bytes/sec) * Delay(or round trip time) (sec)
假設ping的往返延遲是10.509ms=0.010594s,假設網路速度是1Gb/s
1Gb/s * 10.509ms = 10^9b/s * 0.0105094s = 10594000 bits * 1/8 B/b
= 1324250Bytes = 1294.21KB
設定作業系統對於多個協議佇列最大發送buffer大小wmem和接受buffer大小rmem
增加允許未處理資料包的數量
cat /proc/sys/net/core/netdev_max_backlog
增加傳輸佇列長度,可以通過ip 命令調整
配置offload
一些網路操作可以從網路介面裝置offload,使用
ethtool -k eth0檢視
offload會使得CPU使用率降低,網路會計算大資料包的校驗和
但網絡卡開啟了offload之後對網絡卡本身也有影響,處理的資料包能力會下降
Netfilter對效能的影響
Netfilter提供TCP/IP連線跟蹤和資料包過濾功能,在某些情況下可能產生較大的ing能影響
尤其是當連線建立的時候數量較高的時候
Netfilter的效能影響取決於以下因素
1.規則的數量
2.規則的順序
3.規則的複雜性
4.連線跟蹤級別(取決於協議)
5.Netfilter核心引數配置
流量特性的注意事項
網路效能優化最重要的考慮因素之一是要儘可能準確的瞭解網路流量模式
效能變化取決於網路流量特徵
應該熟悉以下網路流量特徵和要求
1.事務吞吐量的要求(峰值,平均值)
2.資料傳輸吞吐量的要求(峰值,平均值)
3.延遲的要求
4.傳輸資料的大小
5.傳送和接受的比例
6.連線建立和關閉的頻率或併發連線的數量
7.協議(TCP,UDP,應用程式協議,如HTTP,SMTP,LDAP等)
使用netstat,ss,tcpdump,wireshark分析
調整IP和ICMP行為
1.禁用引數,防止黑客針對伺服器的IP地址進行欺騙攻擊
2.忽略來自閘道器機器的重定向
3.不接受任何ICMP重定向,ICMP重定向是路由器傳達路由資訊到主機的一種機制
4.如果主機不充當路由器就不必傳送重定向可以禁用
5.忽略廣播ping和smurf攻擊
6.忽略所有icmp型別的資料包或ping包
7.忽略無效的廣播幀
8.設定IP碎片的最大和最小記憶體,碎片會被放到記憶體中被重新組裝
調整TCP行為
1.對於WEB付我錢,TIME-WAIT 可以被連線重新使用
2.伺服器關閉socket時,tcp_fin_timetou引數設定在FIN_WAIT-2狀態下儲存socket的時間
3.減小keepalive的時間
4.調整backlog佇列大小
5.啟動TCP SYN cookies
調整TCP選項
1.對於區域網可以禁用tcp_sack和tcp_dsack
2.每一個乙太網幀被轉發到核心網路堆疊時,會接受一個時間戳,對時間不敏感的服務可以禁用這個時間戳
3.視窗縮放可以是擴大傳輸視窗的一個選項,但系統遇到非常高的負載時視窗縮放不合適,可以禁用或手動調整
限制資源使用
如何通過最簡單的設定來實現最有效的效能調優,如何在有限資源的條件下保證程式的執行,限制某些使用者或程序訪問資源,對效能優化來說就成為了很有用的策略
使用 ulimit命令限制資源
通過ulimit -a檢視能限制的資源和資源當前狀態
通過pam_limits.so 資源限制模組,並修改 /etc/security/limits.conf 檔案
CGroup
Control Group提供一種機制將任務(程序)和子任務(子程序)聚合/劃分到有特定行為的層次組中,在控制器中細分資源(如CPU時間,記憶體,磁碟I/O等),再層次化地分開
cgroup也是LXC為實現虛擬化所使用的資源管理手段,沒有cgroup就沒有LXC
cgroup針對一個或多個子系統將一組任務與一組引數關聯在一起
子系統是一個模組,利用cgroup提供的任務分組功能以特定的方式視其為任務組,子系統通過是一個資源控制器,排程一個資源或按cgroup應用限制,他可能是想要作用於程序租上的任何事,如一個虛擬化子系統
所謂層次結構就是以樹形結構對一組cgroup進行分組,這樣系統中的每個人物將正確的位於層次結構中的其中一個cgroup和一組子系統,在層次結構中每個子系統將特定的系統狀態附加到每個cgroup中,每個層次結構都有一個cgroup虛擬檔案系統的例項與其相結合
cgroup子系統
| Blkio | 對塊裝置的I/O進行控制 |
| Cpu | 用來控制程序排程,設定程序佔用CPU資源(時間片)的比重 |
| cpuacct | 使用cgroups分組任務,並統計這些任務的CPU使用 |
| Cpuset | 提供了為一組任務分配一組CPU和記憶體節點的機制 |
| devices | 實現了跟蹤和執行open和mknod裝置檔案的限制 |
| freezer | 對於批處理作業管理是很有用的,可以根據管理員的需求啟動和停止任務,從而排程機器的資源 |
| Memory | 隔離並限制程序租對記憶體資源的使用 |
| net_cls | 使用類登機識符(classid)標記網路資料包,可使用流量控制器TC 為來自不同cgroups的資料包分配不同的優先順序 |
相互關係
1.每次在系統中穿件新層次結構時,該系統中的所有任務都是該層次結構的預設cgroup,稱之為root cgroup,此cgroup在建立層次結構時自動建立,後面在該層次結構中建立的cgroup都是此cgroup的後代
2.一個子系統最多隻能附加到一個層次結構
3.一個層次結構可以附加到多個子系統
4.一個任務可以是多個cgourp的成員,但是這些cgroup必須在不同的層次結構
5.當系統中的程序(任務)建立子程序(任務)時,該子任務自動成為其父程序所在cgroup的成員,然後可以根據需要將該子任務移動到不同的cgroup中,但開始時他總是繼承其父任務的cgroup
使用cgcreate建立cgroups
使用mkdir建立cgroup,通過rmdir或cgdelete移出
使用mount掛在一個虛擬cgroups檔案系統
在/etc/cgconfig.conf中配置cgconfig建立cgroup層次結構
為cgroup設定限制
給cgroup分配程序
參考
Linux NUMA引發的效能問題?linux上swap的檢視與調整
linux下檢視硬碟資訊、硬碟分割槽、格式化、掛載、及swap分割槽
Linux IO Scheduler(Linux IO 排程器)